In this post, I discuss my recent Building And Automating Data Pipelines session presented at 2024’s AWS Summit London.
Table of Contents
Introduction
One of my YearCompass 2024 goals was to build a personal brand and focus on my soft skills and visibility. After participating in 2023’s New Stars Of Data 6 event, I wrote some new session abstracts and considered my next move. Then in February I saw Matheus Guimaraes‘ LinkedIn invite to submit sessions for 2024’s AWS Summit London event:
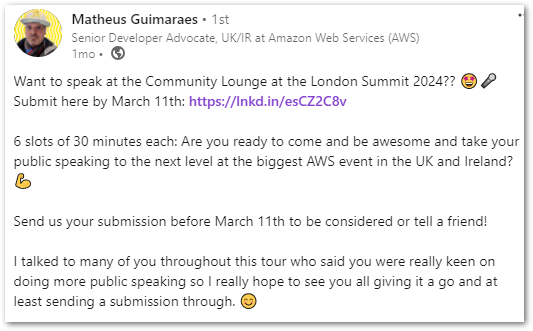
I mulled it over, deciding to submit an abstract using my recent WordPress Data Pipeline project. At the very least, it’d be practice for both writing abstracts and pushing myself to submit them.
And that’s where I expected it to end. Until…
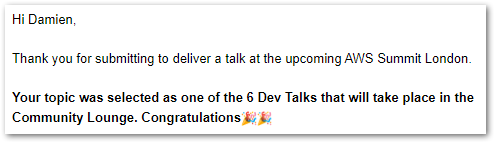
Just like that, I was heading to the capital again! And this time as a speaker!
My AWS Summit London (ASL) experience was going to be different from my New Stars Of Data (NSOD) one in several ways:
- While NSOD was virtual, ASL would be in person.
- I had four months to prepare for NSOD, and five weeks for ASL.
- My NSOD session was 60 minutes, while ASL would be 30.
So I dusted off my NSOD notes, put a plan together and got to work!
Preparation
This section examines the preparation of the slides and demo for my summit session.
Slides
Firstly, I brainstormed what the session should include from my recent posts. Next, I storyboarded what the session’s sections would be. These boiled down to:
- Defining the problem. I wanted to use an existing framework for this, ultimately choosing the 4Vs Of Big Data. These have been around since the early 2000’s, and are equally valid today for EDA and IOT events, API requests, logging metrics and many other modern technologies.
- Examining the AWS services comprising the data pipeline, and highlighting features of each service that relate to the 4Vs.
- Demonstrating the AWS services in a real pipeline and showing further use cases.
This yielded a rough schedule for the session:
- 00:00-05:00 Introduction
- 05:00-10:00 Problem Definition
- 10:00-15:00 Solution Architecture
- 15:00-20:00 Demo
- 20:00-25:00 Summary
- 25:00-30:00 Questions
Creating and editing the slide deck was much simpler with this in place. Each slide now needed to conform with and add value to its section. It became easier to remove bloat and streamline the wordier slides.
Several slides then received visual elements. This made them more audience-friendly and gave me landmarks to orient myself within the deck. I used AWS architecture icons on the solution slides and sharks on the problem slides. Lots of sharks.
Here’s the finished deck. I regret nothing.
As I was rounding off the slides, the summit agenda was published with the Community Lounge sessions. It was real now!

Demo
I love demos and was keen to include one for my summit session.
Originally I wanted a live demo, but this needed a good internet connection. It was pointed out to me that an event with thousands of people might not have the best WiFi reception, leading to slow page loads at best and 404s at worst!
So I recorded a screen demo instead. From a technical standpoint, this protected the demo from platform outages, network failures and zero-day bugs. And from a delivery standpoint, a pre-recorded demo let me focus on communicating my message to the audience instead of potentially losing my place, mistyping words and overrunning the allocated demo time.
The demo used this workflow, executed by an EventBridge Schedule:
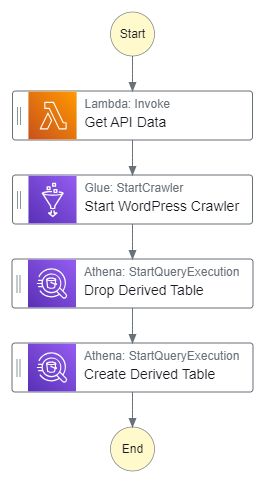
The demo’s first versions involved building the workflow and schedule from scratch. This overran the time allocation and felt unfocused. Later versions began with a partly constructed workflow. This built on the slides and improved the demo’s flow. I was far happier with this version, which was ultimately the one I recorded.
I recorded the demo with OBS Studio – a free open-source video recording and live-streaming app. There’s a lot to OBS, and I found this GuideRealmVideos video helpful in setting up my recording environment:
Delivery
This section covers the rehearsal and delivery of my AWS summit session.
Rehearsal
With everything in place, it was time to practise!
I had less time to practise this compared to NSOD, so I used various strategies to maximise my time. I started by practising sections separately while refining my notes. This gave all sections equal attention and highlighted areas needing work.
Next, after my success with it last time, I did several full run-throughs using PowerPoint’s Speaker Coach. This went well and gave me confidence in the content and slide count.
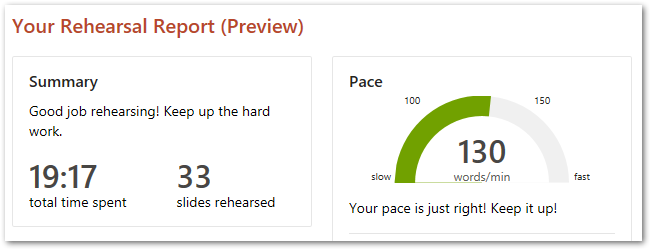
The slide visuals worked so well that I could practise the opening ten minutes without the slides in front of me! This led to run-throughs while shopping, on public transport and even in the queue for the AWS Summit passes.
Probably got some weird looks for that. I still regret nothing.
Practising the demo was more challenging! While the slides were fine as long as I hit certain checkpoints, the demo’s pace was entirely pre-determined. I knew what the demo would do, but keeping in sync with my past self was tricky to master. I was fine as long as I could see my notes and the demo in real-time.
Finally, on the night before I did some last-minute practice runs with the hotel room’s TV:

On The Day
My day started with being unable to find the ExCel’s entrance! Great. But still better than a 05:15 Manchester train! I got my event pass and hunted for the Community Lounge, only to find my name in lights!

The lounge itself was well situated, away from potentially distracting stands and walkways but still feeling like an important part of the summit.

I spent some time adjusting to the space and battling my brewing anxiety. Then Matheus and Rebekah Kulidzan appeared and gave me some great and much-appreciated advice and encouragement! Next, I went for a wander with my randomised feel-good playlist that threw out some welcome bangers:
I watched Yan’s session, paying attention to his delivery and mannerisms alongside his session’s content. After he finished I powered on, signed in and miked up. The lounge setup was professional but not intimidating, and the AWS staff were helpful and attentive. Finally, at noon I went live!

The session went great! I had a good audience, kept my momentum and hit my section timings. I had a demo issue when my attempt to duplicate displays failed. Disaster was averted by playing the demo on the main screens only!
Finally, my half-hour ended and I stepped off the stage to applause, questions and an unexpected hug!

Looking Back
So what’s next?
I was happy with the amount of practice I did, and will continue putting time into this in the coming months. I’ve submitted my summit session to other events, and the more rehearsals I complete the higher my overall standard should get.
I also want to find a more reliable way of showing demos without altering Windows display settings. Changing these settings mid-presentation isn’t the robust solution I thought it was, so I want to find a feature or setting that’ll take care of that.
Finally, I plan to act on advice from Laurie Kirk. She suggested speaking about a day’s events on camera and then watching it back the following day. This highlights development areas and will get me used to speaking under observation.
Summary
In this post, I discussed my recent Building And Automating Data Pipelines session presented at 2024’s AWS Summit London.
When writing my post about the 2022 AWS Summit London event, I could never have known I’d find myself on the lineup a few years later! Tech communities do great jobs of driving people forward, and while this is usually seen through a technical lens the same is true for personal skills.
The AWS Community took this apprehensive, socially anxious shark and gave him time, a platform and an audience. These were fantastic gifts that I’m hugely grateful for and will always remember.

If this post has been useful then the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~