
In this post I’ll be using Amazon Athena to query data created by the S3 Inventory service.
When I wrote about my first impressions of S3 Glacier Instant Retrieval last month, I noticed some of my S3 Inventory graphs showed figures I didn’t expect. I couldn’t remember many of the objects in the InMotion bucket, and didn’t know that some were in Standard! I went through the bucket manually and found the Standard objects, but still had other questions that I wasn’t keen on solving by hand.
So while I was on-call over Christmas I decided to take a closer look at Athena – the AWS serverless query service designed to analyse data in S3. I’ve used existing setups at work but this was my first time experiencing it from scratch, and I made use of the AWS documentation about querying Amazon S3 Inventory with Amazon Athena and the Andy Grimes blog “Manage and analyze your data at scale using Amazon S3 Inventory and Amazon Athena” to fill in the blanks.
We’ve Got a File On You
First I created an empty s3inventory Athena database. Then I created a s3inventorytable table using the script below, specifying the 2022-01-01 symlink.txt Hive object created by S3 Inventory as the data source:
CREATE EXTERNAL TABLE s3inventorytable(
bucket string,
key string,
version_id string,
is_latest boolean,
is_delete_marker boolean,
size bigint,
last_modified_date bigint,
e_tag string,
storage_class string,
is_multipart_uploaded boolean,
replication_status string,
encryption_status string,
object_lock_retain_until_date bigint,
object_lock_mode string,
object_lock_legal_hold_status string,
intelligent_tiering_access_tier string,
bucket_key_status string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://[REDACTED]/hive/dt=2022-01-01-01-00/';Then I ran a query to determine the storage classes in use in the InMotion bucket and the number of objects assigned to each:
SELECT storage_class, count(*)
FROM "s3inventory"."s3inventorytable"
GROUP BY storage_class
ORDER BY storage_classThe results were as follows:

41 Standard objects?! I wasn’t sure what they were and so added object size into the query:
SELECT storage_class, count(*), sum(size)
FROM "s3inventory"."s3inventorytable"
GROUP BY storage_class
ORDER BY storage_class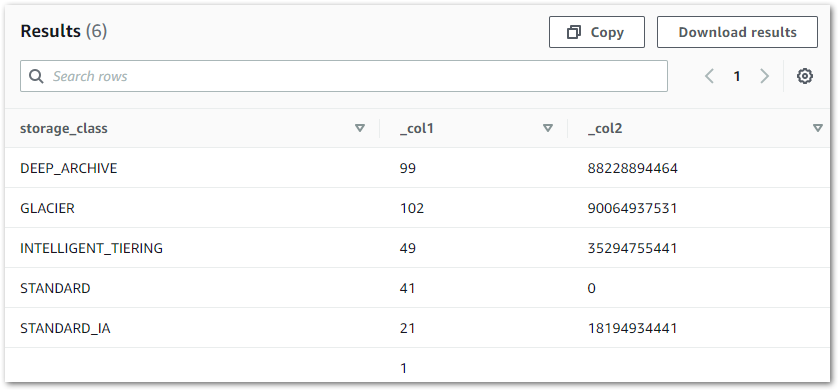
The zero size and subsequent investigations confirmed that the Standard objects were prefixes, and so presented no problems.
Next, I wanted to check for unwanted previous versions of objects using the following query:
SELECT key, size
FROM "s3inventory"."s3inventorytable"
WHERE is_latest = FALSEThis query returned another prefix, so again there were no actions needed:

Further investigation found that this prefix also has no storage class assigned to it, as seen in the results above.
For Old Time’s Sake
I then wanted to see the youngest and oldest objects for each storage class, and ran the following query:
SELECT storage_class,
MIN(last_modified_date),
MAX(last_modified_date)
FROM "s3inventory"."s3inventorytable"
GROUP BY storage_class
ORDER BY storage_class
What I got back was unexpected:

S3 Inventory stores dates as Unix Epoch Time, so I needed a function to transform the data to a human-legible format. Traditionally this would involve CAST or CONVERT, but as Athena uses Presto additional functions are available such as from_unixtime:
Returns the UNIX timestamp
from_unixtime(unixtime) → timestampunixtimeas a timestamp.
I updated the query to include this function:
SELECT storage_class,
MIN(from_unixtime(last_modified_date)),
MAX(from_unixtime(last_modified_date))
FROM "s3inventory"."s3inventorytable"
GROUP BY storage_class
ORDER BY storage_classThis time the dates were human-legible but completely inaccurate:

I then found a solution in Stack Overflow, where a user suggested converting a Unix Epoch Time value from microseconds to milliseconds. I applied this suggestion to my query by dividing the last modified dates by 1000:
SELECT storage_class,
MIN(from_unixtime(last_modified_date/1000)),
MAX(from_unixtime(last_modified_date/1000))
FROM "s3inventory"."s3inventorytable"
GROUP BY storage_class
ORDER BY storage_classThe results after this looked far more reasonable:

And EpochConverter confirmed the human time was correct for the Deep Archive MIN(last_modified_date) Unix value of 1620147401000:

So there we go! An introduction to Athena and utilization of the data from S3 Inventory!
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~