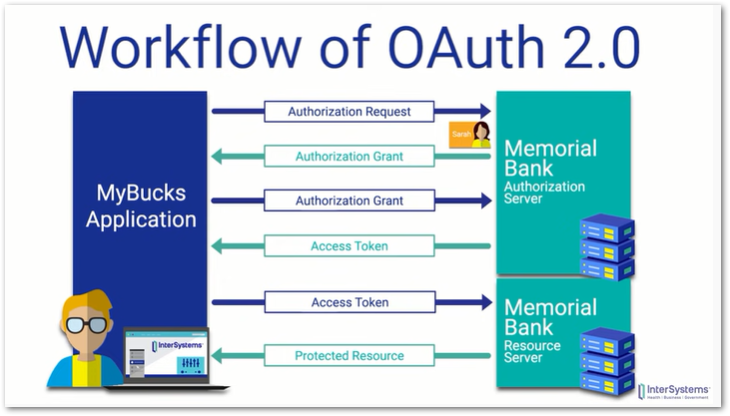
Picking up from last time, I continued on with the Strava API Getting Started page and got myself very confused over how things were supposed to work. The Strava API requires authentication via OAuth 2.0, and in fairness Strava includes a graph that shows how the process works which unfortunately went right over my head. By chance I found a YouTube video produced by InterSystems Learning Services that gave me a good entry-level understanding of the process, boiling down to this slide:
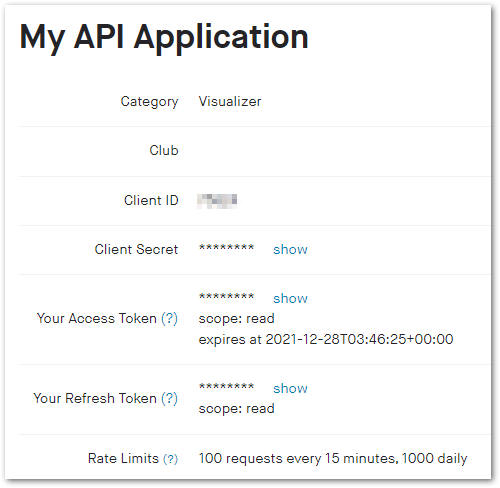
As it turned out I was misunderstanding the purpose of the access token Strava was giving me on the My API Application page. That access token wasn’t provided by OAuth and so couldn’t be used to get any data – instead I needed to use Strava’s OAuth API to request different credentials and define a scope for the access needed.
To that end, Strava provides this link on their Getting Started page:
http://www.strava.com/oauth/authorize?client_id=[REPLACE_WITH_YOUR_CLIENT_ID]&response_type=code&redirect_uri=http://localhost/exchange_token&approval_prompt=force&scope=readWhich was used in conjunction with my app’s ClientID to get an authorization code in the form of:
http://localhost/exchange_token?state=&code=MYAUTHCODE123456789&scope=readNext, a cURL request must be made to exchange the authorization code and scope for a refresh token, access token, and access token expiration date. The page suggests https://www.strava.com/oauth/token which turns out to be wrong – the URL used in the Authentication documentation for this is https://www.strava.com/api/v3/oauth/token. At this point I was having varying success with Postman, so instead installed REST Client on Visual Studio Code on the advice of Vu Long Tran’s blog which made things much simpler.
Sending a request of:
curl -X POST https://www.strava.com/api/v3/oauth/token
-d client_id=ReplaceWithClientID \
-d client_secret=ReplaceWithClientSecret \
-d code=ReplaceWithCode \
-d grant_type=authorization_code\Produced a response containing my Strava profile data along with new tokens and details of their expiry:
"token_type": "Bearer"
"expires_at": 1640810729,
"expires_in": 4002,
"refresh_token": REFRESHTOKEN123456789
"access_token": "ACCESSTOKEN123456789"Awesome! Now to put these to work…
Part of my confusion coming into this was that I had been given a Python script in my travels that I was expecting to work with the access token from the My API Application screen, which of course with the benefit of hindsight was never going to be successful. The Python script is as follows:
import requests
activities_url = "https://www.strava.com/api/v3/athlete/activities"
header = {'Authorization': 'Bearer ' + "access_token"}
param = {'per_page': 200, 'page': 1}
my_dataset = requests.get(activities_url, headers=header, params=param).json()
print(my_dataset)Time to test it out with the new access token! Straight into a problem:
{'message': 'Authorization Error', 'errors': [{'resource': 'Athlete', 'field': 'access_token', 'code': 'invalid'}]}The Strava API and SDK Reference page was quick to indicate the source of the problem:
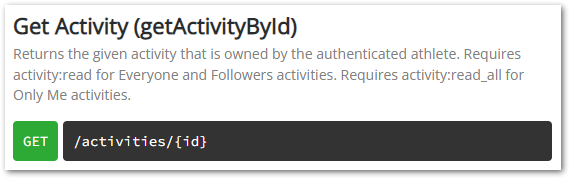
The previous requests to Strava’s OAuth API were with scope=read. I changed this to scope=activity:read_all and received a new authorization code with the updated scope. This authorization code was then exchanged for a new access token which, when pasted into the Python script, outputted so much JSON that in the interests of sanity I’ve screenshotted a small section for illustration:

To be fair it was what I asked for. And it all makes a bit more sense to me now!
Future plans for this involve making use of the refresh tokens to automate access token generation (assuming I’ve understood that part correctly – stay tuned!) and getting some working code into a Lambda function so I can start turning some cogs in AWS.
Thanks for reading ~~^~~