In this post, I create my WordPress data pipeline’s Silver ETL process using Python and the AWS Glue ETL Job Script Editor.
Table of Contents
- Introduction
- Glue ETL Job Script Editor
- Architecture
- Silver ETL Job
- Uploading & Testing
- Costs
- Summary
Introduction
Last time I worked on my WordPress AWS data pipeline, I produced my Bronze layer data and created a Glue Crawler to derive the schema of the Bronze S3 objects. It’s now time to start cleaning that data to prepare it for reporting, aggregation and consumption.
I’m also currently studying for the AWS Certified Data Engineer – Associate certification. While revising for this I learned the capabilities of the AWS Glue ETL Job Script Editor, and it seemed an ideal fit for my Silver ETL process. So I decided to make a post out of it and see how things went!
Firstly, I’ll examine the AWS Glue ETL Job Script Editor and how it will benefit my Silver ETL process. Then I’ll define the architecture of the Silver ETL job and how it fits into the existing data pipeline. Next, I’ll script and test the job. Finally, I’ll integrate it into the pipeline and explore the job’s costs.
Glue ETL Job Script Editor
This section examines the AWS Glue ETL Script Editor and Python Shell and considers some of Python Shell’s benefits and limitations.
Script Editor & Python Shell
Script Editor is a feature of AWS Glue. It offers serverless Spark, Ray and Python shells, enabling data transformation, preparation and cleaning with no infrastructure management. Scripts can be both uploaded and created from scratch, and version control is configurable to several Git services.
This post focuses on AWS Glue Python Shell. Introduced in 2019, Python Shell jobs suit small to medium-sized tasks as part of an ETL workflow.
Python Shell Pros
This section examines some of Python Shell’s benefits.
Low Cost
Python Shell jobs are the cheapest of the Glue job types to run. Glue charges are based on data processing units (DPUs). A single standard DPU currently provides 4 vCPU and 16 GB of memory. While regular Glue ETL jobs using Apache Spark need at least 2 DPUs, Python Shell jobs default to using only 1/16 (or 0.0625) DPU!
This can also be extended to 1 DPU, resulting in faster completion times. Like AWS Lambda, charges accrue based on resource usage and duration. So increased resource allocation can potentially create further savings.
This section was correct as of August 2024 – the latest pricing data is on the AWS Glue pricing site.
Low Barrier To Entry
Python Shell jobs offer accessibility for those from a scripting background. When creating a new script in the console, users only need to choose the engine (in this case Python) and whether the script is being uploaded or created fresh. And that’s it! No configuring interpreters, environments or dependencies.
Python Shell jobs also integrate with other AWS services. They can easily connect to data sources like S3, RDS and DynamoDB. They can be automated with Glue Workflows and Triggers. IAM can also control access to both the Python Shell job and the AWS services it interacts with.
Included Python Libraries
AWS Glue Python Shell includes a variety of built-in Python libraries that are useful for ETL tasks. These libraries cover a range of functionalities such as data processing, machine learning, and interacting with AWS services.
They include:
- SQL engine connectors like SQLAlchemy and pyodbc.
- AWS services like redshift and PyAthena.
- ELT tools like AWS Data Wrangler and pandas
- Common libraries like numpy and requests.
This AWS post has a full table of included libraries and their versions. Additional libraries can be installed and imported using PIP.
Some people will quickly see issues with this list though…
Python Shell Cons
This section examines some of Python Shell’s limitations.
Outdated Python Versions & Libraries
While the included libraries are welcome, they are also quite outdated. For example, boto3‘s included version is 1.21.21 while the current version is 1.34.150. pandas is at 1.4.2 in the table and 2.2.2 online.
This is likely due to the supported Python versions – currently Python 3.6 and Python 3.9. Now, while Python 3.9 isn’t out of support until October 2025, it was released back in October 2020 and has had three major upgrades since. Worse, Python 3.6 ended life at Christmas 2021!
With the Data Engineer Associate certification drawing attention to various AWS data services, it’s a shame that this feature is so far behind. This would be a great modernisation tool for importing legacy Python scripts into Glue, but the last feature update was in 2022 and it’s really starting to lag behind now.
No Visual Editor
Yes I know it’s a script editor but hear me out.
Let’s briefly segue to AWS IAM. In the early days, updating IAM policies had the potential of losing afternoons to missing braces or errant commas. There was no native AWS validation tooling and the whole thing felt like a dark art for those less experienced.
Then AWS released an IAM visual policy editor. And things went from this:
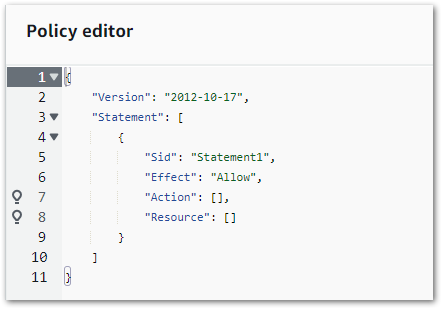
To this!
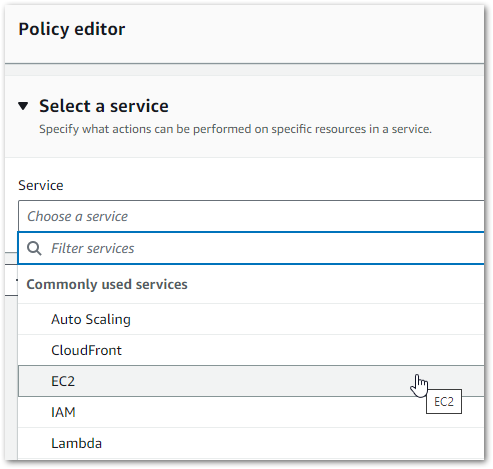
This transformed the IAM policy-writing process. The guesswork was gone – new policies could be written using dropdowns and checkboxes. And AWS would generate the same code each time, in the same way and to the same standard.
In today’s AWS console, IAM can be administrated both visually and as JSON. Updates made in the visual editor reflect in the code in real-time, and vice versa. And the IAM IDE immediately flags syntax issues, unclosed keypairs and whatnot.
This interface would work so well with Glue Script Editor. It would simplify and encourage using Script Editor, creating standardised code by default and reducing development time. No more syntax violations, verbose comments or missing dependencies – AWS could handle all that.
This doesn’t even need AI – it would just be procedural code generation. Something like selecting awswrangler from a dropdown list, then selecting an S3 location to read or write and a file type to expect. Or even a list of code snippets for the included libraries. These features could all lighten the dev load.
Limited IDE
Let’s consider AWS Lambda’s IDE:
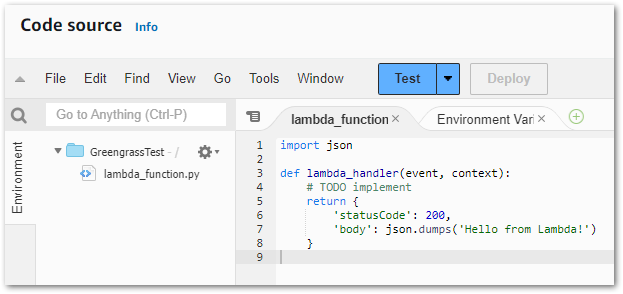
Its benefits include:
- Code autocompletion
- Integrated testing
- Integrated monitoring
And tons of other user-focused functionality. Conversely, this is the Glue Script Editor IDE:
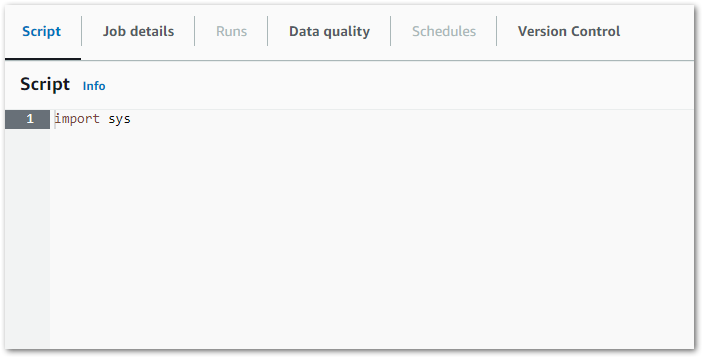
Hmm.
Now don’t get me wrong – I’m not asking for Lambda Lite. But something a bit more than Notepad would be nice. AWS are currently making a massive deal of Amazon CodeWhisperer and Amazon Q Developer‘s autocomplete actions, but here pandas isn’t even suggested when I type import pan. And it’s an included library!
The obvious solution is to just use Lambda. But Glue Script Editor offers a sweet spot where it runs custom Python while operating entirely within the AWS Glue service. This is helpful for features like Glue Triggers and Workflows that can’t currently trigger Lambda functions. It’s also helpful with AWS Organisations, where using Glue Script Editor for Python ETL can enable SCPs that entirely block access to AWS Lambda for data-centric accounts.
So Why Use It?
So are Glue Python Shell jobs worth considering with these limitations? Definately! There are several use cases favouring them:
- Legacy ETL jobs that either can’t use recent Python versions and libraries, or simply don’t need them.
- Simple, lightweight tasks that don’t require the more advanced (and expensive) features of Apache Spark or Ray.
- Tasks that need to run quickly, as Python Shells have faster startup times than the Spark environments used by regular Glue ETL jobs.
- Long-running ETL tasks unsuitable for AWS Lambda, as Python Shell jobs can run for up to 48 hours compared to Lambda’s 15 minutes. Thanks to Yan Cui‘s blog for that one!
For my requirements, a Python Shell job makes sense because I’m doing simple transformations on small volumes of data.
Architecture
This section examines the architecture of my proposed solution. Much of this architecture is similar to the Bronze layer. I’ll examine the new Silver ELT job, followed by the updated data pipeline Step Function workflow.
Glue Silver ETL Job
Firstly, this is the Glue Silver ETL job:
While updating CloudWatch Logs throughout:
- Silver Glue ETL job extracts data from
wordpress-apiBronze S3 objects and performs Python transformations. - Silver Glue ETL job loads the transformed data into Silver S3 bucket as Parquet objects.
Step Function Workflow
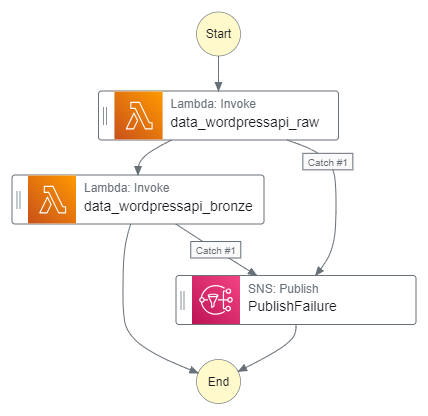
Next, the updated Step Function workflow:
While updating the workflow’s CloudWatch Log Group throughout:
- An EventBridge Schedule executes the Step Functions workflow.
- Raw Lambda function is invoked.
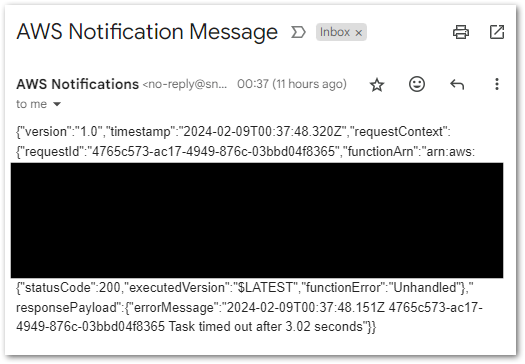
- Invocation Fails: Publish SNS message. Workflow ends.
- Invocation Succeeds: Invoke Bronze Lambda function.
- Bronze Lambda function is invoked.
- Invocation Fails: Publish SNS message. Workflow ends.
- Invocation Succeeds: Run Glue Crawler.
- Glue Crawler runs.
- Run Fails: Publish SNS message. Workflow ends.
- Run Succeeds: Update Glue Data Catalog. Run Glue Silver ETL job.
- Glue Silver ETL job runs.
- Run Fails: Publish SNS message. Workflow ends.
- Run Succeeds: Workflow ends.
An SNS message is published if the Step Functions workflow fails.
Silver ETL Job
In this section, I create the Silver ETL Python script for the AWS Glue Script Editor. Firstly I’ll define the script’s requirements. Next, I’ll translate them into Python code, and finally I’ll create the ETL script and upload it to Git.
Requirements
Firstly, let’s define the requirements for this data pipeline layer. So what does a typical Silver ETL process involve?
Databricks defines the Silver layer as cleansed and conformed data:
In the Silver layer of the lakehouse, the data from the Bronze layer is matched, merged, conformed and cleansed (“just-enough”) so that the Silver layer can provide an “Enterprise view” of all its key business entities, concepts and transactions. (e.g. master customers, stores, non-duplicated transactions and cross-reference tables).
https://www.databricks.com/glossary/medallion-architecture
Because my data source is a WordPress MySQL database, most of the cleansing and conforming work I’d expect to do has already been done there! That said, there’s data that I definitely won’t need, as well as other transformations I can apply to help downstream reporting.
Some of the following transformations can be done at the SQL reporting level with date and string functions. However, these add repetitive load and complexity to queries, which can be avoided by some cleaning transformations. Roche’s Maxim of Data Transformation applies here:
Data should be transformed as far upstream as possible, and as far downstream as necessary.
https://ssbipolar.com/2021/05/31/roches-maxim/
The Silver layer transformations I’m doing here are:
Column Removal
Many columns are empty or unneeded, so now is the time to remove them. This will reduce the data held in the Silver objects, making them cheaper to store and faster to query.
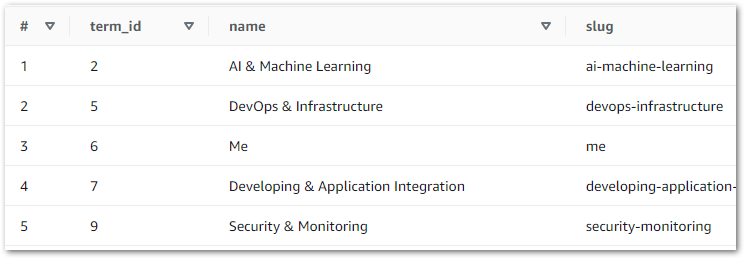
My script uses the pandas.DataFrame.drop function to remove columns by specifying column names. Here, a term_order column is dropped from the DataFrame df:
df = df.drop(columns=['term_order'])Date Splitting
Dates are tough to analyse and don’t aggregate well, as each date is effectively three different data points in one field. Splitting dates into years, months and days improves data bucketing, query granularity and time series analytics.
My script uses the pandas to_datetime function to convert scalar, array-like, Series or DataFrame/dict-like objects to pandas datetime objects.
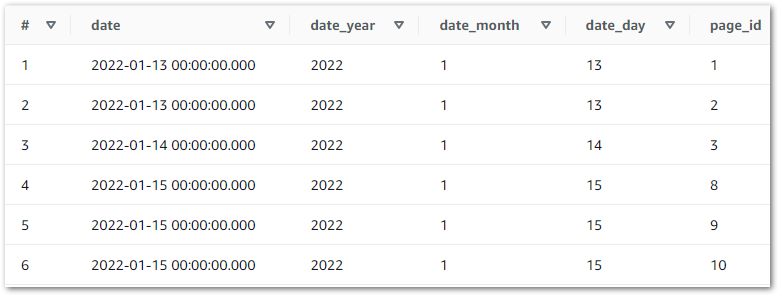
Here, values in the date column of the DataFrame df are converted from strings to datetime objects and stored in a new date_todate column. Next, the year attribute of each date_todate column object is extracted and stored in a new date_year column. Finally, the same happens for month and day attributes:
df['date_todate'] = pd.to_datetime(df['date'])
df['date_year'] = df['date_todate'].dt.year
df['date_month'] = df['date_todate'].dt.month
df['date_day'] = df['date_todate'].dt.dayString Editing
Some columns use HTML character entity names for reserved characters. For example, & in place of &. This is great for rendering HTML but not great for analytics.
My script uses the str.replace string method to return a copy of each string with all occurrences of the specified substring replaced by a new one. Here, all instances of & amp; in the name column are overwritten with &:
df['name'] = df['name'].str.replace('& amp;','&')So that’s the transformations. What else is the script doing?
Python Script
Most of the Silver script processes are similar to the Bronze script ones, including:
- Logging
- Getting parameters
- Accessing S3 objects
So most functionality is reused from my Bronze Lambda function, which is fully documented in this post. To summarise the imports:
import logging # Logging
import boto3 # AWS Interactions
import botocore # AWS Exceptions
import awswrangler as wr # S3 Interactions
import pandas as pd # Data Manipulation
from botocore.client import BaseClient # AWS Type HintsSome changes have been made for the Silver script:
- Parameters, object names and logs have been updated from
BronzetoSilver:
parametername_snstopic: str = '/sns/data/lakehouse/silver'
logging.info("Getting S3 Silver parameter...")
s3_bucket_silver = get_parameter_from_ssm(client_ssm, parametername_s3bucket_silver)- New functionality identifies the AWS AccountID the script is running in:
# Get & display AWS AccountID
identity = client_sts.get_caller_identity()
account_id = identity['Account']
logging.info(f"Starting in AWS Account ID {account_id}")This is more of a sanity check for me – I have several AWS accounts and want to check I’ve accessed the right one!
- A test that stops the current loop interaction if the object name doesn’t match one of the expected ones:
# Check if object is mapped and bypass if not.
if object_name not in {'posts', 'statistics_pages', 'term_relationship', 'term_taxonomy', 'terms'}:
logging.warning(f'{object_name} is not currently mapped. Skipping transform...')
object_count_failure += 1
continueFinally, I wrote a new function for my Silver transformation logic. This isn’t included here (although it is in my repo) because it’s long. Very long! My first thought was to decouple the ETL processes from each other and write separate scripts for each object. So 5 in total.
However, Python Shell jobs are billed per second with a 1-minute minimum. So 5 jobs = 5 minutes billed. But the job only takes around 60 seconds to process all five objects! I’d have run up 5 times the usage and 5 times the cost for no real benefit.
The full script is in my Github repo.
Testing was quick because it was effectively repeating the Bronze script tests with new parameters. After successfully testing the script locally, it’s time to get it working in AWS!
Uploading & Testing
In this section I upload my Silver ETL script, integrate it with AWS Glue Script Editor and AWS Step Functions and test everything works as expected.
Creating The Python Shell Job
Firstly, let’s get my script into AWS Glue. There are several ways of doing this. If the script is uploaded to S3 then AWS can create a Glue ETL job with the AWS CLI create-job command:
aws glue create-job --name python-job-cli --role Glue_DefaultRole
--command '{"Name" : "pythonshell", "PythonVersion": "3.9", "ScriptLocation" : "s3://DOC-EXAMPLE-BUCKET/scriptname.py"}'
--max-capacity 0.0625
And with the AWS CloudFormation AWS::Glue::Job resource:
AWSTemplateFormatVersion: 2010-09-09
Resources:
Python39Job:
Type: 'AWS::Glue::Job'
Properties:
Command:
Name: pythonshell
PythonVersion: '3.9'
ScriptLocation: 's3://DOC-EXAMPLE-BUCKET/scriptname.py'
MaxRetries: 0
Name: python-39-job
Role: RoleName
Scripts can also be pulled from Git repositories. Here I’ll create my Silver ETL job in the Glue Script Editor console. This creates a new Python script in an S3 bucket location of s3://aws-glue-assets-[AWSAccountID]-[Region]/scripts/.
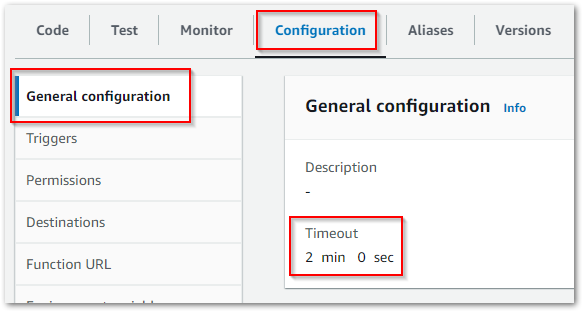
Next, the new job needs an IAM role with appropriate permissions for the AWS services the script interacts with. Other parameters, including maximum DPU, job timeout value and Python version, can also be set. In addition, Glue Data Quality checks are also supported. And, once saved, the Glue job can have a schedule applied.
Testing Job Execution
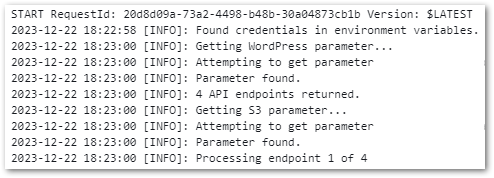
AWS Glue records data for each job execution and publishes extensive details and logs:
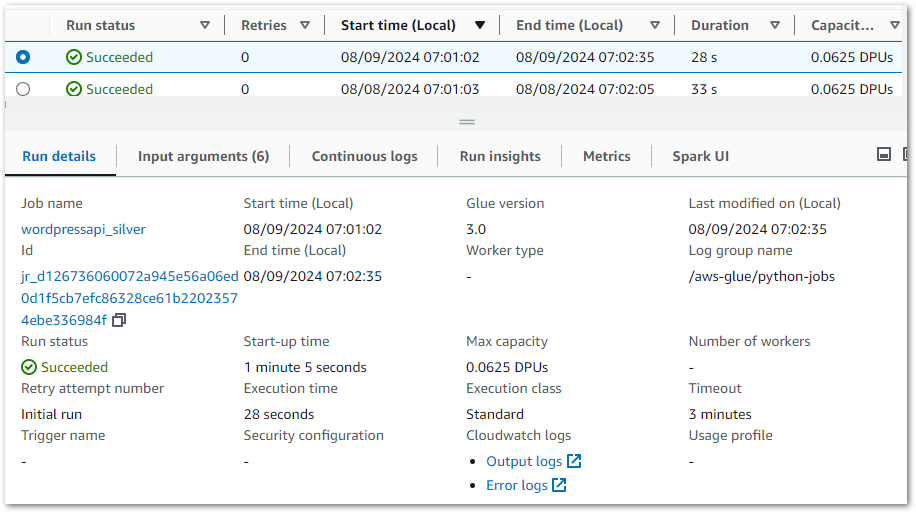
Glue stores details about the job and Python environment, and logs are published and stored in Amazon Cloudwatch.
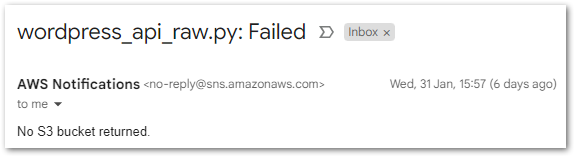
And so begins the testing! Initially, I was getting one of my own Python boto3 exceptions:
ValueError: No SNS topic returned.Easy to fix. This IAM policy was based on the same one that my Bronze Lambda function uses. But the Silver ETL script uses different AWS resources so some IAM policy ARNs need to change. Specifically, the Silver ETL job’s IAM role needs to allow:
ssm:GetParameteron the required Parameter Store parameters.sns:Publishon the required SNS topics.s3:GetObjecton thedata-lakehouse-silver/wordpress_api/*objects.
With these changes, the Silver ETL job runs perfectly and creates new objects in the Silver S3 bucket:
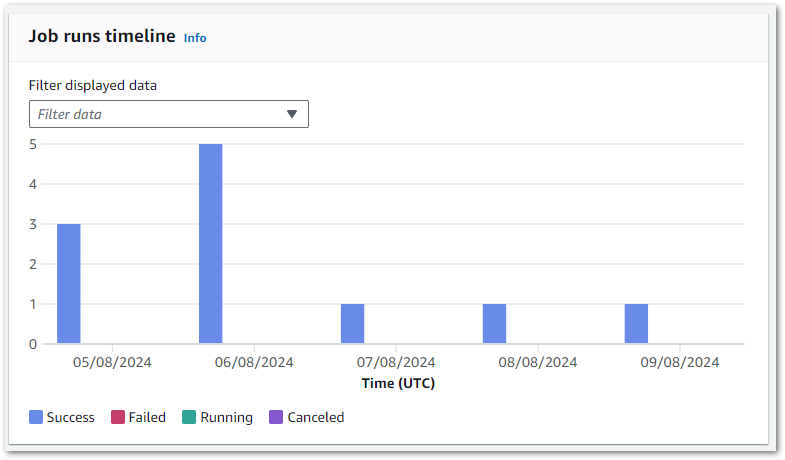
With the Glue job running and S3 object creation verified successfully, it’s time to validate the data.
Data Integration & Validation
Validating the data involves two processes:
- Integrating the data into the Glue Data Catalog.
- Querying the data with Amazon Athena.
There are several ways to update the Glue Data Catalog, and here I’ll create a new Glue Crawler using a similar setup to my Bronze Crawler. This time the crawler is reading objects from the Silver S3 bucket instead of the Bronze one, and the new Glue Data Catalog tables are prefixed with silver- instead of bronze-.
The Silver crawler creates these new tables in the Glue Data Catalog’s wordpress_api database:
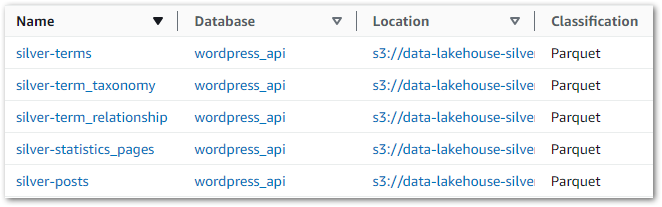
This gives Athena visibility of the tables, enabling data validation via SQL query execution. Querying wordpress_api.silver-terms shows the removed column and updated strings:
And querying wordpress_api.silver-statistics_pages shows the split dates:
Looks good! Now that everything has been validated, let’s add these steps to the WordPress Data Pipeline.
Step Function Update
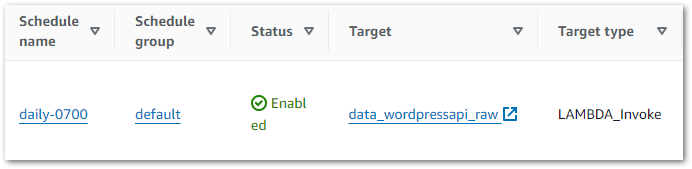
The WordPress Data Pipeline Step Function workflow that I started back in March continues to grow. There’s a new job and a second crawler to add to it now!
The Silver crawler is added in the same way as the Bronze one (including the IAM changes) so let’s focus on adding the new Glue Python Shell ETL job.
Adding Glue ETL jobs to a Step Function workflow is well documented The task uses the StartJobRun Glue API action under the hood and has an optimized integration that enables the .sync integration pattern. Enabling this means the Step Functions workflow waits for the StartJobRun request to complete before progressing to the next state.
However, my workflow currently lacks IAM permissions to run the Silver Glue ETL job. So I make a new IAM policy that allows the glue:StartJobRun action on the Silver Glue ETL job and attach it to the workflow’s IAM role:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:StartJobRun"
],
"Resource": "arn:aws:glue:eu-west-1:[REDACTED]:job/wordpressapi_silver"
}
]
}My Step Function workflow now looks like this:
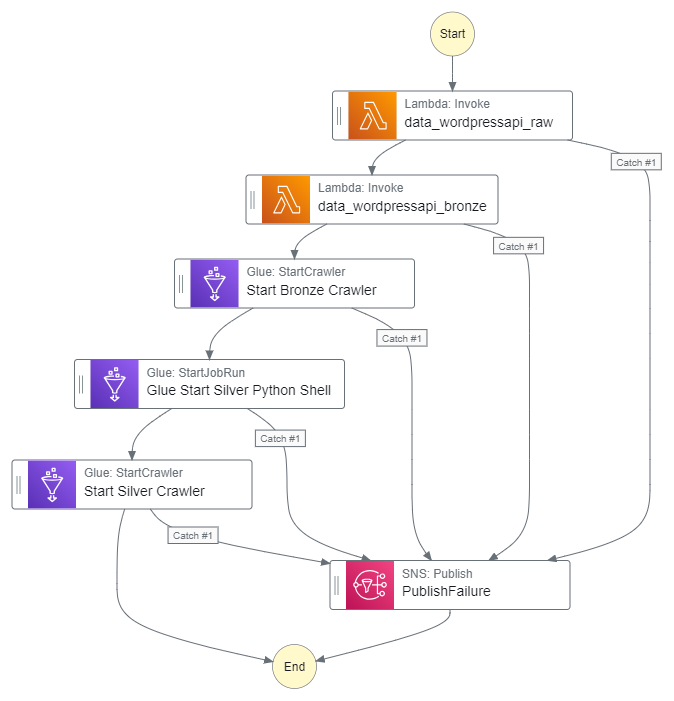
Let’s execute the Step Function workflow and check it works.
Step Function Test
Upon execution, everything works as intended. The new StartGlueJob action is triggered and the Glue ETL job is successful:
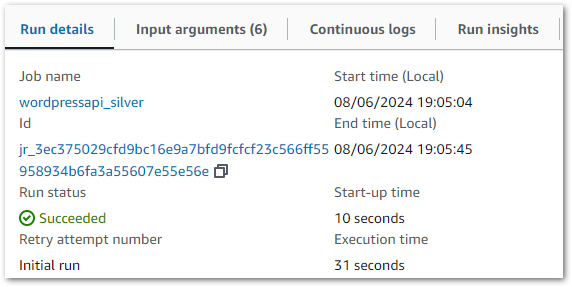
But the Step Function doesn’t transition to the next step. In fact it continued running to the point I had to stop it myself after several minutes:
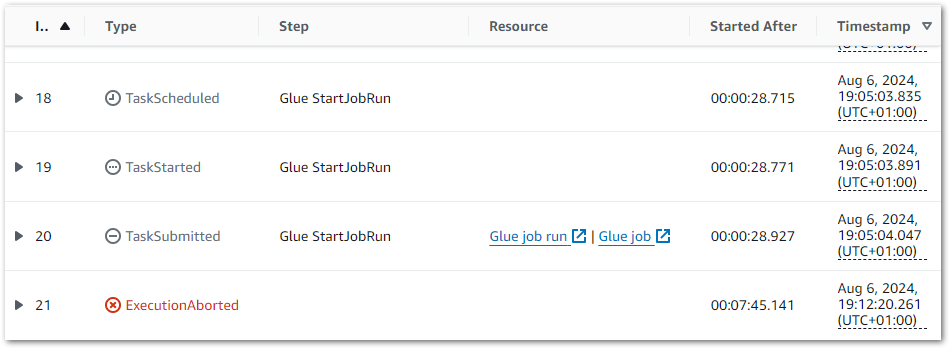
So what’s going on? I asked Amazon Q about this behaviour, and in its response were the following points:
Amazon Q
- Step Functions uses a “sync” integration with AWS Glue, which means it relies on polling the status of the Glue job using the GetJobRun API call.
- The polling schedule is designed to be once per minute for the first 10 minutes, and then every 5 minutes thereafter. This is to avoid excessive API calls to Glue.
Q also linked to this AWS repost answer with further details:
This is an expected behavior in case of .sync integration with AWS Glue. Service integrations that use the .sync pattern require additional IAM permissions where Step Functions will make use of a managed Eventbridge rule to monitor the status of the job. However, AWS Glue does not support Eventbridge integration and thus, Step Functions polls the job status using the GetJobRun API call to fetch the status of the job.
https://repost.aws/questions/QUFFlHcbvIQFe-bS3RAi7TWA/a-glue-job-in-a-step-function-is-taking-so-long-to-continue-the-next-step
This made things clearer. When Step Functions starts a Glue ETL job using a StartGlueJob action with optimized integration, Step Functions determines that job’s status (and thus when to transition to the next action) by calling Glue’s GetJobRun API.
However, my workflow’s IAM role doesn’t have permission to do that! And because Step Functions can’t determine the ETL job’s status, it doesn’t know that the job has finished and the next state transition never happens! Everything stops!
This is resolved by adding the glue:GetJobRun action to the workflow’s IAM policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:StartJobRun",
"glue:GetJobRun"
],
"Resource": "arn:aws:glue:eu-west-1:REDACTED:job/wordpressapi_silver"
}
]
}This time, the Glue GetJobRun API calls are successful. The Step Functions workflow validates that the ETL job has finished, moves to the next state as intended and ultimately completes successfully:
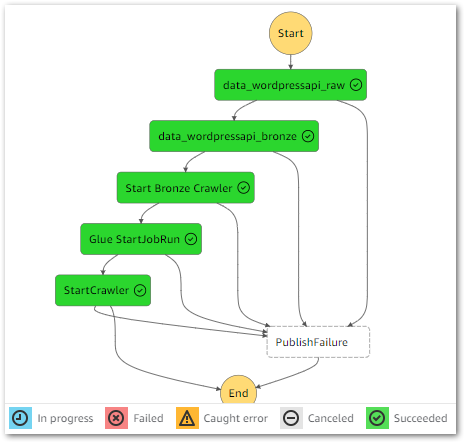
Thanks Amazon Q!
Costs
Finally, let’s look at the costs for my Glue Script Editor Silver ETL Job resources.
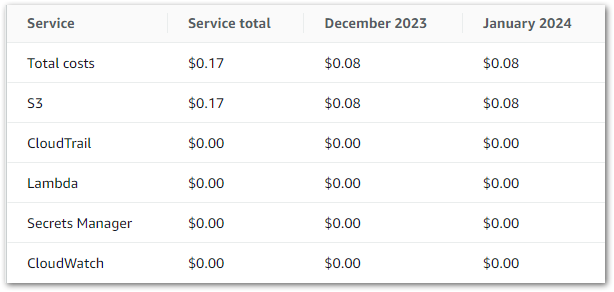
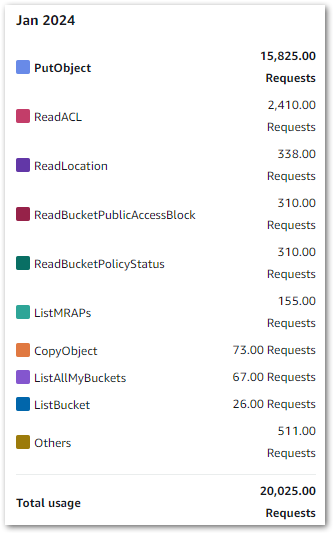
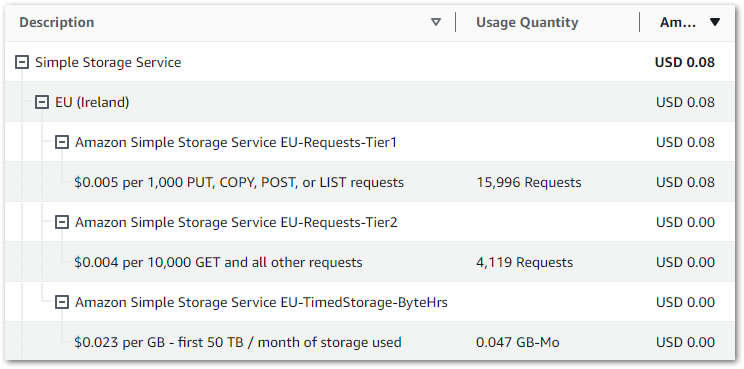
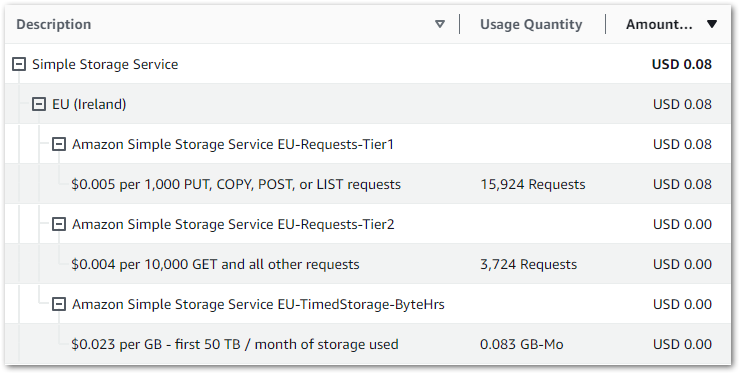
This graph shows all Glue API costs between 2024-07-31 (first AWS job execution) and 2024-09-09:
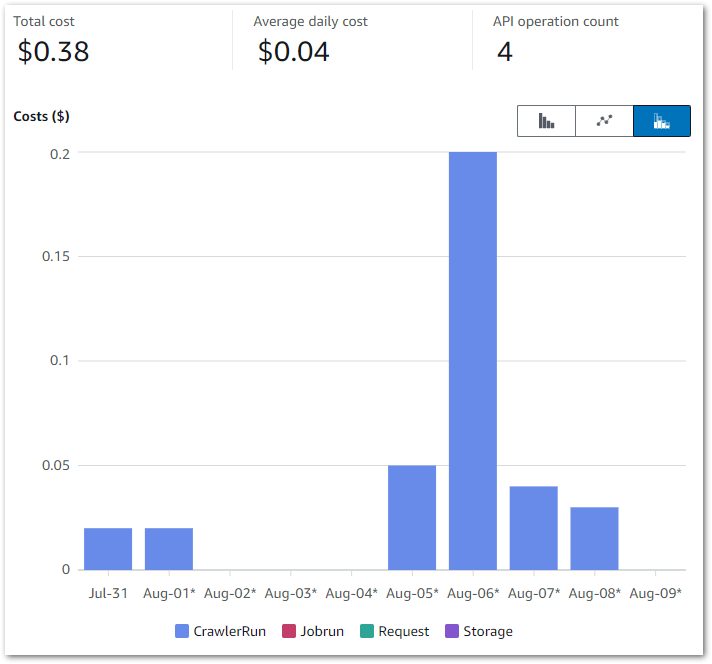
Of the $0.38:
- $0.37 is the
CrawlerRunAPI for the two Glue Crawlers I’m running. - $0.01 is the
JobrunAPI for the 15 job runs between 2024-07-31 and 2024-09-09.
So all things considered, very manageable!
Summary
In this post, I created my WordPress data pipeline’s Silver ETL process using Python and the AWS Glue ETL Job Script Editor.
I found the Script Editor jobs very useful. They offer Lambda’s benefits of scalability, managed infrastructure and integration with other AWS services, combined with data-centric libraries and features that make it easier to hit the ground running development-wise. It has clear limitations and could do with some AWS TLC, but it was a good fit here and rivals Lambda for some future ETL processes I have planned.
If this post has been useful then the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~