
AWS has announced changes to its Free Tier. In this post, learn what’s changed, what’s included, and what it means for new and returning users.
Table of Contents
Introduction
Out of the blue on 11 July, AWS announced fundamental changes to the AWS free tier:
AWS accounts launched before 15 July retain their current free tier duration, allowances and terms and conditions. New AWS accounts after this date now offer two options – a Paid Plan and a Free Plan.
For those familiar with AWS, the Paid Plan resembles the AWS we know and are used to. This plan is designed for production applications, grants access to all AWS services and features, and provides payment options like pay-as-you-go and savings plans.
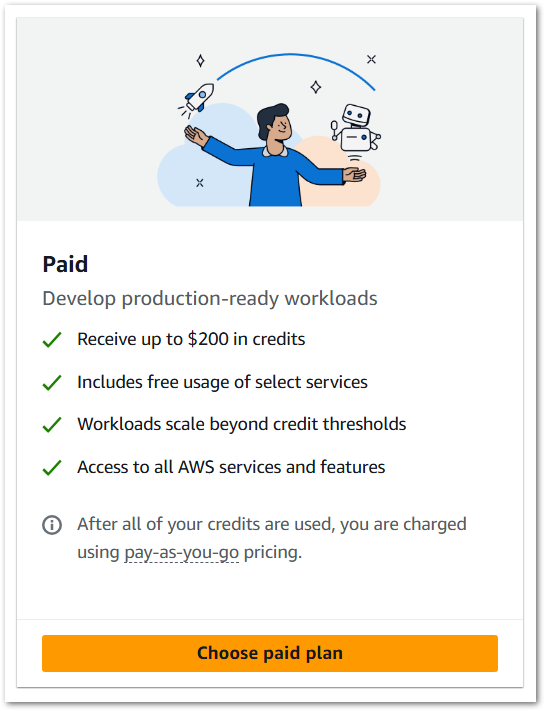
The new Paid Plan also includes the existing always-free services, including:
- AWS Lambda: 1 million requests/month
- Amazon DynamoDB: 25GB storage
- Amazon S3: 5GB standard storage
- And so on
Then there’s the Free Plan:
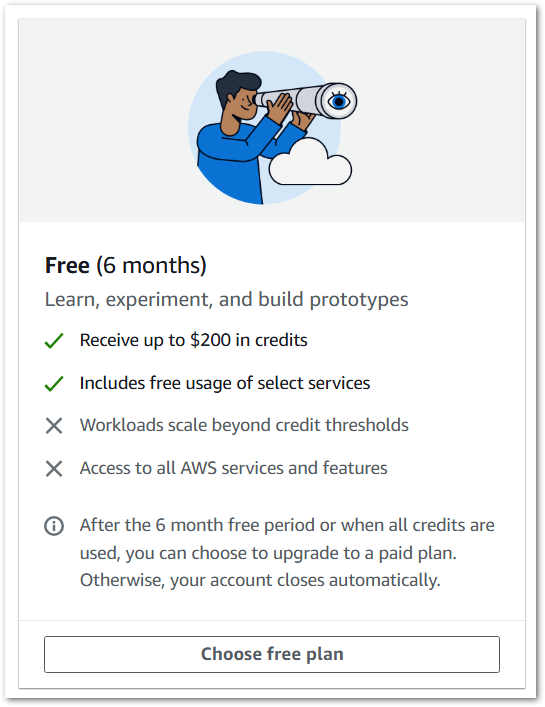
The free plan also includes the always-free services alongside some entirely new aspects, so let’s take a closer look at its main features.
Major Changes
This section examines the main features of the new AWS Free Plan.
Credits
Where previously new users had free tier allowances on several services, they now receive $100 USD in AWS credits at signup.
A further $100 USD credits can be earned by completing activities using foundational AWS services. This includes launching an EC2 instance, creating an AWS Lambda-backed web app and, brilliantly, setting up an AWS Budget cost budget! Incentivising this for new AWS users is long overdue.
Free plan credits expire 12 months after the date of issuance. However, this doesn’t equate to having twelve months of account access…
Account Expiry
With the previous free tier offering, accounts remained open after the free tier period ended. Now there’s an in-built expiry:
Your free plan expires the earlier of (1) 6 months from the date you opened your AWS account, or (2) once you have exhausted your Free Tier credits.
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/free-tier-FAQ.html
When a free plan expires, the account will close automatically and access to current resources and data will be lost. AWS retains the data for 90 days after the free plan’s expiry, after which it will be entirely erased.
Retrieval after this point is possible, but requires an upgrade to a paid plan to reopen the account. Note that this isn’t automatic – users must consent to being charged as part of the upgrade process.
The expiration date, credit balance, and remaining days of a free tier account can be monitored through the Cost and Usage widget in the AWS Management Console Home, or programmatically using the AWS SDK and command line at no cost via the GetAccountPlanState API. AWS will also send periodic email alerts regarding credit balances and the end of the free plan period.
Service Restrictions
Where previously a new account could use most AWS offerings immediately, free plan accounts now have some limitations. This is the AWS rationale:
Additionally, free account plans don’t have access to certain AWS services that would rapidly consume the entire AWS Free Tier credit amount, or hardware purchases.
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/free-tier.html
There’s roughly a 50/50 eligibility split of the AWS service catalogue, with some interesting choices that I’ll go into…
New User Considerations
This section examines considerations of the AWS free tier changes for beginners with no prior AWS experience.
Usage-Linked Closure Is Good…
The new Free Plan stops one of the tales as old as time, where new AWS users join up, try out all their shiny new toys and then get spiked by a massive bill. Or their access keys are exposed and stolen, creating a massive bill. Or they spin up an EC2 instance outside of the free tier and get a massive bill. And so on.
Well now, the user only spends their credits. And when the credits are used up, the account closes. The user loses their free plan, but they don’t lose the shirt off their back. Nor do they have to go to AWS cap in hand.
This also addresses another common concern: “I forgot my account was open, and now it’s been hacked!” Not anymore – accounts will close automatically after six months. This feature also helps limit financial damage from DDoS attacks, exposed credentials and similar risks.
Sounds great, right?
…But Isn’t Infallible
There are circumstances where having account closure linked to a credit balance is less desirable:
- A user builds something that explodes in popularity.
- Online attackers deliberately target an account.
- A user misconfigures a resource.
These circumstances, and others, will quickly eat through the credits and trigger the account’s closure. What would happen in this situation is currently unclear – would AWS hit the brakes immediately? Is there a grace period of any sort? Either way, observability and monitoring are vital – the budget alert is a great start, and CloudWatch is included in the Free Plan.
Potential Credits Confusion
Finally, I feel that there may be potential confusion between the free plan credits that expire in twelve months and the free plan that expires in six months. My interpretation is that free users upgrading to a paid plan after six months will be able to continue using any remaining credits for the following six months.
I feel that some new users will see their account expiry coming up while their credits have over six months remaining, assume the account expiry is wrong and then be surprised when their account shuts. It sounds like AWS will make this as obvious as possible to account owners. I guess we’ll find out on Reddit in six months…
Experienced User Considerations
This section discusses the AWS free tier changes for users with prior AWS experience.
Free Tier Policing
I’ve already seen this ruffle some Internet feathers.
Traditionally, AWS were fairly flexible with new accounts. While officially only one email address can be associated with an account, AWS kinda ignored plus addressing. This allowed users to have multiple free tier accounts, and to start a new account when the free tier on their existing one expired.
Well not any more! AWS make it very clear in their FAQs:
“You would be ineligible for free plan or Free Tier credits if you have an existing AWS account, or had one in the past. The free plan and Free Tier credits are available only to new AWS customers.”
https://aws.amazon.com/free/free-tier-faqs/
Now, if a user has an existing account and tries to make a new one, even with plus addressing, they will see this message at the end of the process:
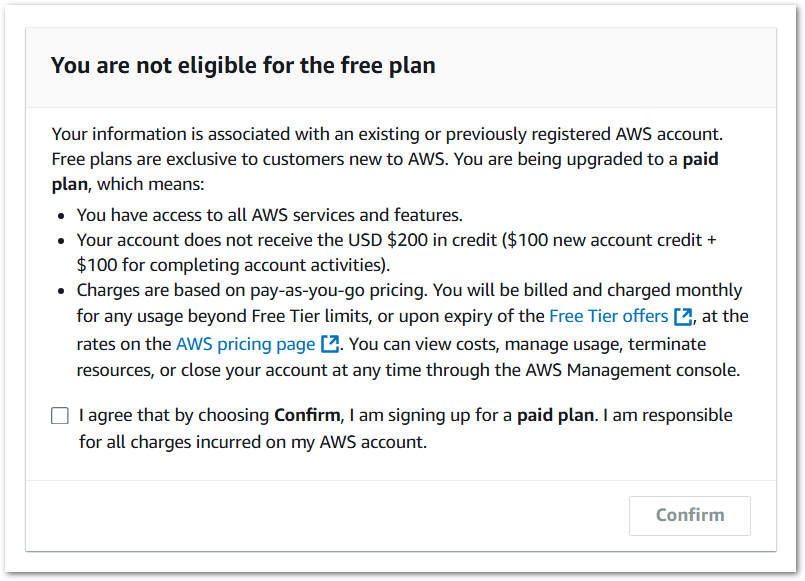
No doubt there are parts of the Internet that will find ways around this. I haven’t pursued it personally as I was only interested in checking the restrictions of certain services. AWS themselves don’t have this problem of course, and have their own blog post about the Free Tier update with various screenshots and explanations.
Speaking of restrictions…
Unusual Service (In)Eligibility Choices
This section is based on the original Excel sheet given by AWS in July 2025 and may be subject to change – Ed
As mentioned earlier, AWS now limit the available services on their Free plan:
Free account plans don’t have access to certain AWS services that would rapidly consume the entire AWS Free Tier credit amount, or hardware purchases.
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/free-tier.html
That said, there are some unusual choices here regarding services that are and aren’t eligible for the free plan.
Firstly, Glue is enabled, but Athena isn’t. So new users can create Glue resources, but can’t interact with them using Athena. I’m confused by this – for Athena to be costly, it usually requires querying data in the TB range that a new AWS account simply wouldn’t contain. Nor does it need specialised hardware. AWS even credits Athena with “Simple and predictable pricing” on its feature page, so why the Free Plan exclusion?
Also confusingly, CodeBuild and CodePipeline are eligible, but CodeDeploy isn’t. Can’t say I understand the logic behind this either!
Other exclusions make more sense. S3 is eligible, but Glacier services aren’t. Fair enough – Glacier is for long-lived storage, while free plans have six-month limits. Presumably, S3 Intelligent Tiering also excludes Glacier on the Free Plan.
Elsewhere, EC2 is eligible but I’ve not been able to check how limited the offering is. Trawling Reddit suggests only the t3.micro instance is available, but if this isn’t the case then many instance types exist that could rapidly burn through $200.
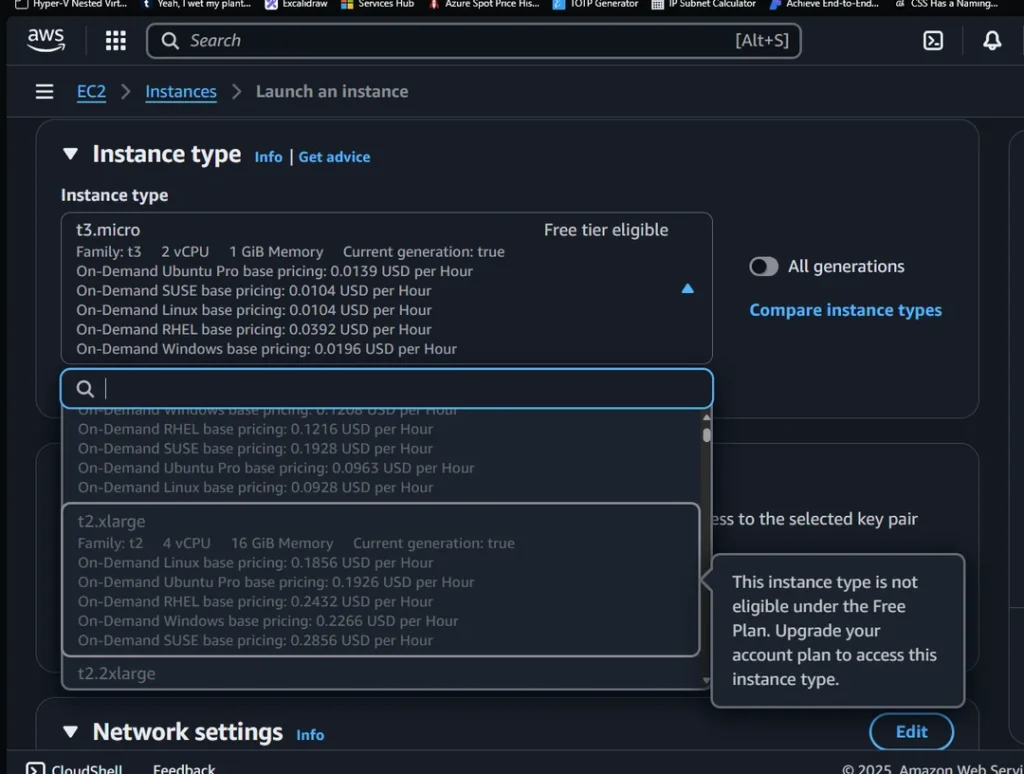
AWS CloudHSM is also eligible, with average costs around $1.50 per instance per hour. This totals about $36 per day or $100 over three days, somewhat contradicting AWS’s reasoning for the limitations. And while users could be frugal with using it, these are new users who are likely to be using AWS for the first time.
There’s a list of Free Plan eligible services, but it’s not easy to browse.
Immediate Credit Expiry
Finally, new users should be aware that certain actions immediately forfeit free tier credits. Most notably:
When your account joins AWS Organizations or sets up an AWS Control Tower landing zone, your AWS Free Tier credits expire immediately and your account will not be eligible to earn more AWS Free Tier credits.
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/free-tier-FAQ.html
Now, these are hardly services that a new user would need. However, an organisation or educational body would want to bear this in mind if they were encouraging staff or students to try AWS out. The free accounts must remain under the ownership of individual users. Any attempt to bring them into an existing AWS Organisation will kill their free tier!
Separately, this simplifies things for those of us already using Organisations or Control Tower – accounts created using these services will immediately be on the paid plan with no usage restrictions.
Summary
This blog post focused on the recent changes to AWS’s Free Tier, which allows new users to select either a Paid Plan or a Free Plan. It highlighted the main modifications made, specified which services were included or excluded, and considered the impact of these changes on both novice and seasoned users.
Overall, I see this as a positive change. The AWS Free Tier offering has been divisive for some time, and these changes go a long way towards softening many of its rough edges. While not everyone will get what they want, these changes greatly help to address the concerns and challenges faced by newbies in the past.
New users of AWS in 2025 should consider the same advice as in years prior:
- Security first, always.
- Check the cost of services before spinning them up.
- Turn unused services off.
- And finally, don’t forget to set that budget alarm!
New users can sign up for an AWS Free Plan at aws.amazon.com/free.

Like this post? Click the button below for links to contact, socials, projects and sessions:

Thanks for reading ~~^~~






