In this post I make my existing Python code re-runnable by enabling it to replace expired access tokens when it sends requests to the Strava API.
A couple of posts ago I wrote about authenticating Strava API calls. I ended up successfully requesting data using this Python code:
import requests
activities_url = "https://www.strava.com/api/v3/athlete/activities"
header = {'Authorization': 'Bearer ' + "access_token"}
param = {'per_page': 200, 'page': 1}
my_dataset = requests.get(activities_url, headers=header, params=param).json()
print(my_dataset)Although successful, the uses for this code are limited as it stops working when the header’s access_token expires. Ideally the code should be able to function constantly once Strava grants initial authorisation, which is what I’m exploring here. Plus the last post was unclear in places so this one will hopefully tie up some loose ends.
Please note that I have altered or removed all sensitive codes and tokens in this post in the interests of security.
The Story So Far
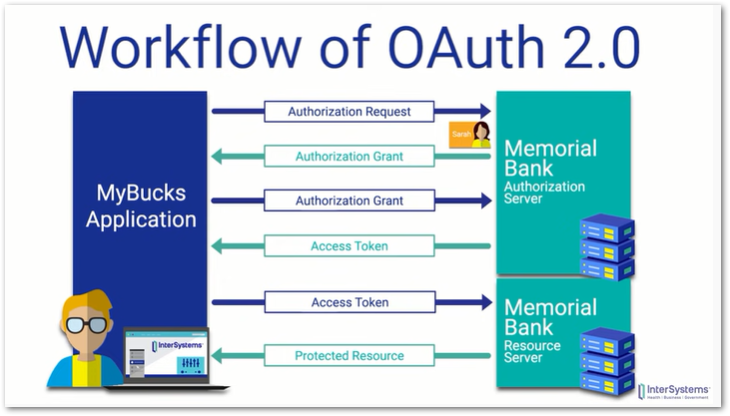
First of all, some reminders. Strava uses OAuth 2.0 for authentication, and this is a typical OAuth 2.0 workflow:
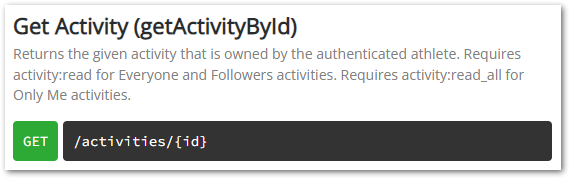
I am sending GET requests to Strava via Get Activity. Strava’s documentation for this is as follows:
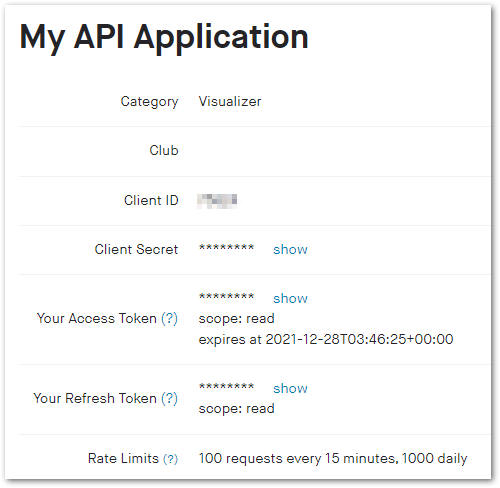
Finally, during my initial setup I created an API Application on the Strava site. Strava provided these details upon completion:
Authorizing My App To View Data
Strava’s Getting Started page explains that they require authentication via OAuth 2.0 for data requests and gives the following link for that process:
http://www.strava.com/oauth/authorize?client_id=[REPLACE_WITH_YOUR_CLIENT_ID]&response_type=code&redirect_uri=http://localhost/exchange_token&approval_prompt=force&scope=readI must amend this URL as scope=read is insufficient for Get Activity requests. The end of the URL becomes scope=activity:read_all and the updated URL loads a Strava authorization screen:
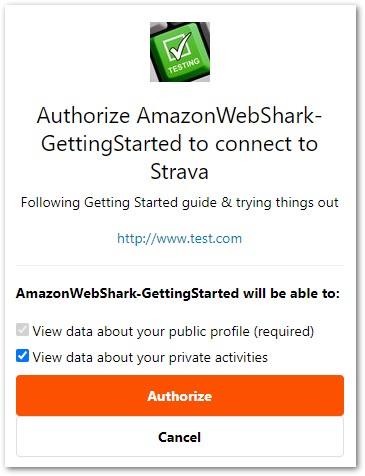
Selecting Authorize gives the following response:
http://localhost/exchange_token?state=&code=CODE9fbb&scope=read,activity:read_allWhere code=CODE9fbb is a single-use authorization code that I will use to create access tokens.
Getting Tokens For API Requests
Next I will use CODE9fbb to request access tokens which Get Activity will accept. This is done via the following cURL request:
curl -X POST https://www.strava.com/api/v3/oauth/token \
-d client_id=APIAPP-CLIENTID \
-d client_secret=APIAPP-SECRET \
-d code=CODE9fbb \
-d grant_type=authorization_codeHere, Client_ID and Client_Secret are from my API application, Code is the authorization code CODE9fbb and Grant_Type is what I’m asking for – Strava’s Authentication documentation states this must always be authorization_code for initial authentication.
Strava then responds to my cURL request with a refresh token, access token, and access token expiration date in Unix Epoch format:
"token_type": "Bearer",
"expires_at": 1642370007,
"expires_in": 21600,
"refresh_token": "REFRESHc8c4",
"access_token": "ACCESS22e5",Why two tokens? Access tokens expire six hours after they are created and must be refreshed to maintain access to the desired data. Strava uses the refresh tokens as part of the access token refresh process.
Writing The API Request Code
With the tokens now available I can start assembling the Python code for my Strava API requests. I will again be using Visual Studio Code here. I make a new Python virtual environment called StravaAPI by running py -3 -m venv StravaAPI, activate it using StravaAPI\Scripts\activate and run pip install requests to install the module I need. Finally I create an empty StravaAPI.py file in the StravaAPI virtual environment folder for the Python code.
Onto the code. The first part imports the requests module, declares some variables and sets up a request to refresh an expired access code as detailed in the Strava Authentication documentation:
# Import modules
import requests
# Set Variables
apiapp_clientid = "APIAPP-CLIENTID"
apiapp_secret = 'APIAPP-SECRET'
token_refresh = 'REFRESHc8c4'
# Requesting Access Token
url_oauth = "https://www.strava.com/oauth/token"
payload_oauth = {
'client_id': apiapp_clientid,
'client_secret': apiapp_secret,
'refresh_token': token_refresh,
'grant_type': "refresh_token",
'f': 'json'
}Note this time that the Grant_Type is refresh_token instead of authorization_code. These variables can then be used by the requests module to send a request to Strava’s API:
print("Requesting Token...\n")
req_access_token = requests.post(url_oauth, data=payload_oauth, verify=False)
print(req_access_token.json())This request is successful and returns existing tokens ACCESS22e5 and REFRESHc8c4 as they have not yet expired:
Requesting Token...
{'token_type': 'Bearer', 'access_token': 'ACCESS22e5', 'expires_at': 1642370008, 'expires_in': 20208, 'refresh_token': 'REFRESHc8c4'}A warning is also presented here as my request is not secure:
InsecureRequestWarning: Unverified HTTPS request is being made to host 'www.strava.com'. Adding certificate verification is strongly advised.The warning includes a link to urllib3 documentation, which states:
Making unverified HTTPS requests is strongly discouraged, however, if you understand the risks and wish to disable these warnings, you can use
disable_warnings()
As this code is currently in development, I import the urllib3 module and disable the warnings:
# Import modules
import requests
import urllib3
# Disable Insecure Request Warnings
urllib3.disable_warnings()Next I extract the access token from Strava’s response into a new token_access variable and print that in the terminal as a process indicator:
print("Requesting Token...\n")
req_access_token = requests.post(url_oauth, data=payload_oauth, verify=False)
token_access = req_access_token.json()['access_token']
print("Access Token = {}\n".format(token_access))So far the terminal’s output is:
Requesting Token...
Access Token = ACCESS22e5Let’s get some data! I’m making a call to Get Activities now, so I declare three variables to compose the request and include the token_access variable from earlier :
# Requesting Athlete Activities
url_api_activities = "https://www.strava.com/api/v3/athlete/activities"
header_activities = {'Authorization': 'Bearer ' + token_access}
param_activities = {'per_page': 200, 'page' : 1}Then I use the requests module to send the request to Strava’s API:
print("Requesting Athlete Activities...\n")
dataset_activities = requests.get(url_api_activities, headers=header_activities, params=param_activities).json()
print(dataset_activities)And receive data about several recent activities as JSON in return. Success! The full Python code is as follows:
# Import modules
import requests
import urllib3
# Disable Insecure Request Warnings
urllib3.disable_warnings()
# Set Variables
apiapp_clientid = "APIAPP-CLIENTID"
apiapp_secret = 'APIAPP-SECRET'
token_refresh = 'REFRESHc8c4'
# Requesting Access Token
url_oauth = "https://www.strava.com/oauth/token"
payload_oauth = {
'client_id': apiapp_clientid,
'client_secret': apiapp_secret,
'refresh_token': token_refresh,
'grant_type': "refresh_token",
'f': 'json'
}
print("Requesting Token...\n")
req_access_token = requests.post(url_oauth, data=payload_oauth, verify=False)
token_access = req_access_token.json()['access_token']
print("Access Token = {}\n".format(token_access))
# Requesting Athlete Activities
url_api_activities = "https://www.strava.com/api/v3/athlete/activities"
header_activities = {'Authorization': 'Bearer ' + token_access}
param_activities = {'per_page': 200, 'page' : 1}
print("Requesting Athlete Activities...\n")
dataset_activities = requests.get(url_api_activities, headers=header_activities, params=param_activities).json()
print(dataset_activities)But Does It Work?
This only leaves the question of whether the code works when the access code expires. As a reminder this was Strava’s original response:
Requesting Token...
{'token_type': 'Bearer', 'access_token': 'ACCESS22e5', 'expires_at': 1642370008, 'expires_in': 20208, 'refresh_token': 'REFRESHc8c4'}Expiry 1642370008 is Sunday, 16 January 2022 21:53:28. I run the code at 22:05 and:
Requesting Token...
{'token_type': 'Bearer', 'access_token': 'ACCESSe0e7', 'expires_at': 1642392321, 'expires_in': 21559, 'refresh_token': 'REFRESHc8c4'}A new access token! The new expiry 1642392321 is Monday, 17 January 2022 04:05:21. And when I run the code at 09:39:
{'token_type': 'Bearer', 'access_token': 'ACCESS74dd', 'expires_at': 1642433966, 'expires_in': 21600, 'refresh_token': 'REFRESHc8c4'}A second new access code. All working fine! As long as my refresh token remains valid I can continue to get valid access tokens when they expire.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~