
In this post I will use AWS managed services to produce security alerts when attempts are made to access my AWS account’s console.
Table of Contents
Introduction
I am currently studying towards the AWS Certified Developer – Associate certification using Stéphane Maarek’s video course and the Tutorials Dojo practice exams. As part of my studies I want to better understand the various AWS monitoring services, and setting up some security alerts is a great way to get some real-world experience of them.
My current security posture is already in line with AWS best practices. For example:
- I use a password manager and autogenerate passwords so they’re not reused.
- MFA is enabled on everything offering it.
- I have created IAM users and roles for all my AWS requirements and never use my root account.
To strengthen this, I will create some security alerts that will notify me when attempts are made to access my AWS console whether they succeed or fail.
I will be using the following AWS services:
- IAM for handling authentication requests.
- CloudTrail for creating log events.
- CloudWatch for analysing log events and triggering alarms.
- SNS for sending notifications when alarms are triggered.
The end result will look like this:
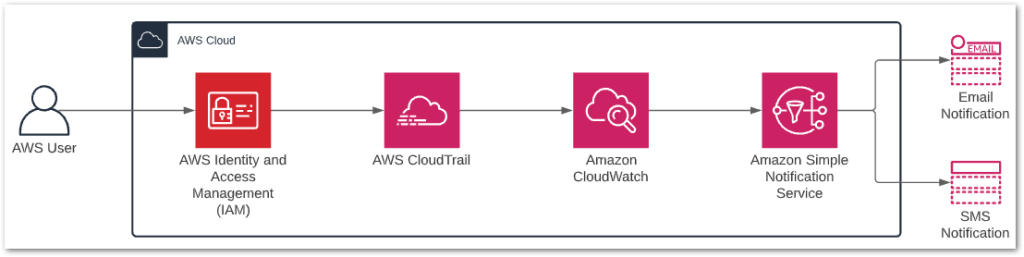
Let’s start with IAM.
IAM
AWS Identity and Access Management (IAM) is the AWS tool for managing permissions and access policies. I don’t need to do anything with IAM here, but I include it as IAM is the source of the events that my security alerts will use.
Next I’ll create the setup that AWS will use to send the security alerts.
SNS
Amazon Simple Notification Service (SNS) focuses on delivering notifications from sources to subscribers. SNS offers hundreds of potential combinations, and here I’m using it to send notifications to me in response to certain AWS events.
To do this, SNS uses Topics for what the notifications are and Subscriptions for where to send them.
SNS Topics
SNS Topics can be heavily customised but here I only need a simple setup. First I choose my topic’s type:
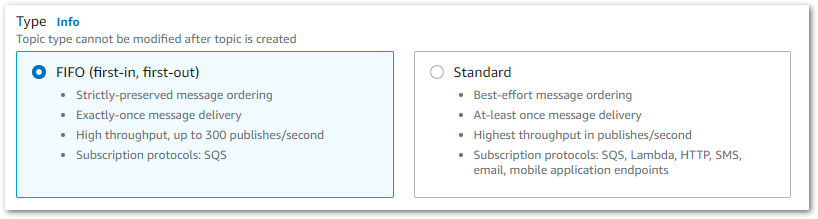
Standard is fine here as I don’t need to worry about message ordering or duplication. I also need a name for the topic. I will use the following naming pattern for the topics and for the security alerts themselves:
- Action – this will always be
signin. - Signin Method – this will always be
console. - Outcome – this will be either
failureorsuccess. - User Type – this will be either
iamorroot.
Thus my first topic is named signin-console-failure-iam.
I am creating four security alerts and want each to have a separate SNS topic generating different notifications. A short time later I have created all four successfully:
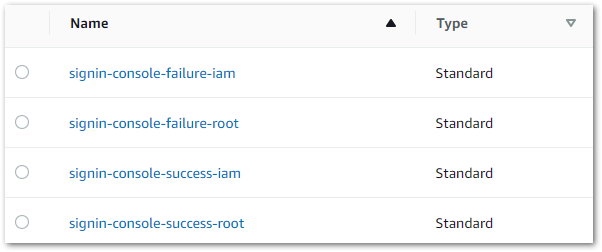
SNS Subscriptions
Now I need some SNS Subscriptions. These tell SNS where to send notifications.
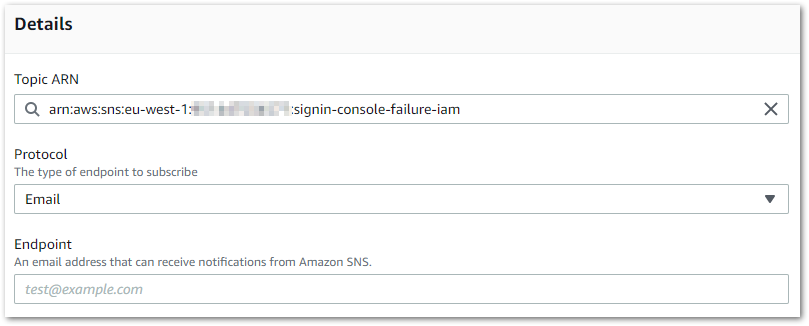
An SNS Subscription needs the following details:
- Topic ARN – the Amazon Resource Name of the desired SNS Topic.
- Protocol – there are several choices including email and SMS.
- Endpoint – this will depend on the choice of protocol. Here I have selected the
Emailprotocol so SNS requests an email address.
Once an SNS Subscription is created it must be confirmed. Here my endpoint is an email address, so SNS sends this email:
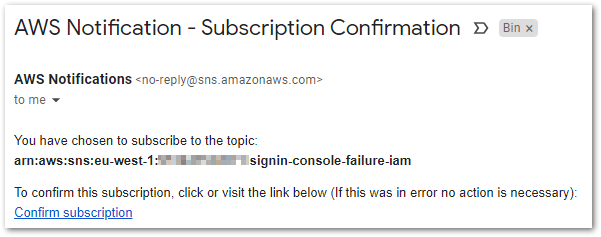
When the owner of the email confirms the subscription, a new window opens displaying the Subscription ID:
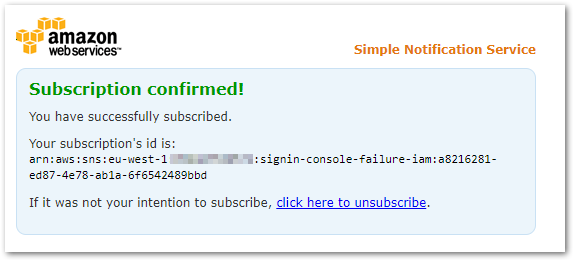
I then create further subscriptions for each SNS Topic. The SNS Subscription dashboard updates to show the list of endpoints and the confirmation status of each:
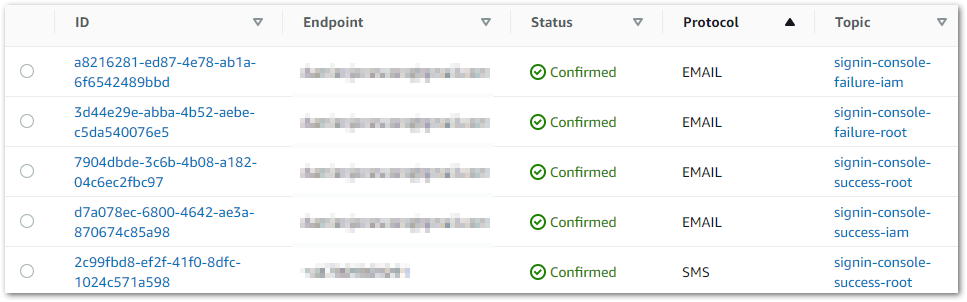
Note that signin-console-success-root has two subscriptions – one email and one SMS. This is because I never use my root account and want the heightened awareness of an SMS!
In terms of cost, the first thousand email notifications SNS every month are included in the AWS Always Free tier. Any costs will be from the infrequent SMS notifications.
With the alerts created, let’s start on the events they’ll alert against.
CloudTrail
AWS CloudTrail records user activity and API interactions. These include resource creation, service configuration and, crucially, sign-in activity.
By default, CloudTrail holds 90 days of events that can be viewed, searched and downloaded from the CloudTrail dashboard. A CloudTrail Trail is needed to store events for longer periods or to export them to other AWS services.
CloudTrail Trails
Here my CoudTrail Trail will be delivering events from CloudTrail to CloudWatch for analysis and storing them in an S3 bucket. I use the AWS CloudTrail documentation to create an events-management trail based in eu-west-1:
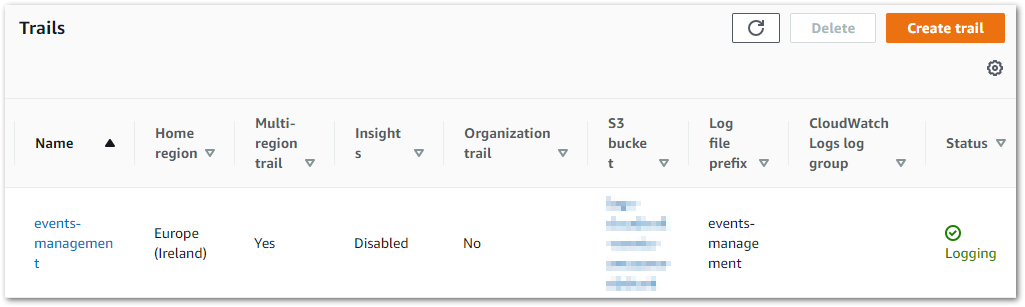
This trail is included in the AWS Always Free tier as it is my only one and it only records management events. There will be S3 charges for the objects in the bucket but this is usually around 30kb a day, so the cost here is trivial.
CloudTrail Logs
While I’m talking about CloudTrail, let’s look at the log events themselves. The CloudTrail user guide has some examples so let’s take examine one.
This example log event shows that the IAM user Alice used the AWS CLI to create a new user named Bob.
{"Records": [{
"eventVersion": "1.0",
"userIdentity": {
"type": "IAMUser",
"principalId": "EX_PRINCIPAL_ID",
"arn": "arn:aws:iam::123456789012:user/Alice",
"accountId": "123456789012",
"accessKeyId": "EXAMPLE_KEY_ID",
"userName": "Alice"
},
"eventTime": "2014-03-24T21:11:59Z",
"eventSource": "iam.amazonaws.com",
"eventName": "CreateUser",
"awsRegion": "us-east-2",
"sourceIPAddress": "127.0.0.1",
"userAgent": "aws-cli/1.3.2 Python/2.7.5 Windows/7",
"requestParameters": {"userName": "Bob"},
"responseElements": {"user": {
"createDate": "Mar 24, 2014 9:11:59 PM",
"userName": "Bob",
"arn": "arn:aws:iam::123456789012:user/Bob",
"path": "/",
"userId": "EXAMPLEUSERID"
}}
}]}Let’s break this down. The first section of the log tells us about Alice:
"userIdentity": {
"type": "IAMUser",
"principalId": "EX_PRINCIPAL_ID",
"arn": "arn:aws:iam::123456789012:user/Alice",
"accountId": "123456789012",
"accessKeyId": "EXAMPLE_KEY_ID",
"userName": "Alice"Her userName is Alice, she is an IAMUser and her accountId is 123456789012. The next part tells us what happened:
"eventTime": "2014-03-24T21:11:59Z",
"eventSource": "iam.amazonaws.com",
"eventName": "CreateUser",
"awsRegion": "us-east-2",
"sourceIPAddress": "127.0.0.1",
"userAgent": "aws-cli/1.3.2 Python/2.7.5 Windows/7"At 21:11 on 24/03/2014 Alice used the AWS CLI to call iam.amazonaws.com‘s CreateUser action. Alice’s IP address was 127.0.0.1 and she was using us-east-2.
Finally the log shows the parameters Alice supplied:
"requestParameters": {"userName": "Bob"},
"responseElements": {"user": {
"createDate": "Mar 24, 2014 9:11:59 PM",
"userName": "Bob",
"arn": "arn:aws:iam::123456789012:user/Bob"Alice provided a userName of Bob, and AWS responded with a createDate and arn for the new user.
Armed with the knowledge of what an event looks like, let’s start analysing some of them!
CloudWatch
Amazon CloudWatch is a service for monitoring, analysing and observing events. CloudWatch has several features for various situations – I’ll be using the following features for my security alerts:
- Log Groups – collections of streams of events coming from the same source.
- Metric Filters – filter expressions that are applied to events to create data points for CloudWatch metrics.
- Alarms – rules that watch CloudWatch metrics and perform actions based on their values.
Let’s start with a log group.
CloudWatch Log Group
As this is a new Log Group, I can configure it from the CloudTrail console by editing the existing events-management trail.
Nothing too complex here. The Log Group needs a name – aws-cloudtrail-logs-signin-console. It also needs an IAM role. This is essential otherwise CloudTrail can’t send the events to CloudWatch. In these situations the console usually offers to create a new role, which I call CloudTrail-CloudWatchLogs-Signin-Console.
That’s it! Now that CloudWatch is receiving the logs it needs to know what to look for.
CloudWatch Metric Filters
The Metric Filters are going to look at events in the Log Group and use them to create data points for my alarms. There are two steps to creating a metric filter:
- A pattern must be defined for the filter.
- A metric must be assigned to the filter.
Defining A Pattern
CloudWatch needs to know the terms and/or patterns to look for in the Log Group. This is done by specifying a filter pattern, for which there is an AWS user guide about filter and pattern syntax.
For the signin-console-failure-iam alert, the filter will be:
{ $.eventSource = "signin.amazonaws.com" && $.eventName = "ConsoleLogin" && $.responseElements.ConsoleLogin = "Failure" && $.userIdentity.type = "IAMUser" }To break this down:
For limiting events to sign-ins I use $.eventSource = "signin.amazonaws.com". This will be the same for all filters.
I only want to know about AWS console logins so I add $.eventName = "ConsoleLogin". This will also be the same for all filters.
This filter only cares about failed events, so I need to add $.responseElements.ConsoleLogin = "Failure". This will change to "Success" for other filters.
Finally I want to limit this filter to IAM users, and so add $.userIdentity.type = "IAMUser". This will change to "root" for other filters.
To aid understanding, this will be the filter for the signin-console-success-root alert:
{ $.eventSource = "signin.amazonaws.com" && $.eventName = "ConsoleLogin" && $.responseElements.ConsoleLogin = "Success" && $.userIdentity.type = "root" }Assigning A Metric
CloudWatch now needs to know about the metrics to create. First it needs a name for the new filter, one for the metric itself and one for the namespace that will contain the metric.
Then I need to make some decisions about the metric values, which I set as follows:
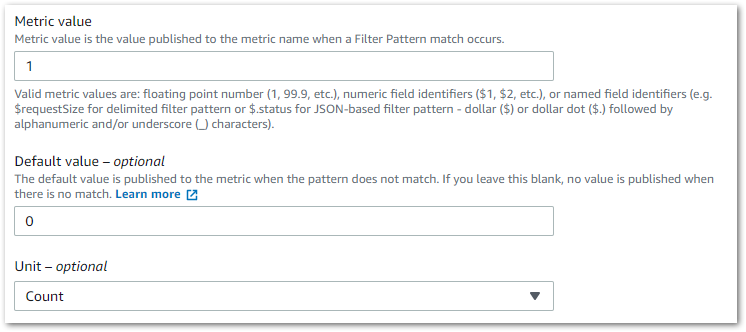
Nothing elaborate here – the metric will be one every time a matching event is found and zero otherwise. I originally left the default value blank but this led to some undesirable alarm behaviour, which I will go into later.
Speaking of alarms…
CloudWatch Alarms
At this point CloudWatch understands what I’m looking for but has no way to tell me if it finds anything. The alarms will provide that missing link!
Creating an alarm starts by selecting one of the new metrics and choosing how often CloudWatch will check it. Then I set the conditions the alarm will use:
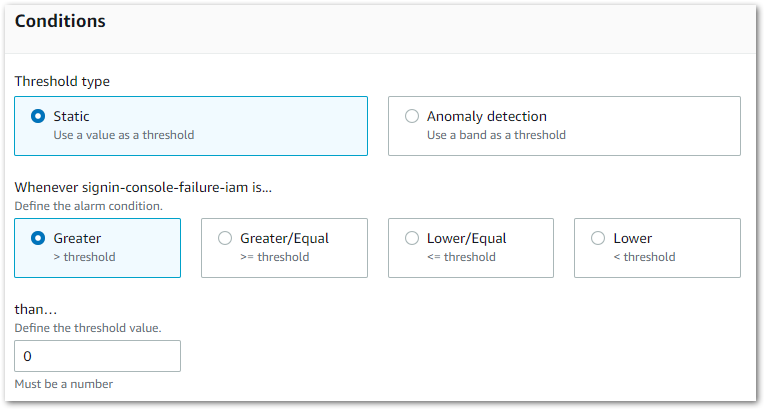
Here I want the alarm to trigger when the metric is greater than zero.
CloudWatch now needs to know what actions it must perform when an alarm triggers. CloudWatch alarms have three states:
OK(Green) – The metric or expression is within the defined thresholdIn Alarm(Red) – The metric or expression is outside of the defined threshold.Insufficient Data(Grey) – The alarm has just started, the metric is not available, or not enough data is available for the metric to determine the alarm state.
Here I tell CloudWatch to notify the signin-console-failure-iam SNS Topic when the corresponding metric is outside of the defined threshold of zero and enters the In Alarm state.
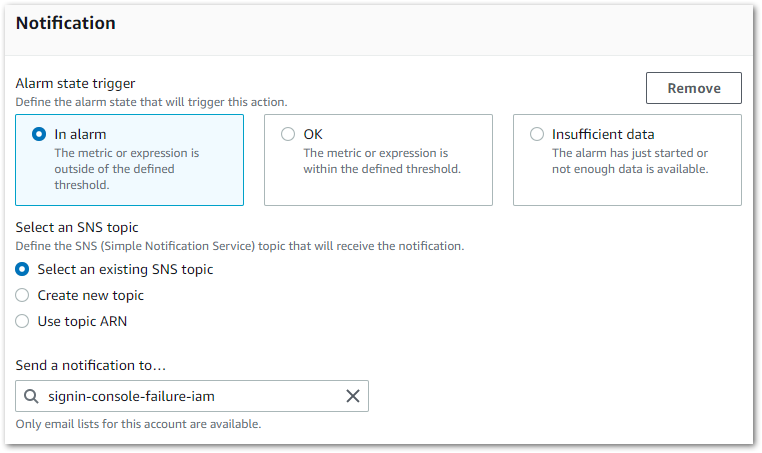
This is why I created the SNS resources first. It makes CloudWatch alarm creation a lot smoother.
Three additional alarms later I’m all done! As AWS provide ten custom metrics and ten alarms in the Always Free tier, my new CloudWatch setup will be free.
Insufficient Data (Grey) Alarms
Before moving on, let’s talk about grey alarms for a moment.
While grey alarms generally aren’t a problem in CloudWatch, they don’t look great from a human perspective. While green suggests everything’s fine and red suggests problems, grey is more vague. Everything could be ok. There might be problems. Not ideal.
This is why I set my default metric values to zero in the Metric Filters section. When no default value was set, CloudWatch considered the data to be missing and set the alarm state to Insufficient Data unless it was alerting. While this isn’t a problem, the DBA in me will always prefer green states to grey ones!
During an alarm’s configuration, it is possible to change the treatment of missing data:

I did try this out and it did work as expected – the grey alarm turned green when told to treat missing data as good. But this would mean that any missing data would be treated as good. That setting did not fill me with reassurance for this use case!
Does This All Work?
Let’s find out! I have four CloudWatch alarms, each partnered with a different SNS topic. This should mean I get a different notification for each type of event when the alarms trigger.
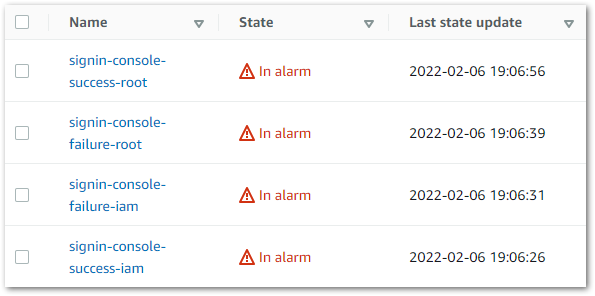
Here is my CloudWatch Alarms dashboard in its base state with no alarms triggered.
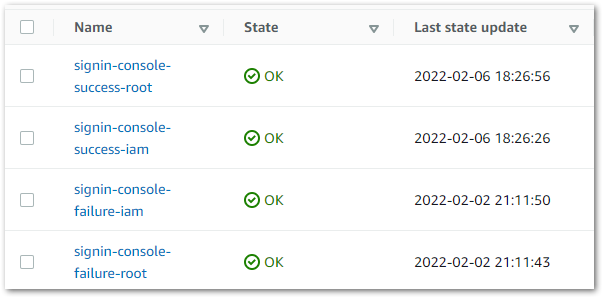
This is the same dashboard with all alarms triggered.
Failing to sign in as an IAM user triggered this email:

While a successful IAM sign-in triggered this one:

Failing to sign in as the root user triggered this email:

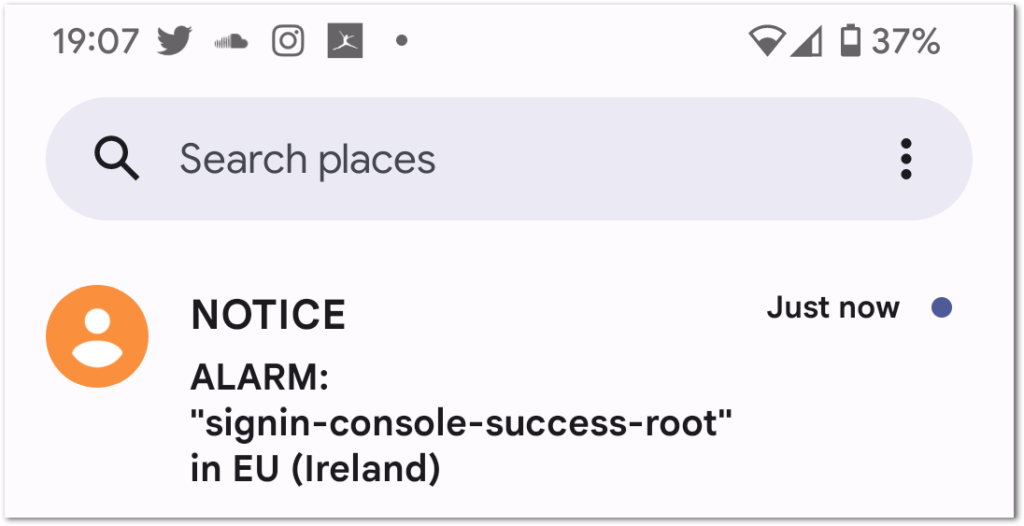
And a successful root sign in triggered this email:

And this SMS:
Cost Analysis
The eagle-eyed will have noticed that some of the dates in these screenshots are from early February. I was going to publish this post around that time too, but I wanted to finish my T-SQL Tuesday post first and then had a busy week.
This means I can demonstrate the actual costs of my security alerts though!
These AWS Billing screenshots are from 2022-02-13, so a week after the earlier screenshots. Be aware that, as IAM is always free, it has no entry on the bill.
First of all, CloudTrail and CloudWatch:
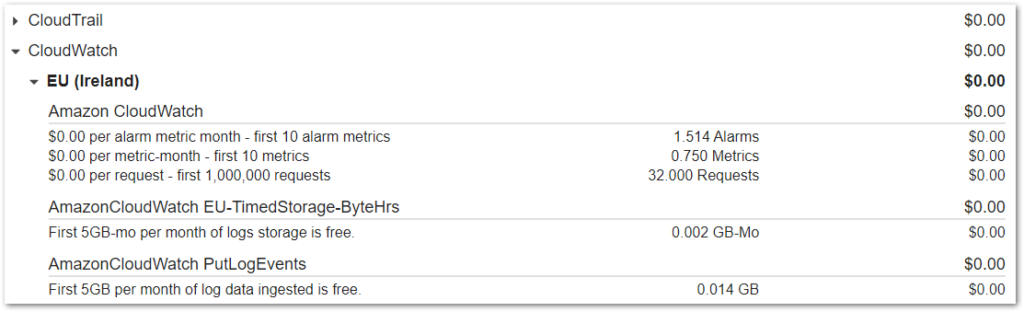
As expected, well within the AWS Always Free tier limits and no charges. Next is SNS:
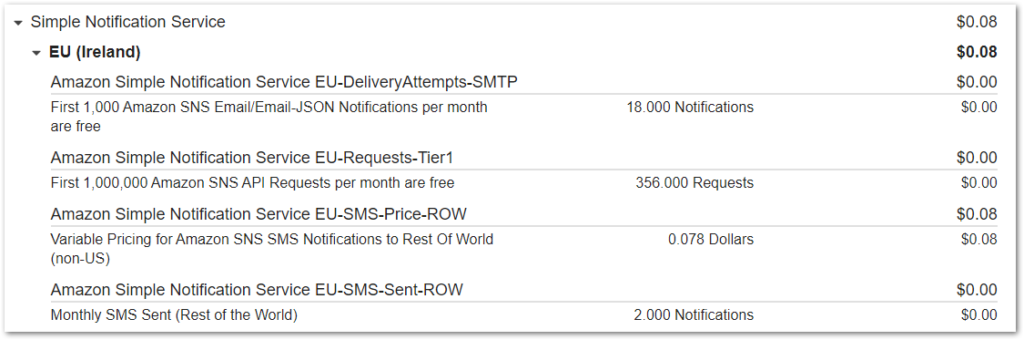
The cost here is for SMS notifications. I’ve triggered two in testing so that’s averaging 0.04 USD each. This cost is acceptable considering the peace of mind it gives – these are the notifications for the successful root account sign-ins!
Summery
In this post I’ve demonstrated how a number of AWS managed services work together to turn a collection of events into meaningful security alerts that give me peace of mind when I’m signed out of my AWS account. I’ve also analysed the costs of my setup and have used various AWS Always Free tier offerings to minimise the impact on my monthly AWS bill.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~
