This hasn’t come easy for someone as naturally anxious as me. I work procedurally in many areas, which doesn’t lend itself fully to organic and spontaneous pursuits like public speaking.
I use mantras during exercise when I need quick guidance that’s easy to recall, and after London I realised that a similar approach while speaking would calm my nerves and refocus my attention. These mantras have since become invaluable, so now I’ll present them here.
Firstly, I’ll share three mantras that have guided me through developing, presenting, and evaluating my sessions. Following this, I’ll add some helpful resources for session creation, slide deck development and delivery mindset.
Mantras
This section contains three mantras for the anxious new speaker that I’ve used this year.
No One Wants You To Fail
I begin with some imposter syndrome goodness. Public speaking offers rich ammunition for imposter syndrome sufferers, like:
“The audience will be full of experts and I don’t belong in front of them.”
“No one will enjoy my session or find it useful.”
“No one will take me seriously.”
But the reality is very different. Audiences want speakers to succeed because it creates a more enjoyable and informative event, fostering better knowledge sharing and a positive atmosphere.
And it’s not like the session’s content is a secret! Consider delivering a session to a user group. The session’s abstract has likely been seen by a user group leader and several audience members before the doors even open. People know what they are getting into and are choosing to be there!
Audiences want to enjoy and benefit from the session, and they’re often patient, understanding, and forgiving when things don’t go perfectly. They’re not there to criticise or judge – they’re hoping the speaker succeeds and provides value.
Anxiety brain then fixated on the various keynotes and TED Talks I’ve seen instead of focusing on my session. Great.
Then I had an idea. I started watching the audience. Some people were checking their lanyards and swag bags. Others were glancing at the passing crowds or grabbing a coffee from the nearby Serverlesspresso stand. But most were fully focused on the slides.
No one was fixated on the speaker.
Next, I watched the speaker. They looked up and down, occasionally gesturing. Nothing about their delivery felt like a finely choreographed routine.
In those moments, I realised that I was holding myself to impossibly high standards for my first in-person session. This wasn’t reality TV or theatre. This was a group of enthusiasts with common interests seeking knowledge. The audience wasn’t here to watch me. They were here to watch the slides.
That shift in perspective helped me so much. Without that mantra in April, there’s no way I would have been capable of doing Comsum (a filmed session in front of a paying audience) in September:
Every Minute Is A Victory
I said I use mantras during exercise earlier, and this one is pretty much a straight rip from those. Being a speaker (especially an anxious new speaker!) demands time and energy for tasks like:
Developing an abstract, submitting it to a user group or call for papers and awaiting the outcome.
Curating and preparing a session, updating and refining a slide deck and practising delivery.
Making sure you’re in the right place, at the right time with the right materials. And waiting for the day to arrive!
Delivering the session, maintaining flow and addressing audience questions.
Evaluating the session, tweaking the content and reflecting personally on the experience.
It would be easy to look at all this, nope out and spend your time elsewhere. So every minute spent on a session, from inception to post-delivery, is a victory.
Resources
This section contains some helpful resources for session development.
New Stars Of Data has a Speaker Improvement Library supported by the Microsoft Azure Data Community. This library was invaluable during my New Stars of Data journey, and I still refer to it regularly for guidance and inspiration.
Here are some of my personal favourites from the library:
“Accept that everything is a draft. It helps to get it done.”
Cult of Done Manifesto Principle 2
In my experience, a session is never truly finished. Slide optimisations and delivery improvements often become evident during the presentation. Audience questions and comments may prompt revisions. And as technology and the cloud evolve, the session itself may need to change.
“Pretending you know what you’re doing is almost the same as knowing what you are doing, so just accept that you know what you’re doing even if you don’t and do it.”
Cult of Done Manifesto Principle 4
This is already pretty descriptive – an eloquent version of “fake it till you make it”. To paraphrase Tris Oaten, you’re watching me learn how to construct a session in real-time. You’re watching me learn to present in real-time, and how to submit abstracts, build confidence and answer audience questions in real-time.
This is a continual journey that even seasoned presenters are on. There is no shame in such a journey, so embrace it.
“Done is the engine of more.”
Cult of Done Manifesto Principle 13
Every finished session offers something in exchange. This ranges from improved confidence and skills to increased momentum and drive. And the more abstracts written, the more sessions submitted and the more presentations delivered, the more you build a foundation for better talks, deeper insights, and greater confidence in your abilities.
Note that ‘more’ doesn’t necessarily mean ‘more sessions’ here. ‘More’ can mean:
Personal growth
Networking with fellow enthusiasts and community members.
Development opportunities (you never know who’s in the audience!)
I’ll end it here, but many other principles apply. Be sure to check out the full manifesto and Tris’ No Boilerplate video for more insights:
Summary
In this post, I shared three mantras for the anxious new speaker and some helpful resources for session development that I’ve used this year.
Public speaking comes more easily to some than others. I never expected to find myself in this position, and I’m not sure I would have believed anyone who told me this is how 2024 would unfold! Mantras are powerful tools for calming nerves and building confidence, and if these don’t resonate with you then there are plenty of others to explore.
If this post has been useful, check out the button below for links to my contact information, social media, projects, and upcoming sessions:
In my last post, I used the AWS Glue ETL Job Script Editor to write a Silver ETL Python script. Within that script and the ones prior, there are checks like:
If these checks all pass then datasets are created in various S3 buckets. But before I use these datasets for reporting and analytics, I should check their quality first.
Launched in 2023, AWS Glue Data Quality measures and monitors data quality and veracity. It is built on top of an open-source framework, and provides a managed, serverless experience with machine learning augmentation.
Firstly, I’ll examine AWS Glue Data Quality and some of its features. Then I’ll use it to recommend rules for some of my Silver layer data objects, and then customise those recommendations as needed. Next, I’ll create and test a Glue Data Quality job using those rules. Finally, I’ll examine my Glue Data Quality costs.
AWS Glue Data Quality
This section introduces AWS Glue Data Quality and examines some of its features.
What Is Glue Data Quality?
From AWS:
AWS Glue Data Quality evaluates and monitors the quality of your data based on rules that you define. This makes it easy to identify the data that needs action. You can then monitor and evaluate changes to your datasets as they evolve over time.
Creating & recommending sets of data quality rules.
Running the data quality rules as on-demand and scheduled jobs.
Monitoring and reporting against the data quality results.
So how do data quality rules work?
Glue Data Quality Rules
From AWS:
AWS Glue Data Quality currently supports 18 built-in rule types under four categories:
Consistencyrules check if data across different columns agrees by looking at column correlations.
Accuracy rules check if record counts meet a set threshold and if columns are not empty, match certain patterns, have valid data types, and have valid values.
Integrity rules check if duplicates exist in a dataset.
Completenessrules check if data in your datasets do not have missing values.
AWS Glue Data Quality rules are defined using Data Quality Definition Language (DQDL). DQDL uses a Rules list containing comma-separated rules in square brackets.
For example, this DQLD rule checks for missing values in customer-id and unique values in order-id:
AWS maintains a DQDL reference that advises about syntax, structure, expressions, and rule types. Now all of this can be a lot to take in, so a good way of getting started is to get AWS to do some of the heavy lifting…
Glue Data Quality Rule Recommendations
Getting to grips with new features can be daunting. To help out, AWS Glue Data Quality can analyse data in the Glue Data Catalog. This process uses machine learning to identify and recommend rules for the analysed data. These rules can then be used and changed as needed.
Glue Data Quality recommendations are generated using Amazon’s Deequ open-source framework, which is tested on Amazon’s own petabyte-scale datasets. AWS has documented the recommendation generation process, and has released supporting videos like:
So that’s enough theory – let’s build something!
Ruleset Creation
In this section, I create a Glue Data Quality veracity ruleset for my silver-statistcs_pages dataset by generating and customising Glue’s recommendations.
Generating Recommendations
Firstly, I told Glue Data Quality to scan the dataset and recommend some rules. Two minutes later, Glue returned these:
Plaintext
Rules = [ RowCount between 4452 and 17810, IsComplete "page_id", StandardDeviation "page_id" between 2444.94 and 2702.3, Uniqueness "page_id" > 0.95, ColumnValues "page_id" <= 8925, IsComplete "uri", ColumnLength "uri" <= 190, IsComplete "type", ColumnValues "type" in ["post","home","page","category","post_tag","archive","author","search"], ColumnValues "type" in ["post","home"] with threshold >= 0.94, ColumnLength "type" between 3 and 9, IsComplete "date", IsComplete "count", ColumnValues "count" in ["1","2","3","4","5","6"] with threshold >= 0.9, StandardDeviation "count" between 3.89 and 4.3, ColumnValues "count" <= 93, IsComplete "id", ColumnValues "id" in ["92","11","281","7","1143","1902","770","1217","721","1660","2169","589","371","67","484","4","898","0","691","2029","1606","2686","1020","2643","2993","1400","30","167","2394"] with threshold >= 0.89, StandardDeviation "id" between 820.3 and 906.65, ColumnValues "id" <= 3532, IsComplete "date_todate", IsComplete "date_year", ColumnValues "date_year" in ["2023","2024","2022"], ColumnValues "date_year" between 2021 and 2025, IsComplete "date_month", ColumnValues "date_month" in ["6","7","5","4","3","8","2","1","11","12","10","9"], ColumnValues "date_month" in ["6","7","5","4","3","8","2","1","11","12","10"] with threshold >= 0.94, StandardDeviation "date_month" between 3.09 and 3.41, ColumnValues "date_month" <= 12, IsComplete "date_day", ColumnValues "date_day" in ["13","7","12","8","6","3","19","20","17","4","9","14","1","16","2","11","5","15","10","26","21","25","24","18","27","22","28","30","23","29","31"], ColumnValues "date_day" in ["13","7","12","8","6","3","19","20","17","4","9","14","1","16","2","11","5","15","10","26","21","25","24","18","27","22","28","30"] with threshold >= 0.91, StandardDeviation "date_day" between 8.3 and 9.18, ColumnValues "date_day" <= 31]
A lot is going on here, so let’s deep a little deeper.
Recommendations Analysis
As with many machine learning processes, some human validation of the results is wise before moving forward.
While Glue Data Quality can predict rules based on its ML model and the data supplied, I have years of familiarity with the data and can intuit likely future trends and patterns. As Glue currently lacks this intuition, some recommendations are more useful than others. Let’s examine some of them and I’ll elaborate.
IsComplete checks whether all of the values in a column are complete with no NULL values present. This is completely reasonable and should apply to all columns in the silver-statistics_pages data. An easy win.
However, some recommendations need work:
Plaintext
ColumnValues "date_year" in ["2023","2024","2022"],ColumnValues "date_year" between 2021 and 2025,
ColumnValues runs an expression against the values in a column. These rules (which are both checking the same thing as DQDL’s BETWEEN is exclusive) state that:
date_year must be 2022, 2023 or 2024
This is fine for now, as 2024 is the current year and the first statistics are from 2022. But a post published next year will cause this rule to fail. And not because of incorrect data – because of incorrect rule configuration. Hello false positives!
Finally, some suggestions are outright wrong. For example:
Plaintext
ColumnValues "page_id" <= 8925,
This rule checks that the page_id column doesn’t exceed 8925. But page_id is a primary key! It auto-increments with every new row! So this rule will fail almost immediately, and so is completely unsuitable.
Ok so let’s fix them!
Recommendations Modifications
Firstly, let’s fix the date_year rule by replacing the range with a minimum value:
Plaintext
ColumnValues "date_year" >= 2021,
Now let’s fix the page_id rule. This column is a primary key in the WordPress MySQL database, so every value should be unique. Therefore the ruleset should check page_id for uniqueness.
As it turns out I’m spoilt for choice here! There are (at least) three relevant rules I can use:
IsUnique checks whether all of the values in a column are unique. Exactly what I’m after.
IsPrimaryKey goes a step further, verifying that a column contains a primary key by checking if all of the values in the column are unique and complete (non-null).
Finally, Uniqueness checks the percentage of unique values in a column against a given expression. In my example, "page_id" = 1.0 states that each page_id column value must be 100% unique.
So why not use them all? Well, besides that being overkill there is a cost implication. Like many Glue services, AWS Glue Data Quality is billed by job duration (per DPU hour). If I keep all three rules then I’m doing the same check three times. This is wasteful and creates unnecessary costs.
Here, the IsPrimaryKey check most closely matches the source column (itself a primary key) so I’ll use that.
Elsewhere, I’m simplifying date_month and date_day. While these are correct:
Plaintext
ColumnValues "date_month" in ["6","7","5","4","3","8","2","1","11","12","10","9"],ColumnValues "date_day" in ["13","7","12","8","6","3","19","20","17","4","9","14","1","16","2","11","5","15","10","26","21","25","24","18","27","22","28","30","23","29","31"],
It’s far simpler to read as:
Plaintext
ColumnValues "date_month" between 0 and 13,ColumnValues "date_day" between 0 and 32,
Finally, I did some housekeeping to reduce the ruleset’s duration:
Removed all the duplicate checks. IsComplete was fine for most.
ColumnLength checks are gone as the WordPress database already enforces character limits.
StandardDeviation checks are also gone as they don’t add any value here.
Now let’s use these suggestions as a starting point for my own ruleset.
Customising A Ruleset
In addition to the above rules and changes, the following rules have been added to the silver-statistics_pages ruleset:
ColumnCount checks the dataset’s column count against a given expression. This checks there are ten columns in silver-statistics_pages:
Plaintext
ColumnCount = 10
RowCount checks a dataset’s row count against a given expression. This checks there are more than zero rows in silver-statistics_pages:
Plaintext
RowCount > 0
RowCountMatch checks the ratio of the primary dataset’s row count and a reference dataset’s row count against the given expression. This checks that the row count of silver-statistics_pages and bronze-statistics_pages are the same (100%):
ReferentialIntegrity checks to what extent the values of a set of columns in the primary dataset are a subset of the values of a set of columns in a reference dataset. This checks that each silver-statistics_pages ID value is present in silver-posts:
Finally, here is my finished silver-statistics_pages ruleset:
Plaintext
# silver-statistics_pages data quality rulesRules = [ # all data ColumnCount = 10, RowCount > 0, RowCountMatch "wordpress_api.bronze-statistics_pages" = 1.0, # page_id IsPrimaryKey "page_id", # uri IsComplete "uri", # type IsComplete "type", # date IsComplete "date", ColumnValues "date_todate" <= now(), # count IsComplete "count", ColumnValues "count" between 0 and 1000, # id IsComplete "id", ReferentialIntegrity "id" "wordpress_api.silver-posts.id" = 1.0, # date_todate IsComplete "date_todate", ColumnValues "date_todate" <= now(), # date_year IsComplete "date_year", ColumnValues "date_year" >= 2021, # date_month IsComplete "date_month", ColumnValues "date_month" between 0 and 13, # date_day IsComplete "date_day", ColumnValues "date_day" between 0 and 32]
Once a ruleset is created, it can be edited, cloned and run. So let’s test it out!
Ruleset Testing
In this section, I test my Glue Data Quality veracity ruleset and act on its findings. But first I need to get it running…
Job Test: Data Fetch Fail
Running my ruleset for the first time, it didn’t take long for a problem to appear:
Plaintext
Exception in User Class: java.lang.RuntimeException : Failed to fetch data. Please check the logs in CloudWatch to get more details.
Uh oh. Guess it’s time to check CloudWatch. This wasn’t an easy task the first time round!
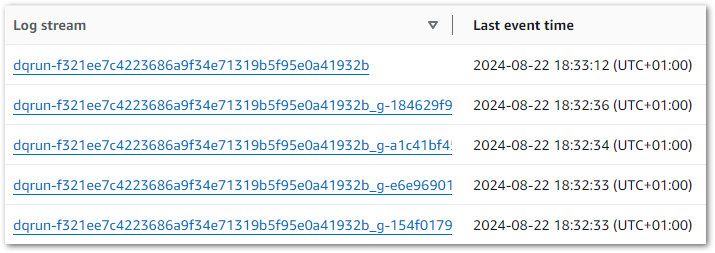
Glue Data Quality generates two new log groups:
aws-glue/data-quality/error
aws-glue/data-quality/output
And each Data Quality job run creates five log streams:
But there’s no clear hint of where to start! So I dived in and started reading the error logs. After some time, it turned out I actually needed the output logs. Oh well.
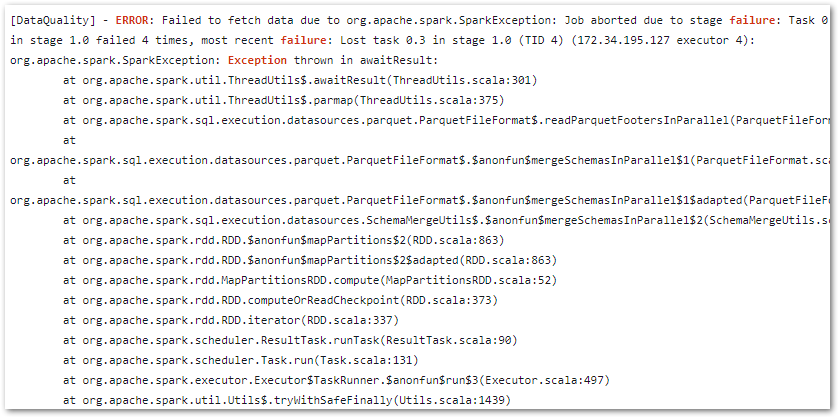
And in an output log stream’s massive stack trace:
This isn’t even half of it – Ed
Was my problem:
Plaintext
Caused by:java.io.FileNotFoundException:No such file or directory's3://data-lakehouse-bronze/wordpress_api/statistics_pages/statistics_pages.parquet'
No such directory? Well, there definitely is! Sounds like a permissions issue. What gives?
So, remember my RowCountMatch check? It’s trying to compare the silver-statistics_pages row count to the bronze-statistics_pages row count. Like most AWS services, AWS Glue uses an IAM role to interact with AWS resources – in this case the Bronze and Silver Lakehouse S3 buckets.
So let’s check:
Can the Glue Data Quality check’s IAM role read from the Silver Lakehouse S3 bucket? Yup!
Can it read from the Bronze one? Ah…
Adding s3:GetObject for the bronze S3 path to the Glue Data Quality check’s IAM role fixed this error. Now the job runs and returns results!
Job Test: Constraint Not Met
Next up, I got an interesting message from my ColumnValues "count" rule:
Plaintext
ColumnValues "count" between 0 and 1000Value: 93.0 does not meet the constraint requirement!
That’s…a lot! Then I realised I’d set the rule conditions to between 0 and 1 instead of between 0 and 1000. Oops…
Then I got a confusing result from my ReferentialIntegrity "id" "wordpress_api.silver-posts.id" = 1.0 rule:
Plaintext
ReferentialIntegrity "id" "wordpress_api.silver-posts.id" = 1.0 Value: 0.9763982102908277 does not meet the constraint requirement.
As a reminder, ReferentialIntegrity checks to what extent the values of a set of columns in the primary dataset are a subset of the values of a set of columns in a reference dataset. And because "wordpress_api.silver-statistics_pages.id" values are based entirely on "wordpress_api.silver-posts.id" values, they should be a perfect match!
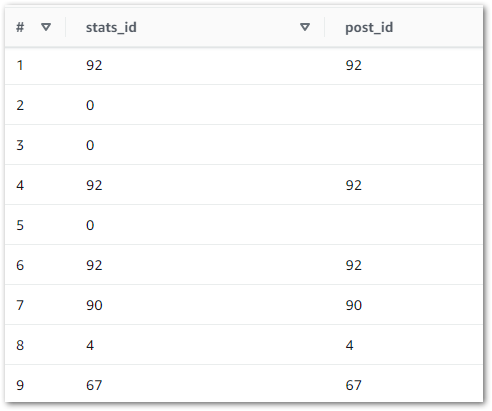
Time to investigate. I launched Athena and put this query together:
SQL
SELECTsp.idAS stats_id,p.idAS post_idFROM"wordpress_api"."silver-statistics_pages"AS spLEFT JOIN"wordpress_api"."silver-posts"AS p ONsp.id=p.id
And the results quickly highlighted a problem:
Here, the LEFT JOIN retrieves all silver-statistics_pages IDs and each row’s matching ID from silver-posts. The empty spaces represent NULLs, where no matching silver-posts ID was found. So what’s going on? What is stats_id zero in silver-statistics_pages?
Reviewing the silver-statistics_pagesuri column shows that ID zero is amazonwebshark’s home page. As the WordPress posts table doesn’t record anything about the home page, the statistics_pages table can’t link to anything in posts. So ID zero is used to prevent missing data.
Knowing this, how can I update the rule? In June 2024 AWS added DQDL WHERE clause support, so I tried to add a “where statistics_pages ID isn’t zero” condition. But in testing the editor either didn’t run the check properly or rejected my syntax entirely. So eventually I settled for changing the check’s threshold from = 1.0 to >= 0.9. Maybe something to revisit in a few months.
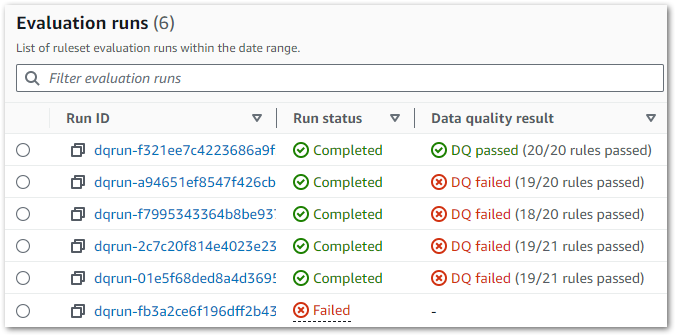
Run History & Reporting
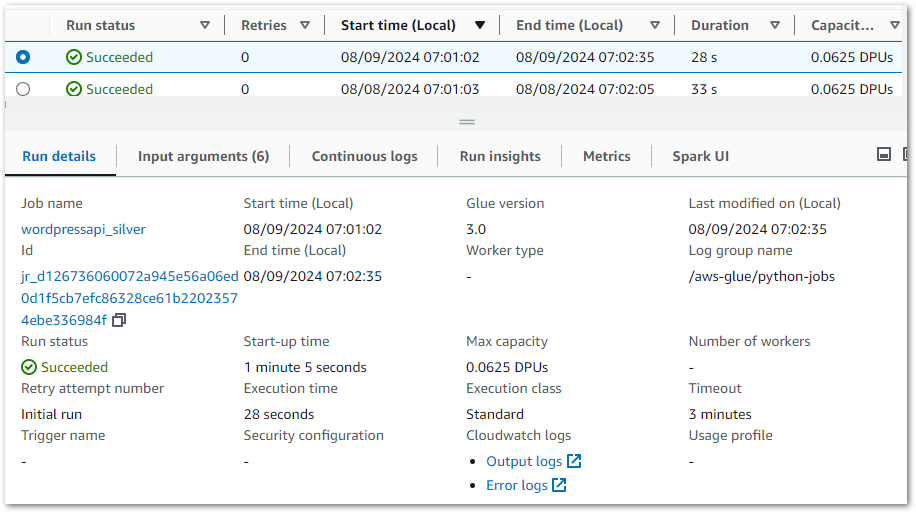
So now all my rules are working, what benefits do I get? Firstly, AWS Glue shows the job’s run history including status, result and start/stop times:
Each run is expandable, showing details like duration, overall score and each check’s output. Results are also downloadable – in testing this gave me an unreadable file but adding a JSON suffix let me view the contents:
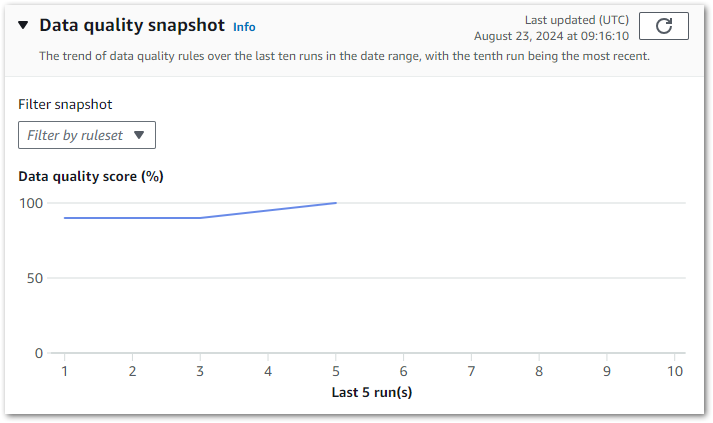
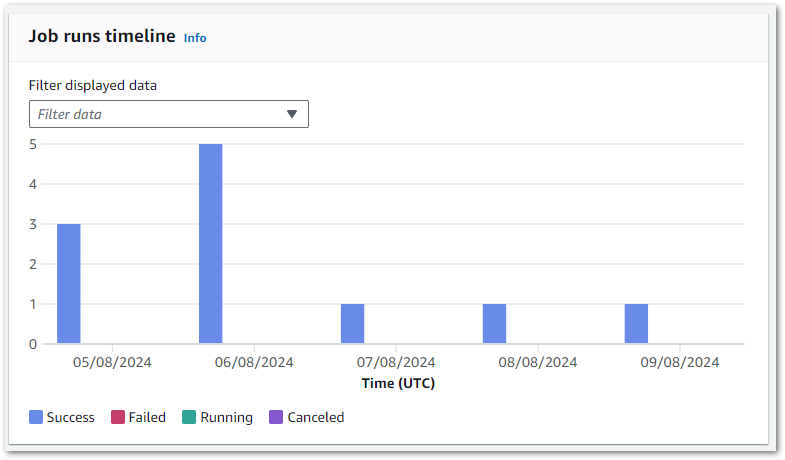
Finally, there’s a snapshot chart showing the results trend of the last ten runs:
Although not downloadable, this can still be screen-grabbed and used to certify the data’s quality to stakeholders. Additionally, AWS has documented a visualisation solution using Lambda, S3 and Athena.
Additional Data Quality Ruleset
With the silver-statistics_pages ruleset testing complete, I added a second dataset check before I moved on. This ruleset is applied to silver-posts.
The checks are very similar to silver-statistics_pages in terms of rules and criteria. So in the interests of space I’ve committed it to my GitHub repo.
Now, let’s add my Glue Data Quality checks into my WordPress pipeline.
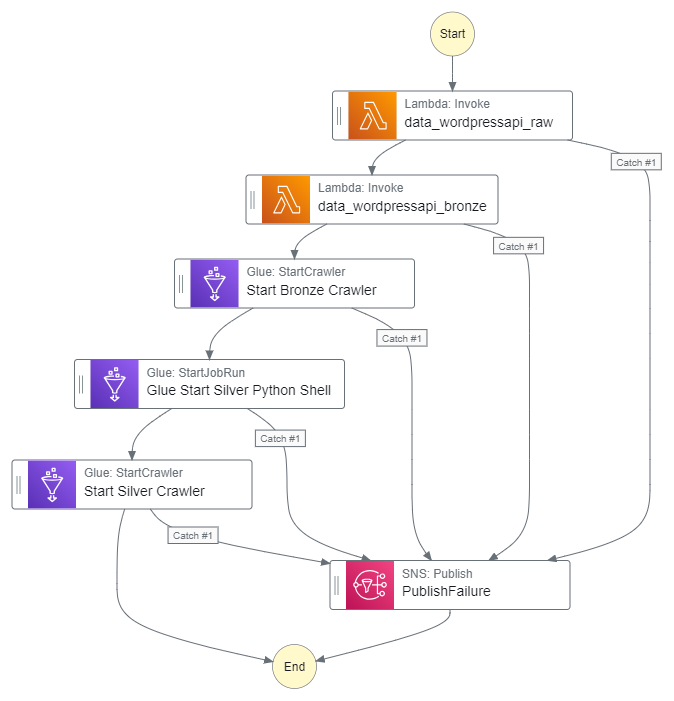
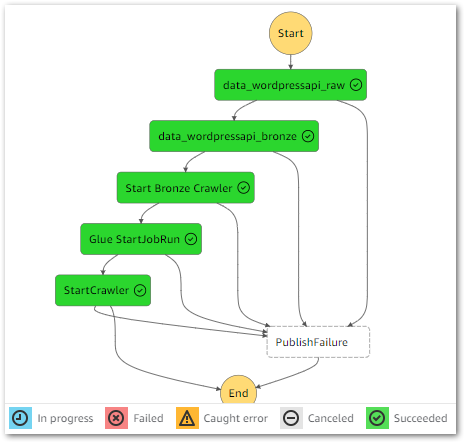
As a quick reminder, here’s how the Step Function workflow currently looks:
This workflow controls the ingestion, validation, crawling and ETL processes associated with my WordPress API data. I’ll insert the quality checks between the Silver ETL job and the Silver crawler.
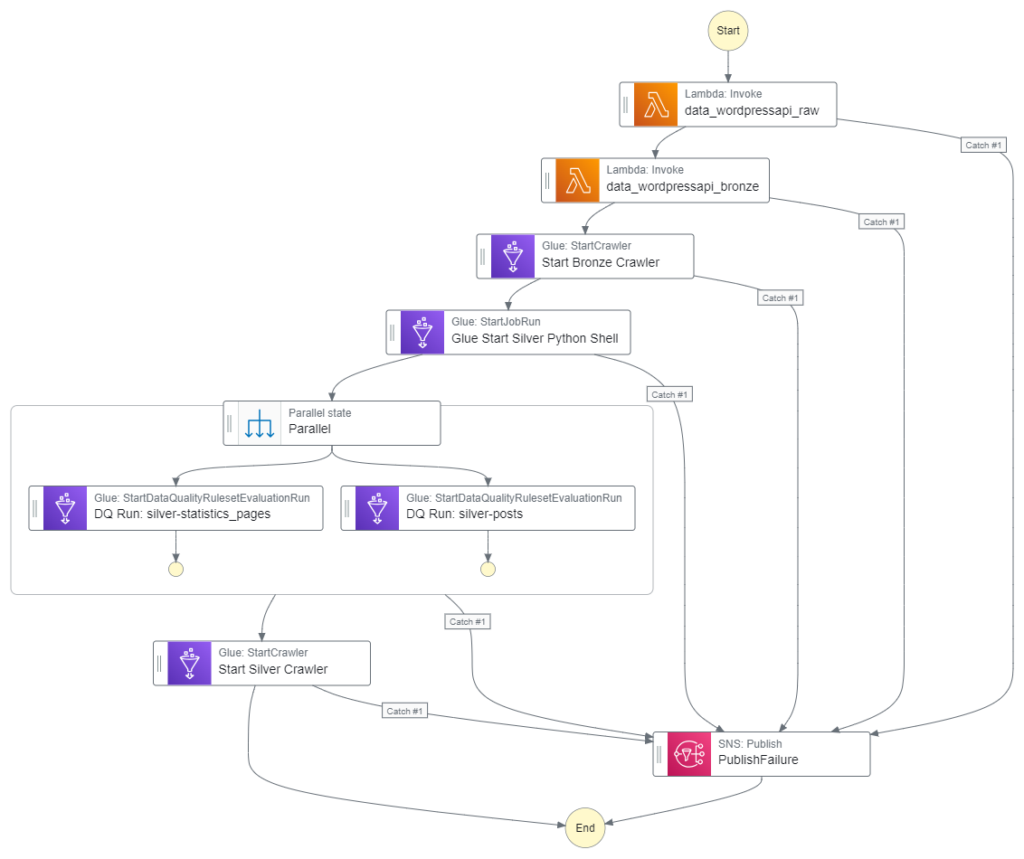
Because the TableName parameter is different for the silver-posts checks, each check needs a separate action. However, I can use a Parallel state because both actions can run simultaneously. This will take full advantage of AWS’s systems, yielding faster execution times for my workflow.
Here is how my Step Function workflow looks with these changes:
Testing time! My workflow needs new IAM permissions to perform its new tasks. These are:
glue:StartDataQualityRulesetEvaluationRun
This lets the workflow start the silver-statistics_pages and silver-posts Data Quality jobs.
iam:PassRole
A Glue Data Quality job must assume an IAM role to access AWS resources successfully. Without iam:PassRole the workflow can’t do this and the check fails.
glue:GetTable
The workflow must access the Glue Data Catalog while running, requiring glue:GetTable on the desired region’s Data Catalog ARN to get the required metadata.
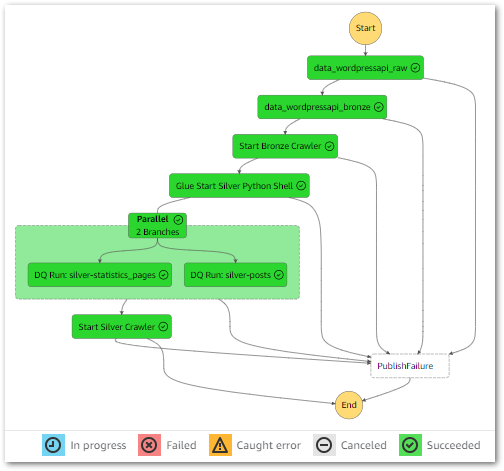
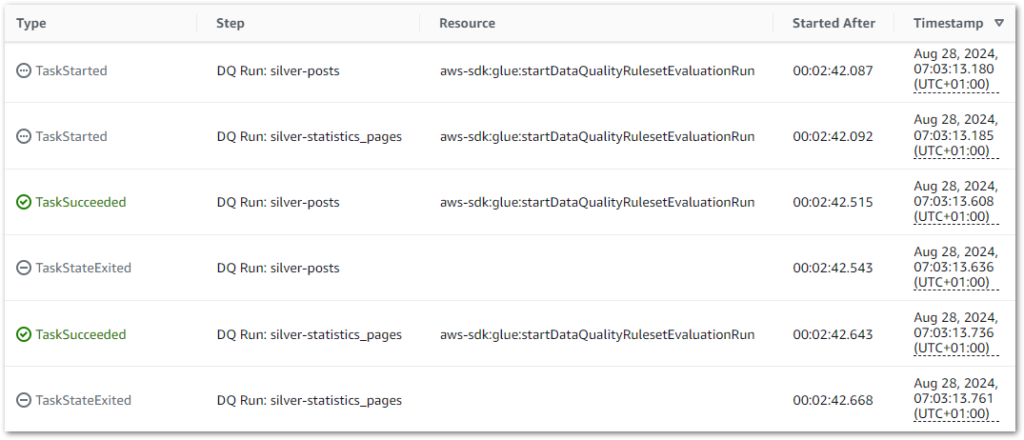
With these updates, the workflow executes successfully:
During the parallel state, both Data Quality jobs successfully start and finish within milliseconds of each other instead of running sequentially:
Cost Analysis
In this section, I examine my costs for the updated Step Function workflow.
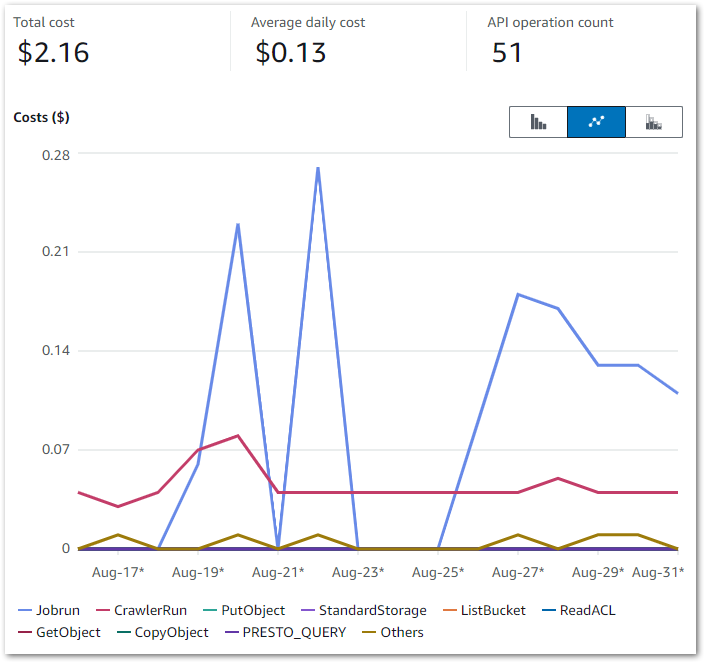
This Cost Explorer chart runs from 16 August to the end of August. It is grouped by API Operation and excludes some APIs that aren’t part of this workload.
Some notes:
I was experimenting with Glue Data Quality from 19 August to 22 August. This period generates the highest Glue Jobrun costs – $0.23 on the 20th and $0.27 on the 22nd.
The silver-statistics_pages ruleset was added to the Step Function workflow on the 26th. The silver-posts ruleset was then added on the 27th.
The CrawlerRun daily costs are usually $0.04, with some experiments generating higher costs.
My main costs are from Glue’s Jobrun and CrawlerRun operations, which was expected. Each ruleset costs around $0.09 a day to run, while each crawler continues to cost $0.02 a day. Beyond that I’m paying for some S3 PutObject calls, and everything else is within the free tier.
In this post, I used AWS Glue Data Quality checks and rulesets to apply bespoke veracity checks to my WordPress datasets.
I think AWS Glue Data Quality is a very effective veracity tool. The simple syntax, quick execution and deep AWS integration offer a good solution to a core Data Engineering issue. It’s great that datasets can be compared with other datasets in the Glue Data Catalog, and the baked-in reporting and visuals make Glue’s findings immediately accessible to both technical engineers and non-technical stakeholders. I look forward to seeing what future Glue Data Quality releases will offer!
If this post has been useful then the button below has links for contact, socials, projects and sessions:
Last time I worked on my WordPress AWS data pipeline, I produced my Bronze layer data and created a Glue Crawler to derive the schema of the Bronze S3 objects. It’s now time to start cleaning that data to prepare it for reporting, aggregation and consumption.
I’m also currently studying for the AWS Certified Data Engineer – Associate certification. While revising for this I learned the capabilities of the AWS Glue ETL Job Script Editor, and it seemed an ideal fit for my Silver ETL process. So I decided to make a post out of it and see how things went!
Firstly, I’ll examine the AWS Glue ETL Job Script Editor and how it will benefit my Silver ETL process. Then I’ll define the architecture of the Silver ETL job and how it fits into the existing data pipeline. Next, I’ll script and test the job. Finally, I’ll integrate it into the pipeline and explore the job’s costs.
Glue ETL Job Script Editor
This section examines the AWS Glue ETL Script Editor and Python Shell and considers some of Python Shell’s benefits and limitations.
Script Editor & Python Shell
Script Editor is a feature of AWS Glue. It offers serverless Spark, Ray and Python shells, enabling data transformation, preparation and cleaning with no infrastructure management. Scripts can be both uploaded and created from scratch, and version control is configurable to several Git services.
This post focuses on AWS Glue Python Shell. Introduced in 2019, Python Shell jobs suit small to medium-sized tasks as part of an ETL workflow.
Python Shell Pros
This section examines some of Python Shell’s benefits.
Low Cost
Python Shell jobs are the cheapest of the Glue job types to run. Glue charges are based on data processing units (DPUs). A single standard DPU currently provides 4 vCPU and 16 GB of memory. While regular Glue ETL jobs using Apache Spark need at least 2 DPUs, Python Shell jobs default to using only 1/16 (or 0.0625) DPU!
This can also be extended to 1 DPU, resulting in faster completion times. Like AWS Lambda, charges accrue based on resource usage and duration. So increased resource allocation can potentially create further savings.
This section was correct as of August 2024 – the latest pricing data is on the AWS Glue pricing site.
Low Barrier To Entry
Python Shell jobs offer accessibility for those from a scripting background. When creating a new script in the console, users only need to choose the engine (in this case Python) and whether the script is being uploaded or created fresh. And that’s it! No configuring interpreters, environments or dependencies.
Python Shell jobs also integrate with other AWS services. They can easily connect to data sources like S3, RDS and DynamoDB. They can be automated with Glue Workflows and Triggers. IAM can also control access to both the Python Shell job and the AWS services it interacts with.
Included Python Libraries
AWS Glue Python Shell includes a variety of built-in Python libraries that are useful for ETL tasks. These libraries cover a range of functionalities such as data processing, machine learning, and interacting with AWS services.
This AWS post has a full table of included libraries and their versions. Additional libraries can be installed and imported using PIP.
Some people will quickly see issues with this list though…
Python Shell Cons
This section examines some of Python Shell’s limitations.
Outdated Python Versions & Libraries
While the included libraries are welcome, they are also quite outdated. For example, boto3‘s included version is 1.21.21 while the current version is 1.34.150. pandas is at 1.4.2 in the table and 2.2.2 online.
This is likely due to the supported Python versions – currently Python 3.6 and Python 3.9. Now, while Python 3.9 isn’t out of support until October 2025, it was released back in October 2020 and has had three major upgrades since. Worse, Python 3.6 ended life at Christmas 2021!
With the Data Engineer Associate certification drawing attention to various AWS data services, it’s a shame that this feature is so far behind. This would be a great modernisation tool for importing legacy Python scripts into Glue, but the last feature update was in 2022 and it’s really starting to lag behind now.
No Visual Editor
Yes I know it’s a script editor but hear me out.
Let’s briefly segue to AWS IAM. In the early days, updating IAM policies had the potential of losing afternoons to missing braces or errant commas. There was no native AWS validation tooling and the whole thing felt like a dark art for those less experienced.
This transformed the IAM policy-writing process. The guesswork was gone – new policies could be written using dropdowns and checkboxes. And AWS would generate the same code each time, in the same way and to the same standard.
In today’s AWS console, IAM can be administrated both visually and as JSON. Updates made in the visual editor reflect in the code in real-time, and vice versa. And the IAM IDE immediately flags syntax issues, unclosed keypairs and whatnot.
This interface would work so well with Glue Script Editor. It would simplify and encourage using Script Editor, creating standardised code by default and reducing development time. No more syntax violations, verbose comments or missing dependencies – AWS could handle all that.
This doesn’t even need AI – it would just be procedural code generation. Something like selecting awswrangler from a dropdown list, then selecting an S3 location to read or write and a file type to expect. Or even a list of code snippets for the included libraries. These features could all lighten the dev load.
Limited IDE
Let’s consider AWS Lambda’s IDE:
Its benefits include:
Code autocompletion
Integrated testing
Integrated monitoring
And tons of other user-focused functionality. Conversely, this is the Glue Script Editor IDE:
Hmm.
Now don’t get me wrong – I’m not asking for Lambda Lite. But something a bit more than Notepad would be nice. AWS are currently making a massive deal of Amazon CodeWhisperer and Amazon Q Developer‘s autocomplete actions, but here pandas isn’t even suggested when I type import pan. And it’s an included library!
The obvious solution is to just use Lambda. But Glue Script Editor offers a sweet spot where it runs custom Python while operating entirely within the AWS Glue service. This is helpful for features like Glue Triggers and Workflows that can’t currently trigger Lambda functions. It’s also helpful with AWS Organisations, where using Glue Script Editor for Python ETL can enable SCPs that entirely block access to AWS Lambda for data-centric accounts.
So Why Use It?
So are Glue Python Shell jobs worth considering with these limitations? Definately! There are several use cases favouring them:
Legacy ETL jobs that either can’t use recent Python versions and libraries, or simply don’t need them.
Simple, lightweight tasks that don’t require the more advanced (and expensive) features of Apache Spark or Ray.
Tasks that need to run quickly, as Python Shells have faster startup times than the Spark environments used by regular Glue ETL jobs.
Long-running ETL tasks unsuitable for AWS Lambda, as Python Shell jobs can run for up to 48 hours compared to Lambda’s 15 minutes. Thanks to Yan Cui‘s blog for that one!
For my requirements, a Python Shell job makes sense because I’m doing simple transformations on small volumes of data.
Architecture
This section examines the architecture of my proposed solution. Much of this architecture is similar to the Bronze layer. I’ll examine the new Silver ELT job, followed by the updated data pipeline Step Function workflow.
Glue Silver ETL Job
Firstly, this is the Glue Silver ETL job:
While updating CloudWatch Logs throughout:
Silver Glue ETL job extracts data from wordpress-api Bronze S3 objects and performs Python transformations.
Silver Glue ETL job loads the transformed data into Silver S3 bucket as Parquet objects.
Step Function Workflow
Next, the updated Step Function workflow:
While updating the workflow’s CloudWatch Log Group throughout:
An EventBridge Schedule executes the Step Functions workflow.
Run Succeeds: Update Glue Data Catalog. Run Glue Silver ETL job.
Glue Silver ETL job runs.
Run Fails: Publish SNS message. Workflow ends.
Run Succeeds: Workflow ends.
An SNS message is published if the Step Functions workflow fails.
Silver ETL Job
In this section, I create the Silver ETL Python script for the AWS Glue Script Editor. Firstly I’ll define the script’s requirements. Next, I’ll translate them into Python code, and finally I’ll create the ETL script and upload it to Git.
Requirements
Firstly, let’s define the requirements for this data pipeline layer. So what does a typical Silver ETL process involve?
Databricks defines the Silver layer as cleansed and conformed data:
In the Silver layer of the lakehouse, the data from the Bronze layer is matched, merged, conformed and cleansed (“just-enough”) so that the Silver layer can provide an “Enterprise view” of all its key business entities, concepts and transactions. (e.g. master customers, stores, non-duplicated transactions and cross-reference tables).
Because my data source is a WordPress MySQL database, most of the cleansing and conforming work I’d expect to do has already been done there! That said, there’s data that I definitely won’t need, as well as other transformations I can apply to help downstream reporting.
Some of the following transformations can be done at the SQL reporting level with date and string functions. However, these add repetitive load and complexity to queries, which can be avoided by some cleaning transformations. Roche’s Maxim of Data Transformation applies here:
Data should be transformed as far upstream as possible, and as far downstream as necessary.
The Silver layer transformations I’m doing here are:
Column Removal
Many columns are empty or unneeded, so now is the time to remove them. This will reduce the data held in the Silver objects, making them cheaper to store and faster to query.
My script uses the pandas.DataFrame.drop function to remove columns by specifying column names. Here, a term_order column is dropped from the DataFrame df:
Python
df = df.drop(columns=['term_order'])
Date Splitting
Dates are tough to analyse and don’t aggregate well, as each date is effectively three different data points in one field. Splitting dates into years, months and days improves data bucketing, query granularity and time series analytics.
My script uses the pandas to_datetime function to convert scalar, array-like, Series or DataFrame/dict-like objects to pandas datetime objects.
Here, values in the date column of the DataFrame df are converted from strings to datetime objects and stored in a new date_todate column. Next, the year attribute of each date_todate column object is extracted and stored in a new date_year column. Finally, the same happens for month and day attributes:
Some columns use HTML character entity names for reserved characters. For example, & in place of &. This is great for rendering HTML but not great for analytics.
My script uses the str.replace string method to return a copy of each string with all occurrences of the specified substring replaced by a new one. Here, all instances of & amp; in the name column are overwritten with &:
Python
df['name'] = df['name'].str.replace('& amp;','&')
So that’s the transformations. What else is the script doing?
Python Script
Most of the Silver script processes are similar to the Bronze script ones, including:
Logging
Getting parameters
Accessing S3 objects
So most functionality is reused from my Bronze Lambda function, which is fully documented in this post. To summarise the imports:
Python
import logging # Loggingimport boto3 # AWS Interactionsimport botocore # AWS Exceptionsimport awswrangler as wr # S3 Interactionsimport pandas as pd # Data Manipulationfrom botocore.client import BaseClient # AWS Type Hints
Some changes have been made for the Silver script:
Parameters, object names and logs have been updated from Bronze to Silver:
New functionality identifies the AWS AccountID the script is running in:
Python
# Get & display AWS AccountIDidentity = client_sts.get_caller_identity()account_id = identity['Account']logging.info(f"Starting in AWS Account ID {account_id}")
This is more of a sanity check for me – I have several AWS accounts and want to check I’ve accessed the right one!
A test that stops the current loop interaction if the object name doesn’t match one of the expected ones:
Python
# Check if object is mapped and bypass if not.if object_name notin {'posts', 'statistics_pages', 'term_relationship', 'term_taxonomy', 'terms'}:logging.warning(f'{object_name} is not currently mapped. Skipping transform...')object_count_failure +=1continue
Finally, I wrote a new function for my Silver transformation logic. This isn’t included here (although it is in my repo) because it’s long. Very long! My first thought was to decouple the ETL processes from each other and write separate scripts for each object. So 5 in total.
However, Python Shell jobs are billed per second with a 1-minute minimum. So 5 jobs = 5 minutes billed. But the job only takes around 60 seconds to process all five objects! I’d have run up 5 times the usage and 5 times the cost for no real benefit.
Testing was quick because it was effectively repeating the Bronze script tests with new parameters. After successfully testing the script locally, it’s time to get it working in AWS!
Uploading & Testing
In this section I upload my Silver ETL script, integrate it with AWS Glue Script Editor and AWS Step Functions and test everything works as expected.
Creating The Python Shell Job
Firstly, let’s get my script into AWS Glue. There are several ways of doing this. If the script is uploaded to S3 then AWS can create a Glue ETL job with the AWS CLIcreate-job command:
Scripts can also be pulled from Git repositories. Here I’ll create my Silver ETL job in the Glue Script Editor console. This creates a new Python script in an S3 bucket location of s3://aws-glue-assets-[AWSAccountID]-[Region]/scripts/.
Next, the new job needs an IAM role with appropriate permissions for the AWS services the script interacts with. Other parameters, including maximum DPU, job timeout value and Python version, can also be set. In addition, Glue Data Quality checks are also supported. And, once saved, the Glue job can have a schedule applied.
Testing Job Execution
AWS Glue records data for each job execution and publishes extensive details and logs:
Glue stores details about the job and Python environment, and logs are published and stored in Amazon Cloudwatch.
And so begins the testing! Initially, I was getting one of my own Python boto3 exceptions:
ValueError: No SNS topic returned.
Easy to fix. This IAM policy was based on the same one that my Bronze Lambda function uses. But the Silver ETL script uses different AWS resources so some IAM policy ARNs need to change. Specifically, the Silver ETL job’s IAM role needs to allow:
ssm:GetParameter on the required Parameter Store parameters.
sns:Publish on the required SNS topics.
s3:GetObject on the data-lakehouse-silver/wordpress_api/* objects.
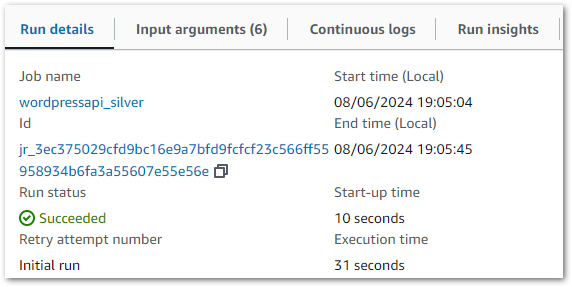
With these changes, the Silver ETL job runs perfectly and creates new objects in the Silver S3 bucket:
With the Glue job running and S3 object creation verified successfully, it’s time to validate the data.
Data Integration & Validation
Validating the data involves two processes:
Integrating the data into the Glue Data Catalog.
Querying the data with Amazon Athena.
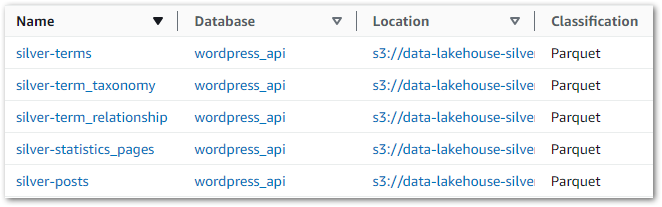
There are several ways to update the Glue Data Catalog, and here I’ll create a new Glue Crawler using a similar setup to my Bronze Crawler. This time the crawler is reading objects from the Silver S3 bucket instead of the Bronze one, and the new Glue Data Catalog tables are prefixed with silver- instead of bronze-.
The Silver crawler creates these new tables in the Glue Data Catalog’s wordpress_api database:
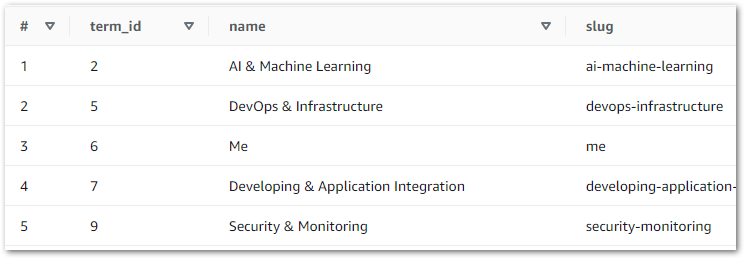
This gives Athena visibility of the tables, enabling data validation via SQL query execution. Querying wordpress_api.silver-terms shows the removed column and updated strings:
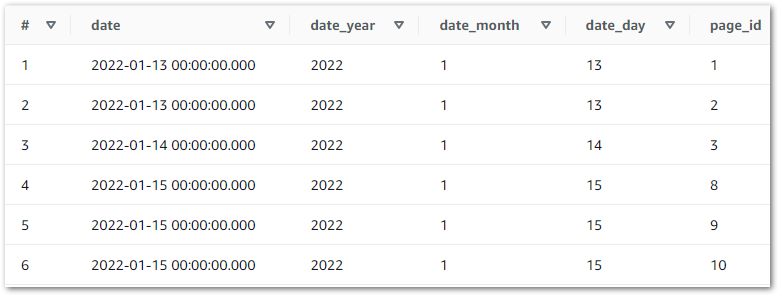
And querying wordpress_api.silver-statistics_pages shows the split dates:
Looks good! Now that everything has been validated, let’s add these steps to the WordPress Data Pipeline.
Step Function Update
The WordPress Data Pipeline Step Function workflow that I started back in March continues to grow. There’s a new job and a second crawler to add to it now!
The Silver crawler is added in the same way as the Bronze one (including the IAM changes) so let’s focus on adding the new Glue Python Shell ETL job.
Adding Glue ETL jobs to a Step Function workflow is well documented The task uses the StartJobRun Glue API action under the hood and has an optimized integration that enables the .sync integration pattern. Enabling this means the Step Functions workflow waits for the StartJobRun request to complete before progressing to the next state.
However, my workflow currently lacks IAM permissions to run the Silver Glue ETL job. So I make a new IAM policy that allows the glue:StartJobRun action on the Silver Glue ETL job and attach it to the workflow’s IAM role:
Let’s execute the Step Function workflow and check it works.
Step Function Test
Upon execution, everything works as intended. The new StartGlueJob action is triggered and the Glue ETL job is successful:
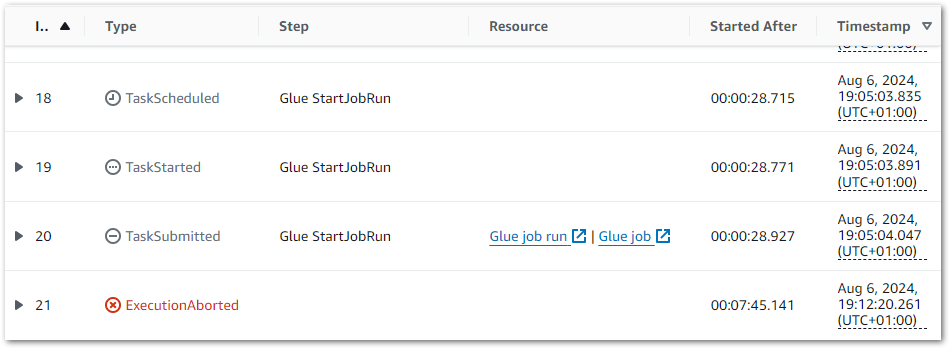
But the Step Function doesn’t transition to the next step. In fact it continued running to the point I had to stop it myself after several minutes:
So what’s going on? I asked Amazon Q about this behaviour, and in its response were the following points:
Step Functions uses a “sync” integration with AWS Glue, which means it relies on polling the status of the Glue job using the GetJobRun API call.
The polling schedule is designed to be once per minute for the first 10 minutes, and then every 5 minutes thereafter. This is to avoid excessive API calls to Glue.
This is an expected behavior in case of .sync integration with AWS Glue. Service integrations that use the .sync pattern require additional IAM permissions where Step Functions will make use of a managed Eventbridge rule to monitor the status of the job. However, AWS Glue does not support Eventbridge integration and thus, Step Functions polls the job status using the GetJobRun API call to fetch the status of the job.
This made things clearer. When Step Functions starts a Glue ETL job using a StartGlueJob action with optimized integration, Step Functions determines that job’s status (and thus when to transition to the next action) by calling Glue’s GetJobRun API.
However, my workflow’s IAM role doesn’t have permission to do that! And because Step Functions can’t determine the ETL job’s status, it doesn’t know that the job has finished and the next state transition never happens! Everything stops!
This is resolved by adding the glue:GetJobRun action to the workflow’s IAM policy:
This time, the Glue GetJobRun API calls are successful. The Step Functions workflow validates that the ETL job has finished, moves to the next state as intended and ultimately completes successfully:
Thanks Amazon Q!
Costs
Finally, let’s look at the costs for my Glue Script Editor Silver ETL Job resources.
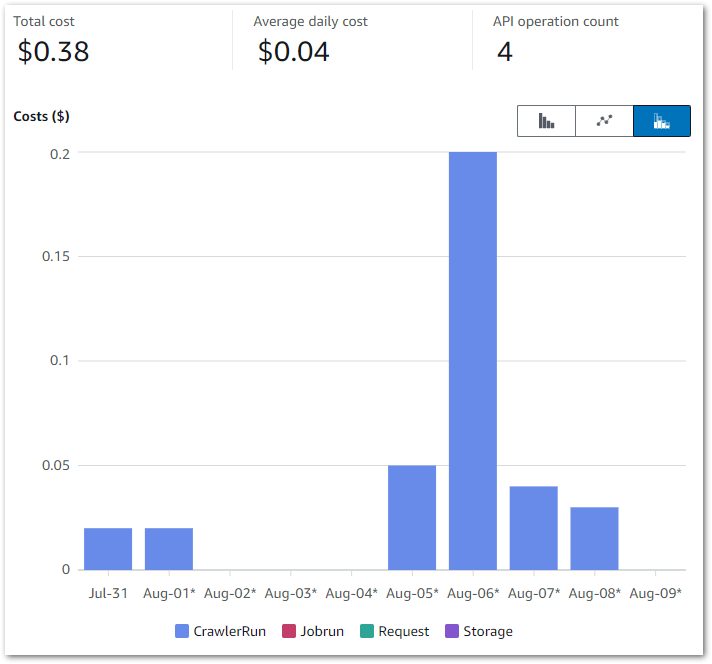
This graph shows all Glue API costs between 2024-07-31 (first AWS job execution) and 2024-09-09:
Of the $0.38:
$0.37 is the CrawlerRun API for the two Glue Crawlers I’m running.
$0.01 is the Jobrun API for the 15 job runs between 2024-07-31 and 2024-09-09.
So all things considered, very manageable!
Summary
In this post, I created my WordPress data pipeline’s Silver ETL process using Python and the AWS Glue ETL Job Script Editor.
I found the Script Editor jobs very useful. They offer Lambda’s benefits of scalability, managed infrastructure and integration with other AWS services, combined with data-centric libraries and features that make it easier to hit the ground running development-wise. It has clear limitations and could do with some AWS TLC, but it was a good fit here and rivals Lambda for some future ETL processes I have planned.
If this post has been useful then the button below has links for contact, socials, projects and sessions: