In this post, I respond to January 2024’s T-SQL Tuesday #170 Invitation by examining amazonwebshark’s abandoned 2019 AWS architecture.
Table of Contents
Introduction
amazonwebshark is two years old today!

I wrote an analysis post last year, and when deciding on the second birthday’s topic I saw this month’s T-SQL Tuesday invitation from Reitse Eskens:
“What projects did you abandon but learn a lot from?”
One immediately sprang to mind! Since this T-SQL Tuesday falls on amazonwebshark’s second birthday, it seemed a good time to evaluate it.
Rewind to 2019. I was new to AWS and was studying towards their Certified Cloud Practitioner certification. To that end, I set up an AWS account and tried several tutorials including an S3 static website.
After earning the certification, I kept the site going to continue my learning journey. I made the site into a blog and chose a snappy (Groan – Ed) name…amazonwebshark. In fact, that site is still around!
I’ll start by looking at the site architecture, then examine what went wrong and end with how it influenced the current amazonwebshark site. For the rest of this post, I’ll refer to amazonwebshark 2019 as awshark2019 and the current version as awshark2021.
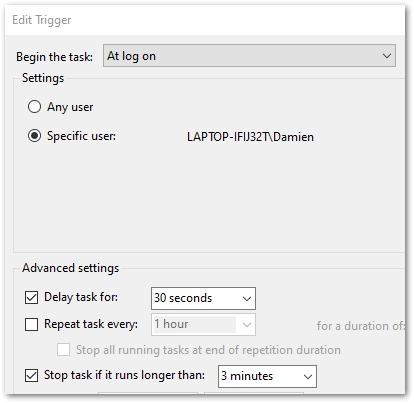
How awshark2019 Was Built
In this section, I examine the architecture behind awshark2019.
Hugo Static Site Generator
Hugo is an open-source static site generator written in the Go programming language. Go is known for its efficiency and performance, making Hugo’s build process very fast.
Hugo’s content files are written in Markdown which enables easy post creation and formatting. These Markdown posts are then converted to static HTML files at build time. The built site has a file system structure and can be deployed to platforms like traditional web servers, content delivery networks (CDNs), and cloud storage services.
Speaking of which…
S3 Static Site
awshark2019 has been operating out of a public S3 bucket since its creation:

This won’t be a particularly technical section, as the AWS documentation and tutorial are already great resources for this S3 feature. So let’s talk about the benefits of static sites instead:
- Since static websites consist of pre-built HTML, CSS, and JavaScript files, they load quickly and can scale rapidly.
- Static websites are inherently more secure and maintainable because there’s no server-side code execution, database vulnerabilities or plugin updates.
- All site processing is done before deployment, so the only ongoing cost is for storage. awshark2019 weighs in at around 4MB, so in the four years it has been live this has been essentially free.
So far this all sounds good. What went wrong?
Why awshark2019 Failed
In this section, I examine awshark2019’s problems. Why was the 2019 architecture abandoned?
Unclear Objectives
Firstly, awshark2019 had no clear purpose.
In my experience, good blogs have their purpose nailed down. It could be automation, data, biscuits…anything as long as it becomes consistent and plays to the creator’s strengths.
With awshark2019, some posts are about S3 Static Sites and Billing Alerts. These are good topics to explore. However, almost half of the posts are about creating the site and are in a web design category. But the blog isn’t about web design, and I’ve never been a web designer!
Rounding things off, the About page is…the Hugo default. So who is the site for? If I, as the blog creator, don’t know that then what chance does anyone else have?
Poor Content
Secondly, as awshark2019’s objectives were unclear the content was…not very good. The topic choices are disjointed, some of the posts are accidental documentation rehashes and ultimately there’s little value.
Let’s take the example of Adding An Elastic IP To An Amazon Linux EC2 Instance. The post explores the basics, shows the AWS console changes and mentions costs. This is fine, but there’s not much else here. If I wrote this post today, I’d define a proper use case and explore the problem more by pinging the instance’s IP before and after a stoppage. This shows the problem instead of telling it.
Another post examines Setting Up A Second AWS Account With AWS Organizations. There’s more here than the IP address post, but there’s no context. What am I doing with the second account? Why does my use case support the use of AWS Organisations? What problems is it helping me solve?
There’s nothing in these posts that I can’t get from the AWS documentation and no new insights for readers.
Awkward To Publish
Finally, awshark2019 was too complex to publish. More accurately, Hugo’s deployment process wasn’t the problem. The way I was doing it was.
Hugo sites can be deployed in several ways. These centre around putting files and folders in a location accessible by the deployment service. So far so good.
But instead of automating this process, I had a horrible manual workflow of creating and testing the site locally, and then manually overwriting the existing S3 objects. This quickly got so tedious that I eventually ran out of enthusiasm.
What I Learned
In this section, I examine what I learned from the abandoned 2019 architecture when creating awshark2021.
Decide On Scope
My first key awshark2021 decision was the blog’s purpose.
While ‘Welcome To My Blog’ posts are something of a cliche, I took the time to write Introducing amazonwebshark as a standard to hold myself to:
By writing about my experiences I can check and confirm my understanding of new topics, give myself points of reference for future projects and exam revision, evidence my development where necessary and help myself out in the moments when my imposter syndrome sees an opportunity to strike.
Introducting amazonwebshark: What Is amazonwebshark For?
awshark2021 took as much admin away as possible, letting me explore topics and my curiosity instead. amazonwebshark was, and is, a place for me to:
- Try things
- Make mistakes
- Improve myself
- Be creative
While this is firstly a technology and cloud computing blog, I allow myself some freedom (for example the Me category) as long as the outcome is potentially useful. To this end, I’ve also written about life goals, problem-solving and public speaking.
Add Value
Secondly, let’s examine the posts themselves.
I probably average about eight hours of writing per post. I want to get the most out of that time investment, so I try to ensure my posts add value to their subject matter. There’s no set process for this, as value can take many forms like:
- Examining how I apply services to my situation or use case.
- Raising awareness of topics with low coverage.
- Detailing surprising or unexpected event handling.
My attitude has always been that I’m not here to tell people how and why to do things. I’m here to tell people how and why I did things. Through this process, I can potentially help others in the technology community while also helping myself.
Post introspection and feedback have led to improvements in my working practises like:
- Improving SQL code readability with CTEs.
- Avoiding sensitive variable disclosure with AWS Parameter Store.
- Preventing code duplication with Object Oriented Programming.
It could be argued that amazonwebshark is a big ongoing peer review. It’s made me a better engineer and has hopefully helped others out too.
Keep It Simple
Finally, let’s discuss architecture.
awshark2021 is a WordPress blog, currently hosted on Hostinger servers. While this architecture isn’t free and has tradeoffs, it offers a fast, reliable deployment path managed by organisations specialising in this field.
This is exactly what I wanted for awshark2021:
…my main focus was to get the ball rolling and get something online. I’ve wanted to start a blog for some time, but have run into problems like knowledge gaps, time pressures and running out of enthusiasm.
Introducing amazonwebshark: Why Didn’t You Use AWS For Hosting?
I enjoy writing, so my priority is there. If I begin seriously considering a serverless amazonwebshark, one of the core tests will be the deployment process. For now, the managed services I’m paying for meet my needs and let me focus on creativity over admin.
Summary
In this post, I responded to January 2024’s T-SQL Tuesday #170 Invitation by examining amazonwebshark’s abandoned 2019 AWS architecture.
It’s unfair to blame the architecture. Rather, my implementation of it was at fault. awshark2019 was a good idea but suffered from poor and over-ambitious architectural decisions. I’ve considered deleting it. But if nothing else it reminds me of a few things:
- I won’t always get it right first time.
- It doesn’t have to be perfect.
- Enjoy the process.
awshark2019’s lessons have allowed awshark2021 to reach two years. Happy birthday!
If this post has been useful, the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~