In this post, I do a deep dive into some of the amazonwebshark WordPress MySQL database tables following the journey of a recent post.
Table of Contents
- Introduction
- WordPress Database 101
- wp_posts
- wp_term_relationships
- wp_term_taxonomy
- wp_terms
- wp_statistics_pages
- Summary
Introduction
In January I used Python and Matplotlib to create some visualisations using the WordPress amazonwebshark MySQL database.
Since then I’ve been doing a lot with Power BI at work, so I’ve created a Power BI connection to the amazonwebshark database to reacquaint myself with some features and experiment with a familiar dataset.
I talked about doing a views analysis in January’s post. While some of the 2022 data is missing, I can still accurately analyse 2023 data. I plan to measure:
- Total views for each post.
- Total views for each category.
I’ll use this post to examine some of the MySQL tables, and link back to it in future analysis posts.
Let’s begin with a brief WordPress database overview.
WordPress Database 101
In this section, I take a high-level view of a typical WordPress database and identify the tables I’ll need.
There’s plenty of great documentation online about typical WordPress installations. I’m particularly keen on The Ultimate Developer’s Guide to the WordPress Database by DeliciousBrains, which includes an in-depth tour of the various tables.
As for table relationships, this WordPress ERD shows object names, primary keys and relationship types:

I’ll be concentrating on these WordPress tables:
And the wp_statistics_pages table used by WPStatistics.
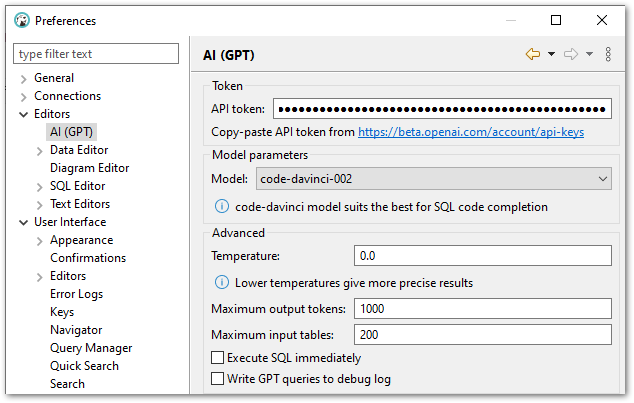
I’ll examine each table in the context of a recent post: DBeaver OpenAI ChatGPT Integration.
wp_posts
In this section of my WordPress database deep dive, I examine the most important WordPress database table: wp_posts.
Table Purpose
WordPress uses wp_posts to manage a site’s content. Each row in the table is an event relating to a piece of content, like a post, page or attachment. Examples of these events in the context of a blog post are:
- Creating A New Draft: A new row is created with a
post_statusof draft. This row is the parent of all future activity for the blog post.
- Updating A Draft: A new row is created with details of the update. The new row’s
post_parentis set to the initial post’s ID.
- Publishing A Draft: The initial row’s
post_statusis changed to publish, and thepost_dateis changed to the publication date. WordPress finds revisions to the post by filtering rows with apost_parentmatching the initial row’sID.
Post Journey
Let’s start by finding DBeaver OpenAI ChatGPT Integration‘s parent row, which is its earliest record. The following query finds rows where the post_title is DBeaver OpenAI ChatGPT Integration, then orders by ID and returns the first result.
SELECT
id,
post_date,
post_title,
post_status,
post_name,
post_parent,
post_type
FROM
`wp_posts`
WHERE
post_title = 'DBeaver OpenAI ChatGPT Integration'
ORDER BY
id
LIMIT
1
Note that I order by ID, not post_date. The publication process changes the parent post’s post_date, so I must use ID to find the earliest post.
This record is returned:
| Name | Value |
|---|---|
| ID | 1902 |
| post_date | 2023-02-19 20:28:22 |
| post_title | DBeaver OpenAI ChatGPT Integration |
| post_status | publish |
| post_name | dbeaver-openai-chatgpt-integration |
| post_parent | 0 |
| post_type | post |
So the DBeaver OpenAI ChatGPT Integration parent row is ID 1902. I can use this to count the number of changes to this post by searching for wp_posts rows with a post_parent of 1902:
SELECT
COUNT(*)
FROM
`wp_posts`
WHERE
post_parent = 1902
81 rows are returned:
Name |Value|
--------+-----+
COUNT(*)|81 |Now let’s examine these results more closely.
In the following query, I get all rows relating to DBeaver OpenAI ChatGPT Integration and then group the results by:
- Date the post was made (using the MySQL
DATEfunction to remove the time values for more meaningful aggregation). - Status of the post.
- Post’s parent post.
- Type of post.
I also count the rows that match each group and order the results by ID to preserve the event order:
SELECT
COUNT(*) AS ID_count,
DATE(post_date) AS post_date,
post_status,
post_parent,
post_type
FROM
`wp_posts`
WHERE
ID = 1902
OR post_parent = 1902
GROUP BY
DATE(post_date),
post_status,
post_parent,
post_type
ORDER BY
ID
The query results are below. A couple of things to note:
- The first two columns show what happens when a post is published. Row 1 is
ID1902 as it has nopost_parent, and it has apost_statusof publish and apost_dateof 2023-02-19. - Row 2 is the first revision of
ID1902, and it has apost_statusof inherit and apost_dateof 2023-02-15. This is why I order byIDinstead ofpost_date– ordering bypost_datewould show the revisions before the parent post in the results. - There are various
post_typevalves – revisions are text updates and attachments are image updates.
| ID_count | post_date | post_status | post_parent | post_type |
|---|---|---|---|---|
| 1 | 2023-02-19 | publish | 0 | post |
| 1 | 2023-02-15 | inherit | 1902 | revision |
| 19 | 2023-02-16 | inherit | 1902 | revision |
| 7 | 2023-02-16 | inherit | 1902 | attachment |
| 24 | 2023-02-17 | inherit | 1902 | revision |
| 1 | 2023-02-17 | inherit | 1902 | attachment |
| 7 | 2023-02-18 | inherit | 1902 | revision |
| 21 | 2023-02-19 | inherit | 1902 | revision |
| 1 | 2023-02-26 | inherit | 1902 | revision |
Spotlighting some of these results for context:
- On 2023-02-16 there were 19 text revisions and 7 images attached. I save a lot!
- On 2023-02-19 there were 21 text revisions and then the post was published.
- There was a further text revision on 2023-02-26 in response to a DBeaver software update.
That’s enough about wp_posts for now. Next, let’s start examining how WordPress groups content.
wp_term_relationships
In this section, I examine the first of the WordPress taxonomy tables: wp_term_relationships.
Table Purpose
wp_term_relationships stores information about the relationship between posts and their associated taxonomy terms (More on taxonomies in the next section). WordPress uses it as a bridge table between wp_posts and the various taxonomy tables.
Post Journey
In this query, I join wp_term_relationships to wp_posts on object_id (this is ID in wp_posts), then find the rows where either wp_posts.id or wp_posts.post_parent is 1902:
SELECT
yjp.ID,
DATE(yjp.post_date) AS post_date,
yjp.post_type,
yjp.post_status,
yjtr.object_id,
yjtr.term_taxonomy_id
FROM
`wp_posts` AS yjp
INNER JOIN `wp_term_relationships` AS yjtr
ON yjtr.object_id = yjp.ID
WHERE
yjp.ID = 1902
OR yjp.post_parent = 1902
wp_term_relationships only contains published posts, so the only rows returned concern the parent ID 1902:
| ID | post_date | post_type | post_status | object_id | term_taxonomy_id |
|---|---|---|---|---|---|
| 1902 | 2023-02-19 | post | publish | 1902 | 2 |
| 1902 | 2023-02-19 | post | publish | 1902 | 69 |
| 1902 | 2023-02-19 | post | publish | 1902 | 71 |
| 1902 | 2023-02-19 | post | publish | 1902 | 74 |
| 1902 | 2023-02-19 | post | publish | 1902 | 76 |
| 1902 | 2023-02-19 | post | publish | 1902 | 77 |
The query returned six distinct wp_term_relationships.term_taxonomy_id values. My next step is to establish what these IDs relate to.
wp_term_taxonomy
In this section, I examine the table that groups term_taxonomy_id values into taxonomy types: wp_term_taxonomy.
Table Purpose
WordPress uses the wp_term_taxonomy table to store the taxonomy data for terms. Taxonomies in WordPress are used to group posts and custom post types together. Examples of WordPress taxonomies are category, post_tag and nav_menu.
Post Journey
In this query, I add a new join to the previous query, joining wp_term_taxonomy to wp_term_relationships on term_taxonomy_id. Some of the wp_posts columns have been removed from the query to save space.
SELECT
yjp.ID,
yjtr.term_taxonomy_id,
yjtt.taxonomy
FROM
`wp_posts` AS yjp
INNER JOIN `wp_term_relationships` AS yjtr
ON yjtr.object_id = yjp.ID
INNER JOIN `wp_term_taxonomy` AS yjtt
ON yjtr.term_taxonomy_id = yjtt.term_taxonomy_id
WHERE
yjp.ID = 1902
OR yjp.post_parent = 1902
These results give some content to the previous results. I can now see that wp_posts.id 1902 has one category and five tags.
| ID | term_taxonomy_id | taxonomy |
|---|---|---|
| 1902 | 2 | category |
| 1902 | 69 | post_tag |
| 1902 | 71 | post_tag |
| 1902 | 74 | post_tag |
| 1902 | 76 | post_tag |
| 1902 | 77 | post_tag |
To get the names of the categories and tags, I must bring one more table into play…
wp_terms
In this section of my WordPress database deep dive, I examine the table that holds the names and details of the taxonomy terms used on amazonwebshark: wp_terms.
Table Purpose
The wp_terms table stores all of the terms that are used across all taxonomies on a WordPress site. Each row represents a single term, and the columns in the table contain information about that term, including name and ID.
Post Journey
In this query, I add another join to the previous query, joining wp_terms to wp_term_taxonomyterm_id.
SELECT
yjp.ID,
yjtr.term_taxonomy_id,
yjtt.taxonomy,
yjt.name
FROM
`wp_posts` AS yjp
INNER JOIN `wp_term_relationships` AS yjtr
ON yjtr.object_id = yjp.ID
INNER JOIN `wp_term_taxonomy` AS yjtt
ON yjtr.term_taxonomy_id = yjtt.term_taxonomy_id
INNER JOIN `wp_terms` AS yjt
ON yjtt.term_id = yjt.term_id
WHERE
yjp.ID = 1902
OR yjp.post_parent = 1902
The results now identify the category and each of the five tags by name:
| ID | term_taxonomy_id | taxonomy | name |
|---|---|---|---|
| 1902 | 2 | category | AI & Machine Learning |
| 1902 | 69 | post_tag | WordPress |
| 1902 | 71 | post_tag | DBeaver |
| 1902 | 74 | post_tag | MySQL |
| 1902 | 76 | post_tag | OpenAI |
| 1902 | 77 | post_tag | ChatGPT |
This is a perfect match for the post’s taxonomy in the WordPress portal:

So that’s the categories. What about the views?
wp_statistics_pages
In this final section, I examine the WPStatistics table that holds view counts: wp_statistics_pages
Table Purpose
WPStatistics uses wp_statistics_pages
WPStatistics documentation isn’t as in-depth as WordPress, so here are the table’s DDL and column descriptions:
CREATE TABLE `1yJ_statistics_pages` (
`page_id` bigint(20) NOT NULL AUTO_INCREMENT,
`uri` varchar(190) NOT NULL,
`type` varchar(180) NOT NULL,
`date` date NOT NULL,
`count` int(11) NOT NULL,
`id` int(11) NOT NULL,
PRIMARY KEY (`page_id`),
UNIQUE KEY `date_2` (`date`,`uri`),
KEY `url` (`uri`),
KEY `date` (`date`),
KEY `id` (`id`),
KEY `uri` (`uri`,`count`,`id`)
)
| Table Name | Description |
| page_id | Primary key. Unique identifier for the table. |
| uri | Uniform Resource Identifier used to access a page. |
| type | uri type: home / page / post |
| date | Date the uri was viewed |
| count | uri total views on the specified date |
| id | uri ID in wp_posts.ID |
Post Journey
As wp_statistics_pages.id is the same as wp_posts.id, I can use id 1902 in a query knowing it will still refer to DBeaver OpenAI ChatGPT Integration.
For example, this query counts the number of rows in wp_statistics_pages relating to id 1902:
SELECT
COUNT(*)
FROM
`wp_statistics_pages`
WHERE
id = 1902
COUNT(*)|
--------+
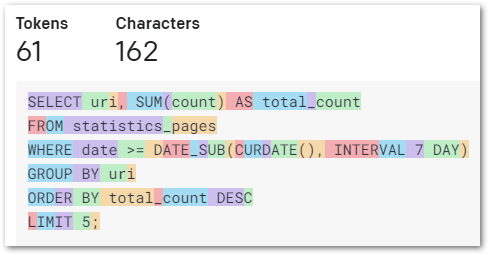
14|I can also calculate how many visits DBeaver OpenAI ChatGPT Integration has received by using SUM on all wp_statistics_pages.count values for id 1902:
SELECT
SUM(yjsp.count)
FROM
`wp_statistics_pages` AS yjsp
WHERE
yjsp.id = 1902
SUM(count)|
----------+
40|So the page currently has 40 views. I can see how these views are made up by selecting and ordering by wp_statistics_pages.date:
SELECT
yjsp.date,
yjsp.count
FROM
`wp_statistics_pages` AS yjsp
WHERE
yjsp.id = 1902
ORDER BY
yjsp.date
| date | count |
|---|---|
| 2023-02-19 | 1 |
| 2023-02-20 | 5 |
| 2023-02-21 | 1 |
| 2023-02-22 | 4 |
| … | … |
| 2023-03-07 | 6 |
| 2023-03-08 | 3 |
| 2023-03-09 | 2 |
| 2023-03-10 | 1 |
I can also join wp_posts to wp_statistics_pages on their id columns, bridging the gap between the WPStatistics table and the standard WordPress tables:
SELECT
yjsp.date,
yjsp.count,
yjp.post_title
FROM
`wp_statistics_pages` AS yjsp
INNER JOIN `wp_posts` AS yjp
ON yjsp.id = yjp.id
WHERE
yjsp.id = 1902
ORDER BY
yjsp.date
| date | count | post_title |
|---|---|---|
| 2023-02-19 | 1 | DBeaver OpenAI ChatGPT Integration |
| 2023-02-20 | 5 | DBeaver OpenAI ChatGPT Integration |
| 2023-02-21 | 1 | DBeaver OpenAI ChatGPT Integration |
| 2023-02-22 | 4 | DBeaver OpenAI ChatGPT Integration |
| … | … | … |
| 2023-03-07 | 6 | DBeaver OpenAI ChatGPT Integration |
| 2023-03-08 | 3 | DBeaver OpenAI ChatGPT Integration |
| 2023-03-09 | 2 | DBeaver OpenAI ChatGPT Integration |
| 2023-03-10 | 1 | DBeaver OpenAI ChatGPT Integration |
Summary
In this post, I did a deep dive into some of the amazonwebshark WordPress MySQL database tables following the journey of a recent post.
I’ve used this post to present the journey a typical post goes through in the WordPress database. Future posts will use this knowledge and the WordPress database as a data source for various dashboards, scripting and processes. Watch this space!
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~