In this post, I use the principles in “How To Solve It” by George Pólya to diagnose and fix my broken kitchen tap. Yes – really.
Table of Contents
- Introduction
- How To Solve It
- George Pólya
- Applying The Principles
- Principle 1: Understanding The Problem
- Principle 2: Devising A Plan
- Principle 3: Carrying Out The Plan
- Principle 4: Looking Back
- Summary
Introduction
Bit of a change this time. Let me set the scene.
It’s time to top up Wolfie’s water bowl, so to the kitchen sink we go. Two unexpected events happen when the tap is turned on:
- The water flow goes mental and starts spraying everywhere.
- Something gets launched out of the tap into the water bowl:

My first thought is that the tap is broken and that I’ll need to buy a new one. And then get a plumber to fit it. Great.
But wait. Last year I fixed some broken panes in our greenhouse. This year I’ve built a potting bench, fixed a leaky water butt and mounted a shower rail. Is this a problem I can solve?
This Doesn’t Sound Like Technology
True. It is, though, a chance to write a post I’ve fancied doing for a while. And this set of circumstances was too compelling to pass up.
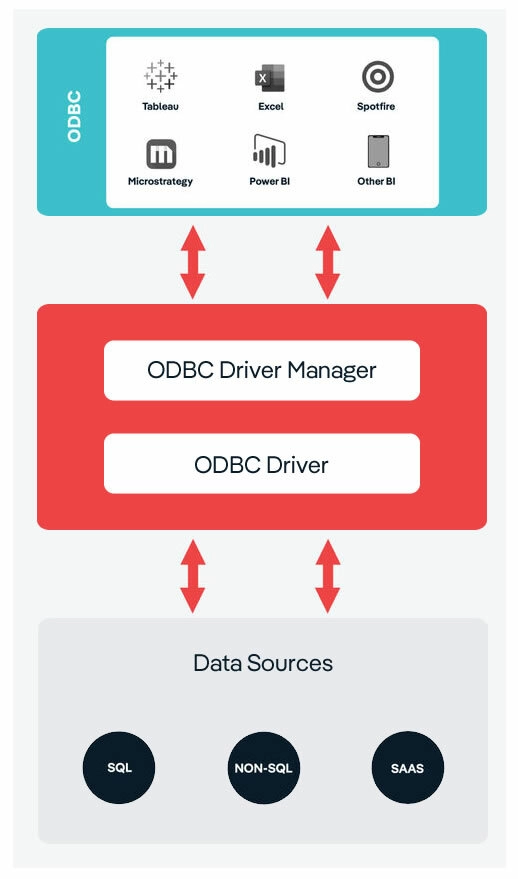
Last year I became aware of a book called “How To Solve It” by George Pólya. The recommendation included a chart based on the book, similar to this one:

What struck me was how close these steps were to the Systems Development Life Cycle I was taught at college. My interest was piqued.
Around the same time, I was getting to grips with my new Data Engineer role. Since then, I’ve used the “How To Solve It” principles to help me complete work both for my role and for this blog.
Now, faced with a new unfamiliar situation, I can demonstrate how the “How To Solve It” principles can be applied beyond mathematics. In this case I’m fixing a broken tap, but this could just as easily be a Python bug, a poorly performing SQL query or an AWS authentication issue.
Here is my plan:
- Firstly, I’ll examine the “How To Solve It” book.
- Secondly, I’ll look at the author of the book – George Pólya.
- Then I’ll look at each of the George Pólya principles, relating them to the broken tap problem I want to solve.
Let’s start with the book.
How To Solve It

‘A superb book on how to think fresh thoughts … A walk inside Pólya’s mind as he builds up maxims on how to comprehend a problem, how to build up a strategy, and then how to test it.’
David Bodanis, Guardian
‘Everyone should know the work of George Polya on how to solve problems’
Marvin Minsky
How To Solve It can be bought on Penguin’s website.
History
How To Solve It was written in 1945 by George Pólya. Since then, the book has stayed in print and has been translated into over a dozen languages. It has sold more than 1 million copies, making it one of the most widely circulated mathematics books in history.
Four Principles
How To Solve It explains in non-technical terms how to think about invention, discovery, creativity and analysis. Central to this are four principles:
- First. You have to understand the problem.
- Second. Find the connection between the data and the unknown. You may be obliged to consider auxiliary problems if an immediate connection cannot be found. You should obtain eventually a plan of the solution.
- Third. Carry out your plan
- Fourth. Examine the solution obtained.
The book also poses several questions for each principle. They aim to stimulate thought and produce the answers needed to satisfy each principle.
These can be seen in the below image from the book’s first edition:

They are also available as text from the University of Utah’s summary of 1957’s second edition.
Although How To Solve It was written with mathematics in mind, the book’s principles have been applied to additional disciplines over the decades. Pólya seems to take great care not to limit the scope of How To Solve It, speaking of problems in general terms throughout the book.
One such example is this extract:
A great discovery solves a great problem but there is a grain of discovery in the solution of any problem. Your problem may be modest; but if it challenges your curiosity and brings into play your inventive faculties, and if you solve it by your own means, you may experience the tension and enjoy the triumph of discovery.
“How To Solve It” – George Pólya
How To Solve It remains in high regard to this day. The Math Sorcerer produced this video in July 2022, and his affection for the book is clear.
Sources
Next, let’s look at the book’s author – George Pólya.
George Pólya

George Pólya (December 13 1887 – September 7 1985 aged 97) was a Hungarian mathematician. He was a professor of mathematics from 1914 to 1940 at ETH Zürich in Hungary, and from 1940 to 1953 at Stanford University in North America having moved there during World War 2.
After retiring from Stanford, Pólya remained active in his field. He continued his association with Stanford as Professor Emeritus well into his 90s and taught a course in their Computer Science Department in 1978.
Works
In pure mathematics, Pólya made important discoveries in fields including probability, real and complex analysis, combinatorics, geometry, number theory and mathematical physics.
Several of his discoveries bear his name, including:
- Pólya Criterions in Probability Theory.
- Pólya Peaks in Complex Function Theory.
- Pólya Enumeration Theorem in Combinatorics.
Pólya also authored and contributed to numerous books and articles throughout his life, a selection of which can be seen on Wikipedia.
Recognition
Pólya was well-regarded by his peers and awards given to him included:
- Membership of the American National Academy of Sciences, the American Academy of Arts and Sciences and the California Mathematics Council.
- Honorary Membership of the Hungarian Academy Of Sciences, the London Mathematical Society and the Swiss Mathematical Society.
- Distinguished Service Award from the Mathematical Association Of America, the citation for which included comments like:
“He has given a new dimension to problem-solving by emphasizing the organic building up of elementary steps into a complex proof, and conversely, the decomposition of mathematical invention into smaller steps.”
and:
“Problem solving a la Polya serves not only to develop mathematical skill but also teaches constructive reasoning in general.”
Sources
There is much more to know about Pólya. The following links detail his life, works and legacy in far greater detail:
- George Pólya article on Wikipedia.
- George Pólya biography on MacTutor.
- George Pólya obituary from the Los Angeles Times.
Now I’m going to apply the George Pólya principles to my broken tap!
Applying The Principles
In the following sections, I will apply each George Pólya principle from How To Solve It to my tap problem. In each section I will:
- Quote each principle in full.
- State the supporting questions that I’ll answer.
- Relate these to my tap problem.
Principle 1: Understanding The Problem
First. You have to understand the problem.
“How To Solve It” – George Pólya
- What is the unknown? What are the data? What is the condition?
The Unknown
The unknown is what I want. Here, I want to restore the tap’s original flow rate.
The Data
The data is the information available. This is what was expelled from the tap:
Other data:
- Water was still flowing from the tap.
- The flow of water was under more pressure than before.
The Condition
The condition is the link between the unknown and the data. Here, whatever has come out of the tap has changed the water’s flow but hasn’t obstructed it.
Principle 2: Devising A Plan
Second. Find the connection between the data and the unknown. You may be obliged to consider auxiliary problems if an immediate connection cannot be found. You should obtain eventually a plan of the solution.
“How To Solve It” – George Pólya
- Do you know a related problem? Do you know a theorem that could be useful?
- Here is a problem related to yours and solved before. Could you use it? Could you use its result? Could you use its method?
Related Problems
I searched Google for the phrase “kitchen tap water flow changed”. There was an immediate common thread in the results:

The Estes Services link gave a useful definition of an aerator:
“The aerator on your faucet is a mesh screen and covers the water outlet. The aerator catches minerals and other debris in your pipes. It also helps save water by introducing air into the water stream.”
“How to Fix Low Water Pressure in Kitchen” on Estes
Getting somewhere! This led me to “Everything you Need to Know About Tap Aerators” on TapWarehouse, which includes this:
“They save you water by adding oxygen to the flow (and that means saving pennies) and reduce splashing around the bowl of the basin.”
“Everything you Need to Know About Tap Aerators” on TapWarehouse
Mesh screen? Reduced splashing? This definitely sounded like the right area!
Solved Problems
At this point, what came out of the tap sounded very much like an aerator. However, there’s no cleaning something that’s disintegrated, so it was time for a replacement.
TapWarehouse to the rescue again:
“If your existing tap already has an aerator, simply turn it anticlockwise until it’s unscrewed from the tap. Then, simply screw in the new aerator until it’s secure, being careful not to screw it too tightly.”
“How can I Install a Tap Aerator?” on TapWarehouse
TapWarehouse also gave advice on aerator types. There are male and female aerators depending on the tap. There are also various aerator sizes ranging from 16mm to 28mm.
Planned Solution
Based on this research, the solution needed the following steps:
- Remove the broken aerator.
- Confirm the aerator type.
- Confirm the aerator size.
- Buy a replacement aerator.
- Fit the replacement aerator.
- Test the replacement aerator.
Principle 3: Carrying Out The Plan
Third. Carry out your plan.
“How To Solve It” – George Pólya
- Carrying out your plan of the solution, check each step. Can you see clearly that the step is correct?
Time to remove the broken aerator! Straight into a problem. It wouldn’t budge.
Fortunately, there’s a DIY StackExchange! Advice ranged from WD-40 to vinegar to a hammer and chisel (!), but in the end I used my heat gun on the aerator and removed it with pliers.
I then determines that I needed a 24mm male aerator as a replacement. One trip to B&Q later and:

Fitting the new aerator was a simple matter of screwing it on.
Principle 4: Looking Back
Fourth. Examine the solution obtained.
“How To Solve It” – George Pólya
- Can you check the result?
BEHOLD:

Summary
In this post, I used the principles in “How To Solve It” by George Pólya to diagnose and fix my broken kitchen tap. I applied each of the Pólya principles to my problem, and was able to solve it by answering the relevant questions and doing some investigation with the knowledge gained.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~