Earlier this month, I hosted March 2023’s T-SQL Tuesday with an invitation concerning the ongoing Microsoft and OpenAI partnership:
What is on your wishlist for the partnership between Microsoft and OpenAI?
What follows is some commentary on, and links to, each of the responses.
Chad Callihan
Chad’spost considers potential PowerShell-OpenAI functionality, which would write scripts in response to user prompts. PowerShell is a mainstay of many data professionals, enabling modules like dbatools, Pester and the AWS, Azure and GCPSDKs. An AI with access to the PowerShell Gallery would be very helpful.
Chad also points out some security concerns linked with ChatGPT use, which are good advice in general:
Chris’spost considers an AI model for file ingestion. Data pipelines frequently rely on source data with specific types and layouts. Unfortunately, source data can change between ingestion times.
At best, this breaks pipelines and causes problems and downtime for data teams. At worst, incorrect data is ingested causing potential business and customer detriment.
A no-code AI model would save hours of work if it considered previous source data and could make decisions like “This column is formatted as VARCHAR, but yesterday it was DATETIME2 and has hyphens in the right place, so I’ll CAST it as DATETIME2 today and raise a warning in the log.”
Rob Farley
Rob’spost was partially written by ChatGPT! Rob takes a pragmatic approach to AI’s progress and draws a Clippy analogy. I really want to see this AI family tree now.
ChatGPT suggests that it can help with Excel formulae, SQL Server optimization and PowerPoint visuals. It also wants to democratize technology interaction and remove traditional barriers to entry.
Steve Jones
Steve’spost imagines the next generation of AI personal assistant. One that can:
Learn from the user and correct common errors in all applications.
Suggest code optimizations in a variety of IDEs and languages.
Learn the user’s schedule and create automated calendar events and reminders.
Recognise repeat tasks and create related automation.
Summary
In this post, I wrote a round-up of the community responses to my March 2023 T-SQL Tuesday #160 invitation: Microsoft OpenAI Wishlist.
Thanks to everyone who contributed to my first T-SQL Tuesday invitation. It was great to read your responses! Anyone interested in hosting future events should contact Steve Jones.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Artificial Intelligence has been a big deal in recent months. One of the main drivers of this has been OpenAI, whose DALL-E 2 and ChatGPT services have seen extraordinary public interest and participation.
Microsoft has been one of OpenAI’s most prominent supporters. In July 2019 Microsoft invested $1 billion in OpenAI and became their exclusive cloud provider.
However, Power BI is reliant on user skill levels. Like all data visualization tools, Power BI can create bad dashboards in the wrong hands. Like, really bad. Dashboards can suffer from several problems that make them useless at best and misleading at worst.
"Improve my annual sales dashboard"
>> I have changed the pie chart showing 12 team members to a bar chart, as this will improve the visualization's legibility.
Azure IAC AI Assistant
IAC (Infrastructure As Code) has revolutionized the public cloud industry, bringing with it benefits like:
Automated, faster deployments.
Repeatable and consistent deployments.
Self-documenting infrastructure.
But IAC also presents challenges:
IAC scripts rely on the skills of the engineer writing them.
It’s not easy to incorporate existing infrastructure.
ChatGPT could resolve many of these problems, turning infrastructure creation into a conversation. It could, for example:
Create infrastructure based on non-technical requests:
"Make me what I need to start a blog."
>> I have created a LAMP stack on a virtual machine in your default region. Your access details are here:
Username: Username
Password: Password
Learn current infrastructure usage patterns and create optimisations for busy and quiet periods.
Spot potential conflicts and step in to prevent data loss or downtime.
Make existing infrastructure faster, cheaper or more performant without the need for manual refactoring.
Resolve problems like high latency, failing connections and unexpected cost increases:
"Why is my web app generating errors?"
>> One of your virtual machines does not allow connection requests from CIDR range 10.01.10.01/28. Do you want me to fix this?
"Yes please."
>> I have now amended virtual machine MYAPP001's Network Security Group to accept incomming connection requests from CIDR range 10.01.10.01/28.
Summary
In this post, I hosted March 2023’s T-SQL Tuesday with an invitation concerning the ongoing Microsoft and OpenAI partnership. I look forwards to reading everyone’s responses!
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Please be as specific as possible with your examples and include your reasoning.
Good question!
In each section, I’ll use a different language. Firstly I’ll create a script, and then show a problem the script could encounter in production. Finally, I’ll show how a different approach can prevent that problem from occurring.
I’m limiting myself to three production code qualities to keep the post at a reasonable length, and so I can show some good examples.
Precision
In this section, I use T-SQL to show how precise code in production can save a data pipeline from unintended failure.
Setting The Scene
Consider the following SQL table:
USE [amazonwebshark]
GO
CREATE TABLE [2022].[sharkspecies](
[shark_id] [int] IDENTITY(1,1) NOT NULL,
[name_english] [varchar](100) NOT NULL,
[name_scientific] [varchar](100) NOT NULL,
[length_max_cm] [int] NULL,
[url_source] [varchar](1000) NULL
)
GO
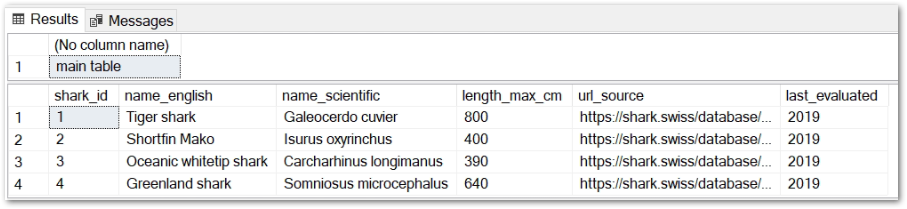
Now, let’s say that I have a data pipeline that uses data in amazonwebshark.2022.sharkspecies for transformations further down the pipeline.
No problem – I create a #tempsharkstemp table and insert everything from amazonwebshark.2022.sharkspecies using SELECT *:
When this script runs in production, I get two tables with the same data:
What’s The Problem?
One day a new last_evaluated column is needed in the amazonwebshark.2022.sharkspecies table. I add the new column and backfill it with 2019:
ALTER TABLE [2022].sharkspecies
ADD last_evaluated INT DEFAULT 2019 WITH VALUES
GO
However, my script now fails when trying to insert data into #tempsharks:
(1 row affected)
(4 rows affected)
Msg 213, Level 16, State 1, Line 17
Column name or number of supplied values does not match table definition.
Completion time: 2022-11-02T18:00:43.5997476+00:00
#tempsharks has five columns but amazonwebshark.2022.sharkspecies now has six. My script is now trying to insert all six sharkspecies columns into the temp table, causing the msg 213 error.
Doing Things Differently
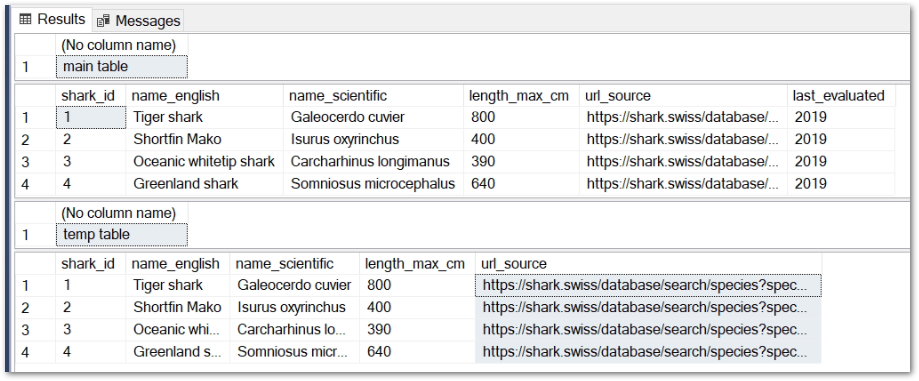
The solution here is to replace row 21’s SELECT * with the precise columns to insert from amazonwebshark.2022.sharkspecies:
While amazonwebshark.2022.sharkspecies now has six columns, my script is only inserting five of them into the temp table:
I can add the last_evaluated column into #tempsharks in future, but its absence in the temp table isn’t causing any immediate problems.
Works The Same In Other Environments
In this section, I use Python to show the value of production code that works the same in non-production.
Setting The Scene
Here I have a Python script that reads data from an Amazon S3 bucket using a boto3 session. I pass my AWS_ACCESSKEY and AWS_SECRET credentials in from a secrets manager, and create an s3bucket variable for the S3 bucket path:
When I deploy this script to my dev environment it works fine.
What’s The Problem?
When I deploy this script to production, s3bucket will still be s3://dev-bucket. The potential impact of this depends on the AWS environment setup:
Different AWS account for each environment:
dev-bucket doesn’t exist in Production. The script fails.
Same AWS account for all environments:
Production IAM roles might not have any permissions for dev-bucket. The script fails.
Production processes might start using a dev resource. The script succeeds but now data has unintentionally crossed environment boundaries.
Doing Things Differently
A solution here is to dynamically set the s3bucket variable based on the ID of the AWS account the script is running in.
I can get the AccountID using AWS STS. I’m already using boto3, so can use it to initiate an STS client with my AWS credentials.
STS then has a GetCallerIdentity action that returns the AWS AccountID linked to the AWS credentials. I capture this AccountID in an account_id variable, then use that to set s3bucket‘s value:
For bonus points, I can terminate the script if the AWS AccountID isn’t defined. This prevents undesirable states if the script is run in an unexpected account.
Speaking of which…
Prevents Undesirable States
In this section, I use PowerShell to demonstrate how to stop production code from doing unintended things.
Setting The Scene
In June I started writing a PowerShell script to upload lossless music files from my laptop to one of my S3 buckets.
I worked on it in stages. This made it easier to script and test the features I wanted. By the end of Version 1, I had a script that dot-sourced its variables and wrote everything in my local folder $ExternalLocalSource to my S3 bucket $ExternalS3BucketName:
#Load Variables Via Dot Sourcing
. .\EDMTracksLosslessS3Upload-Variables.ps1
#Upload File To S3
Write-S3Object -BucketName $ExternalS3BucketName -Folder $ExternalLocalSource -KeyPrefix $ExternalS3KeyPrefix -StorageClass $ExternalS3StorageClass
What’s The Problem?
NOTE: There were several problems with Version 1, all of which were fixed in Version 2. In the interests of simplicity, I’ll focus on a single one here.
In this script, Write-S3Object will upload everything in the local folder $ExternalLocalSource to the S3 bucket $ExternalS3BucketName.
Problem is, the $ExternalS3BucketName S3 bucket isn’t for everything! It should only contain lossless music files!
At best, Write-S3Object will upload everything in the local folder to S3 whether it’s music or not.
At worst, if the script is pointing at a different folder it will start uploading everything there instead! PowerShell commonly defaults to C:\Windows, so this could cause all kinds of problems.
Doing Things Differently
I decided to limit the extensions that the PowerShell script could upload.
So now, if I attempt to upload an unacceptable .log file, PowerShell raises an exception and terminates the script:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Unacceptable .log file found. Exiting.
**********************
While an acceptable .flac file will produce this message:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Acceptable .flac file.
**********************
In this post, I responded to November 2022’s T-SQL Tuesday #156 Invitation and gave my thoughts on some production code qualities. I gave examples of each quality and showed how they could save time and prevent unintended problems in a production environment.