
In this post, I use the data discovering features of AWS Glue to crawl and catalogue my WordPress API pipeline data.
Table of Contents
Introduction
By the end of my WordPress Bronze Data Orchestration post, I had created an AWS Step Function workflow that invokes two AWS Lambda functions:
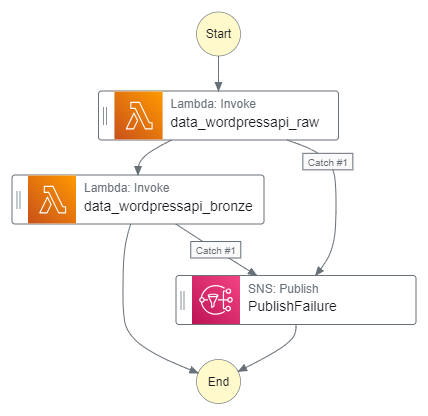
The data_wordpressapi_raw function gets data from the WordPress API and stores it as CSV objects in Amazon S3. The data_wordpressapi_bronze function transforms these objects to Parquet and stores them in a separate bucket. If either function fails, AWS SNS publishes an alert.
While this process works fine, the extracted data is not currently utilized. To derive value from this data, I need to consider transforming it. Several options are available, such as:
- Creating new Lambda functions.
- Importing the data into a database.
- Third-party solutions like Databricks.
Here, I’ve chosen to use AWS Glue. As a fully managed ETL service, Glue automates various data processes in a low-code environment. I’ve not written much about it, so it’s time that changed!
Firstly, I’ll examine AWS Glue and some of its concepts. Next, I’ll create some Glue resources that interact with my WordPress S3 objects. Finally, I’ll integrate those resources into my existing Step Function workflow and examine their costs.
Let’s begin with some information about AWS Glue.
AWS Glue Concepts
This section explores AWS Glue and some of its data discovering features.
AWS Glue
From the AWS Glue User Guide:
AWS Glue is a serverless data integration service that makes it easy for analytics users to discover, prepare, move, and integrate data from multiple sources. You can use it for analytics, machine learning, and application development. It also includes additional productivity and data ops tooling for authoring, running jobs, and implementing business workflows.
https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
Glue can be accessed using the AWS Glue console web interface and the AWS Glue Studio graphical interface. It can also be accessed programmatically via the AWS Glue CLI and the AWS Glue SDK.
Benefits of AWS Glue include:
- Data-specific features like data cataloguing, schema discovery, and automatic ETL code generation.
- Infrastructure optimised for ETL tasks and data processes.
- Built-in scheduling capabilities and job execution.
- Integration with other AWS services like Athena and Redshift.
AWS Glue’s features fall into Discover, Prepare, Integrate and Transform categories. The Glue features used in this post come from the data discovering category.
Glue Data Catalog
An AWS Glue Data Catalog is a managed repository serving as a central hub for storing metadata about data assets. It includes table and job definitions, and other control information for managing an AWS Glue environment. Each AWS account has a dedicated AWS Glue Data Catalog for each region.
The Data Catalog stores information as metadata tables, with each table representing a specific data store and its schema. Glue tables can serve as sources or targets in job definitions. Tables are organized into databases, which are logically grouped collections of related table definitions.
Each table contains column names, data type definitions, partition information, and other metadata about a base dataset. Data Catalog tables can be populated either manually or using Glue Crawlers.
Glue Crawler
A Glue Crawler connects to a data store, analyzes and determines its schema, and then creates metadata tables in the AWS Glue Data Catalog. They can run on-demand, be automated by services like Amazon EventBridge Scheduler and AWS Step Functions, and be started by AWS Glue Triggers.
Crawlers can crawl several data stores including:
- Amazon S3 buckets via native client.
- Amazon RDS databases via JDBC.
- Amazon DocumentDB via MongoDB client.
An activated Glue Crawler performs the following processes on the chosen data store:
- Firstly, data within the store is classified to determine its format, schema and properties.
- Secondly, data is grouped into tables or partitions.
- Finally, the Glue Data Catalog is updated. Glue creates, updates and deletes tables and partitions, and then writes the metadata to the Data Catalog accordingly.
Now let’s create a Glue Crawler!
Creating A Glue Crawler
In this section, I use the AWS Glue console to create and run a Glue Crawler for discovering my WordPress data.
Crawler Properties & Sources
There are four steps to creating a Glue Crawler. Step One involves setting the crawler’s properties. Each crawler needs a name and can have optional descriptions and tags. This crawler’s name is wordpress_bronze.
Step Two sets the crawler’s data sources, which is greatly influenced by whether the data is already mapped in Glue. If it is then the desired Glue Data Catalog tables must be selected. Since my WordPress data isn’t mapped yet, I need to add the data sources instead.
My Step Function workflow puts the data in S3, so I select S3 as my data source and supply the path of my bronze S3 bucket’s wordpress_api folder. The crawler will process all folders and files contained in this S3 path.
Finally, I need to configure the crawler’s behaviour for subsequent runs. I keep the default setting, which re-crawls all folders with each run. Other options include crawling only folders added since the last crawl or using S3 Events to control which folders to crawl.
Classifiers are also set here but are out of scope for this post.
Crawler Security & Targets
Step Three configures security settings. While most of these are optional, the crawler needs an IAM role to interact with other AWS services. This role consists of two IAM policies:
- An
AWSGlueServiceRoleAWS managed policy which allows access to related services including EC2, S3, and Cloudwatch Logs. - A customer-managed policy with
s3:GetObjectands3:PutObjectactions allowed on the S3 path given in Step Two.
This role can be chosen from existing roles or created with the crawler.
Step Four begins with setting the crawler’s output. The Crawler creates new tables, requiring the selection of a target database for these tables. This database can be pre-existing or created with the crawler.
An optional table name prefix can also be set, which enables easy table identification. I create a wordpress_api database in the Glue Data Catalog, and set a bronze- prefix for the new tables.
The Crawler’s schedule is also set here. The default is On Demand, which I keep as my Step Function workflow will start this crawler. Besides this, there are choices for Hourly, Daily, Weekly, Monthly or Custom cron expressions.
Advanced options including how the crawler should handle detected schema changes and deleted objects in the data store are also available in Step Four, although I’m not using those here.
And with that, my crawler is ready to try out!
Running The Crawler
My crawler can be tested by accessing it in the Glue console and selecting Run Crawler:
The crawler’s properties include run history. Each row corresponds to a crawler execution, recording data including:
- Start time, end time and duration.
- Execution status.
- DPU hours for billing.
- Changes to tables and partitions.

AWS stores the logs in an aws-glue/crawlers CloudWatch Log Group, in which each crawler has a dedicated log stream. Logs include messages like the crawler’s configuration settings at execution:
Crawler configured with Configuration
{
"Version": 1,
"CreatePartitionIndex": true
}
and SchemaChangePolicy
{
"UpdateBehavior": "UPDATE_IN_DATABASE",
"DeleteBehavior": "DEPRECATE_IN_DATABASE"
}And details of what was changed and where:
Table bronze-statistics_pages in database wordpress_api has been updated with new schemaChecking The Data Catalog
So what impact has this had on the Data Catalog? Accessing it and selecting the wordpress_api database now shows five tables, each matching S3 objects created by the Step Functions workflow:
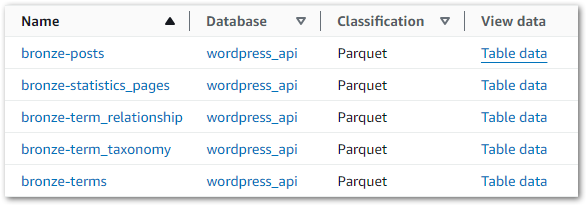
Data can be viewed by selecting Table Data on the desired row. This action executes an Athena query, triggering a message about the cost implications:
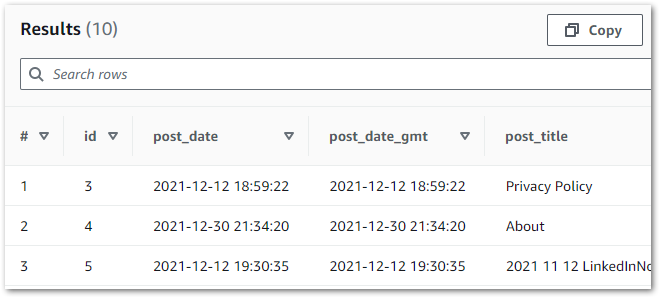
You will be taken to Athena to preview data, and you will be charged separately for Athena queries.If accepted, Athena generates and executes a SQL query in a new tab. In this example, the first ten rows have been selected from the wordpress_api database’s bronze-posts table:
SELECT *
FROM "AwsDataCatalog"."wordpress_api"."bronze-posts"
LIMIT 10;When this query is executed, Athena checks the Glue Data Catalog for the bronze-posts table in the wordpress_api database. The Data Catalog provides the S3 location for the data, which Athena reads and displays successfully:
Now that the crawler works, I’ll integrate it into my Step Function workflow.
Crawler Integration & Costs
In this section, I integrate my Glue Crawler into my existing Step Function workflow and examine its costs.
Architectural Diagrams
Let’s start with some diagrams. This is how the crawler will behave:

While updating the crawler’s wordpress_bronze CloudWatch Log Stream throughout:
- The
wordpress_bronzeGlue Crawler crawls the bronze S3 bucket’swordpress-apifolder. - The crawler updates the Glue Data Catalog’s
wordpress-apidatabase.
This is how the Crawler will fit into my existing Step Functions workflow:
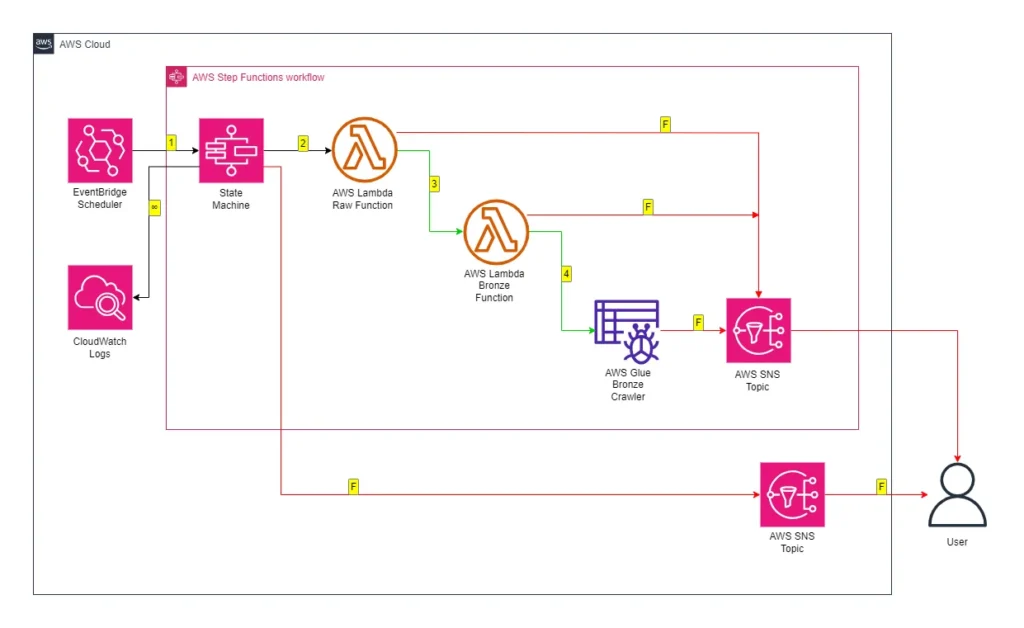
While updating the workflow’s CloudWatch Log Group throughout:
- An EventBridge Schedule executes the Step Functions workflow.
- Raw Lambda function is invoked.
- Invocation Fails: Publish SNS message. Workflow ends.
- Invocation Succeeds: Invoke Bronze Lambda function.
- Bronze Lambda function is invoked.
- Invocation Fails: Publish SNS message. Workflow ends.
- Invocation Succeeds: Run Glue Crawler.
- Glue Crawler runs.
- Run Fails: Publish SNS message. Workflow ends.
- Run Succeeds: Update Glue Data Catalog. Workflow ends.
An SNS message is published if the Step Functions workflow fails.
Step Function Integration
Time to build! Let’s begin with the crawler’s requirements:
- The crawler must only run after both Lambda functions.
- It must also only run if both functions invoke successfully first.
- If the crawler fails it must alert via the existing
PublishFailureSNS topic.
This requires adding an AWS Glue: StartCrawler action to the workflow after the second AWS Lambda: Invoke action:
This action differs from the ones I’ve used so far. The existing actions all use optimized integrations that provide special Step Functions workflow functionality.
Conversely, StartCrawler uses an SDK service integration. These integrations behave like a standard AWS SDK API call, enabling more fine-grained control and flexibility than optimised integrations at the cost of needing more configuration and management.
Here, the Step Functions StartCrawler action calls the Glue API StartCrawler action. After adding it to my workflow, I update the action’s API parameters with the desired crawler’s name:
{
"Name": "wordpress_bronze"
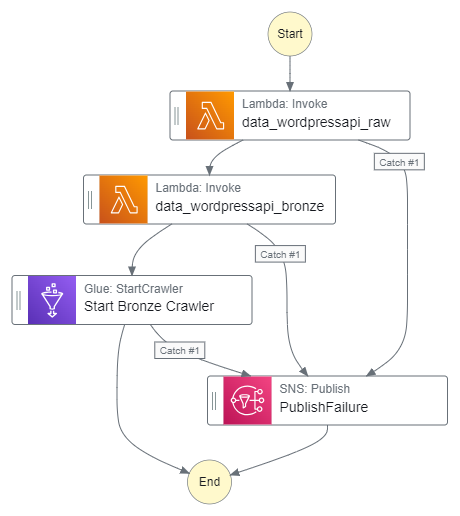
}Next, I update the action’s error handling to catch all errors and pass them to the PublishFailure task. These actions produce these additions to the workflow’s ASL code:
"Start Bronze Crawler": {
"Type": "Task",
"End": true,
"Parameters": {
"Name": "wordpress_bronze"
},
"Resource": "arn:aws:states:::aws-sdk:glue:startCrawler",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "PublishFailure"
}
]
},And result in an updated workflow graph:
Additionally, the fully updated Step Functions workflow ASL script can be viewed on my GitHub.
Finally, I need to update the Step Function workflow IAM role’s policy so that it can start the crawler. This involves allowing the glue:StartCrawler action on the crawler’s ARN:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowBronzeGlueCrawler",
"Effect": "Allow",
"Action": [
"glue:StartCrawler"
],
"Resource": [
"arn:aws:glue:eu-west-1:[REDACTED]:crawler/wordpress_bronze"
]
}My Step Functions workflow is now orchestrating the Glue Crawler, which will only run once both Lambda functions are successfully invoked. If either function fails, the SNS topic is published and the crawler does not run. If the crawler fails, the SNS topic is published. Otherwise, if everything runs successfully, the crawler updates the Data Catalog as needed.
So how much does discovering data with AWS Glue cost?
Glue Costs
This is from AWS Glue’s pricing page for crawlers:
There is an hourly rate for AWS Glue crawler runtime to discover data and populate the AWS Glue Data Catalog. You are charged an hourly rate based on the number of Data Processing Units (or DPUs) used to run your crawler. A single DPU provides 4 vCPU and 16 GB of memory. You are billed in increments of 1 second, rounded up to the nearest second, with a 10-minute minimum duration for each crawl.
$0.44 per DPU-Hour, billed per second, with a 10-minute minimum per crawler run
https://aws.amazon.com/glue/pricing/
And for the Data Catalog:
With the AWS Glue Data Catalog, you can store up to a million objects for free. If you store more than a million objects, you will be charged $1.00 per 100,000 objects over a million, per month. An object in the Data Catalog is a table, table version, partition, partition indexes, statistics or database.
The first million access requests to the Data Catalog per month are free. If you exceed a million requests in a month, you will be charged $1.00 per million requests over the first million. Some of the common requests are CreateTable, CreatePartition, GetTable , GetPartitions, and GetColumnStatisticsForTable.
https://aws.amazon.com/glue/pricing/
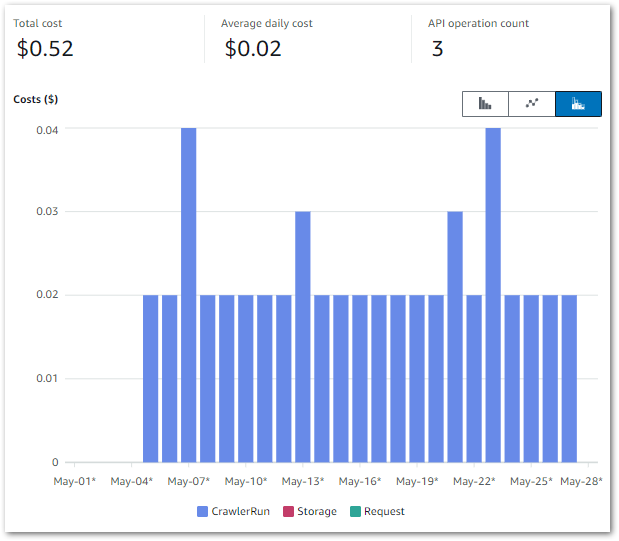
So how does this relate to my workflow? The below Cost Explorer chart shows my AWS Glue API costs from 01 May to 28 May. Only the CrawlerRun API operation has generated charges, with a daily average of $0.02:
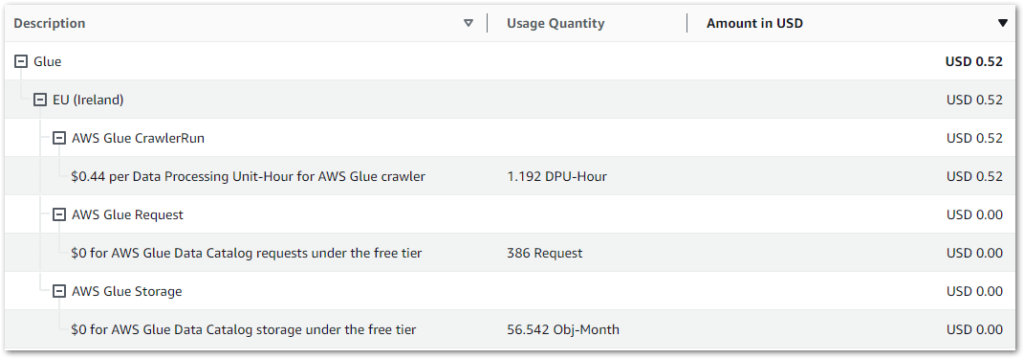
My May 2024 AWS bill shows further details on the requests and storage items. The Glue Data Catalog’s free tier covers my usage:
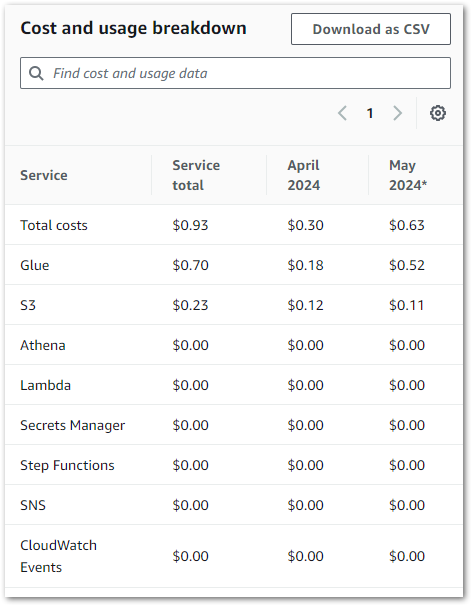
Finally, let’s review the entire pipeline’s costs for April and May. Besides Glue, my only other cost remains S3:
Summary
In this post, I used the data discovering features of AWS Glue to crawl and catalogue my WordPress API pipeline data.
Glue’s native features and integration with other AWS services make it a great fit for my WordPress pipeline’s pending processes. I’ll be using additional Glue features in future posts, and wanted to spotlight the Data Catalog early on as it’ll become increasingly helpful as my use of AWS Glue increases.
If this post has been useful then the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~