I first found O’Reilly books a few years back in a Data Engineering-themed Humble Bundle. Since then, I’ve built an extensive library of both e-books and physical books, with many more on my Amazon wish list. At the start of 2025, I decided to actually start reading them…
So far, I’ve finished three. Now, I don’t feel compelled to review them all. But having finished Practical Lakehouse Architecture I decided to start the Shark Shelf. This will be an occasional series of review posts about books that I really like, or that deserve some fanfare. And yes – How To Solve Itbelongs on the Shark Shelf.
Now let’s talk about Practical Lakehouse Architecture.
The Author
Gaurav Ashok Thalpati hails from Pune, India, where he’s worked as an independent cloud data consultant for decades. He’s a blogger and YouTuber, holds multiple data certifications and is an AWS Community Builder.
In July 2024, O’Reilly published his first book, Practical Lakehouse Architecture.
The Book
From the Practical Lakehouse Architecture blurb:
This guide explains how to adopt a data lakehouse architecture to implement modern data platforms. It reviews the design considerations, challenges, and best practices for implementing a lakehouse and provides key insights into the ways that using a lakehouse can impact your data platform, from managing structured and unstructured data and supporting BI and AI/ML use cases to enabling more rigorous data governance and security measures.
Practical Lakehouse Architecture was released in July 2024. It is available in both physical and eBook forms from O’Reilly, Amazon US, Amazon UK and eBooks.
Motivations
Reading a book?! In 2025?! I know, right? This section examines my motivations for buying and reading Practical Lakehouse Architecture.
Project Wolfie
I recently wrote about the beginning of Project Wolfie. I kinda expected to have started coding by now. Instead, most of my work is currently on paper and whiteboards. But there’s a good reason for this.
Project Wolfie is greenfield. I don’t have any existing code or resources, and I can use modern tools freely. However, with this freedom comes responsibility. Every choice I make now affects the architecture and involves tradeoffs. As much as I want to start working on the deliverables, I also want to make sensible decisions that can withstand scrutiny.
My hope with Practical Lakehouse Architecture was that it would help me with critical areas like observability, CI/CD, and security. Because it’s not that there isn’t advice online…
Advice Spread Thin
Lakehouse architectures are relatively recent in the data landscape. As a result, their understanding is not as established as that of data warehouses and data lakes, and some aspects of Lakehouse architecture are still evolving.
Many Lakehouse resources are either brief overviews, opinionated deep dives into specific use cases or marketing posts acting as best practices. This makes it hard to find balanced advice. My hope with Practical Lakehouse Architecture was that it would offer clear, unbiased views.
Professional Curiosity
As of 2025, I’ve spent nearly a decade in technical data roles. And in that time I’ve seen massive changes in data management, ranging from a server cupboard in Stockport to huge, multi‑region distributed data platforms.
Over the years, I’ve cultivated a passion for data technology, evolving from writing blog posts and speaking at meetups to working as an AWS consultant. As an AWS Community Builder in the Data category, I can access early previews and best practices from AWS experts. Additionally, as an AWS User Group Leader, I help attendees and guest speakers discuss data patterns.
With this in mind, I was curious about what new insights Practical Lakehouse Architecture could offer me.
Book Review
Onto the review! In this section, I’ll summarise the chapters and examine what stood out in each.
Chapters 1 – 3
The first set of chapters introduces the foundations of Lakehouse architecture, comparing it with traditional models and exploring the importance of storage in modern data platforms.
Chapter 1: Introduction to Lakehouse Architecture lays the groundwork for the book, putting all readers on equal footing for the chapters ahead. Gaurav starts by defining and exploring the ideas and concepts of various data architectures. He then examines the characteristics, evolution and benefits of the Lakehouse architecture.
Chapter 2: Traditional Architectures and Modern Platforms contrasts the Lakehouse architecture with traditional data lakes and data warehouses, outlining the benefits and limitations of each. Gaurav then shifts his focus to how modern cloud platforms have transformed these traditional architectures.
I like how Gaurav hasn’t dismissed lakes and warehouses here. Both are proven and well-understood options, and they are still the better choice in certain situations over Lakehouses.
Chapter 3: Storage: The Heart Of The Lakehouse examines the various factors surrounding data storage. Gaurav looks at row-based and column-based storage formats. He then explains the features and uses of Parquet, ORC, and Avro. He also compares newer open table formats, like Iceberg, Hudi, and Delta Lake, highlighting their similarities, differences, and use cases.
This is one area where the book really shines. Having topics like this explained clearly in one place, without having to go online, is incredibly useful!
Chapters 4 – 6
Next, these chapters focus on the operational and organisational elements of Lakehouse architectures. Topics include metadata management, compute engines, and governance. These elements are essential for effectively scaling and securing a modern data platform.
Chapter 4: Data Catalogs explores the purpose of data catalogs and the different types of metadata they can contain. It explains how catalogs support essential processes such as classification, governance, and lineage. Gaurav also compares data catalog implementations across AWS, Azure, and GCP.
Including multi-cloud examples both broadens the chapter’s scope and reinforces the cloud-agnostic nature of Lakehouse architecture – an important theme of the book.
Chapter 5: Compute Engines for Lakehouse Architectures examines compute options for batch and real-time data processing. Gaurav covers open-source tools such as Spark, Flink, and Presto, as well as cloud-native services like AWS Glue, Google BigQuery, and Databricks. He offers practical advice for selecting a compute engine, considering factors such as provisioning complexity, open-source support and AI/ML capabilities.
Chapter 6: Data and AI Governance and Security in Lakehouse Architecture explores governance and security, crucial areas for any production-ready data platform. Gaurav discusses core topics such as data quality, ownership, sensitivity and compliance. He also explores how governance responsibilities span both business and technical domains, emphasising the importance of organisational roles in maintaining control and oversight.
Chapters 7 – 9
Finally, these chapters focus on the practical realities of Lakehouse implementation – moving between theory and practice, and looking ahead to the architecture’s potential future.
Chapter 7: The Big Picture: Designing and Implementing a Lakehouse Platform examines considerations ranging from requirements gathering to defining business goals. Recommended Lakehouse zones are analysed and explained, and the expectations for each zone are defined. Finally, CICD is considered, and a sample design questionnaire is provided to help guide implementation planning.
Zones, or layers, are currently one of the most contentious areas of Lakehouse architectures. I like Gaurav’s stance on this – it’s somewhat similar to Simon Whiteley‘s. Yup – this video again.
Chapter 8: Lakehouse in the Real World does something I don’t see often – contrasting ideal scenarios with real-world events. It covers key stages in a Lakehouse’s development like analysis, testing and maintenance, examining what could go wrong and offering mitigation strategies.
This section is definitely accurate, as I’ve encountered some of these factors! It includes comparing greenfield and brownfield implementations, examining how business constraints affect technology choices, and considering if the desired RPO and RTO targets are financially and logistically possible.
Finally, Chapter 9: Lakehouse Of The Future looks ahead, exploring how Lakehouses might evolve in the years to come. Gaurav discusses potential intersections with trends like Data Mesh, Zero ETL and AI model integration. He also introduces emerging technologies like Delta UniForm and Apache XTable, which aim to improve interoperability across data processing systems and query engines. Finally, he touches on future innovations such as Apache Puffin and Ververica Streamhause that could further transform the data landscape.
(Sidenote: this Dremio post explores UniFrom and XTable very well.)
Thoughts
Having finished the book (in two weeks no less!), here are my thoughts:
Firstly, it’s not an intimidating read. At 283 pages, Practical Lakehouse Architecture is authoritative and content-rich without being overly complex or wordy. It also uses familiar O’Reilly conventions and style. When placed next to similar books I own, like The Data Warehouse Toolkit (600 pages) and Designing Data-Intensive Applications (614 pages), it’s easier to pick up and get into. And with some books, that’s a battle in itself!
Also, Practical Lakehouse Architecture‘s flow is very natural and the chapters make their points very well. I find some technical books, including some O’Reilly ones, hard to follow because they feel disjointed and jargon-heavy. That wasn’t the case here. The book held my attention very well throughout, and will serve me well as a future reference point.
Practical Lakehouse Architecture also feels like it will be relevant for a while. Some of my technical books have sections that are now outdated due to rapid technological changes. Here, ideas such as decoupled storage and compute, unified governance, and data personas will continue to matter for years to come.
Overall, an excellent book that I enjoyed reading.
Summary
In this post, I reviewed Gaurav Ashok Thalpati’s 2024 book ‘Practical Lakehouse Architecture‘ published by O’Reilly Media.
Ultimately, Practical Lakehouse Architecture is a well-written and informative book that caters to a wide range of skills. It’s a strong addition to the O’Reilly catalogue and complements titles like Rukmani Gopalan‘s 2022 book, The Cloud Data Lake, which I’m currently reading. It’s a great knowledge source for this constantly evolving modern data architecture.
If this post has been useful then the button below has links for contact, socials, projects and sessions:
I’ve become an AWS Step Functions convert in recent times. Back in 2020 when I first studied it for some AWS certifications, Step Functions defined workflows entirely in JSON, making it less approachable and often overlooked.
How times change! With 2021’s inclusion of a visual editor, Step Functions became far more accessible, helping it become a key tool in serverless application design. And in 2024 two major updates significantly enhanced Step Functions’ flexibility: JSONata support, which I recently explored, and built-in variables, which simplify state transitions and data management. This post focuses on the latter.
To demonstrate the power of Step Functions variables, I’ll walk through a practical example: fetching API data, verifying the response, and inserting it into DynamoDB. Firstly, I’ll examine the services and features I’ll use. Then I’ll create a state machine and examine each state’s use of variables. Finally, I’ll complete some test executions to ensure everything works as expected.
If a ‘simplified’ workflow seems hard to justify as a 20-minute read…that’s fair. But mastering Step Functions variables now can save hours of debugging and development in the long run! – Ed
Also, special thanks to AWS Community Builder Md. Mostafa Al Mahmud for generously providing AWS credits to support this and future posts!
Architecture
This section provides a top-level view of the architecture behind my simplified Step Functions variables workflow, highlighting the main AWS services involved in getting and processing API data. I’ll briefly cover the data being used, the role of Step Functions variables and the integration of DynamoDB within the workflow.
API Data
The data comes from a RESTful API that provides UK car details. The API needs both an authentication key and query parameters. Response data is provided in JSON.
The data used in this post is about my car. As some of it is sensitive, I will only use data that is already publicly available:
Step Functions variables offer a simple way to store and reuse data within a state machine, enabling dynamic workflows without complex transformations. They work well with both JSONata and JSONPath and are available at no extra cost in all AWS regions that support Step Functions.
Variables are set using Assign. They can be assigned static values for fixed values:
As well as dynamic values for changing values. To dynamically set variables, Step Functions uses JSONata expressions within {% ... %}. The following example extracts productName and available from the state input using the JSONata $states reserved variable:
Variables are then referenced using dollar signs ($), e.g. $productName.
There’s tonnes more to this. For details on name syntax, ASL integration and creating JSONPath variables, check the Step Functions Developer Guide variables section. Additionally, watch AWS Principal Developer Advocate Eric Johnson‘s related video:
With Step Functions variables handling data transformation and persistence, the next step is storing processed data efficiently. This is where Amazon DynamoDB comes in.
Amazon DynamoDB
DynamoDB is a fully managed NoSQL database built for high performance and seamless scalability. Its flexible, schema-less design makes it perfect for storing and retrieving JSON-like data with minimal overhead.
DynamoDB can automatically scale to manage millions of requests per second while maintaining low latency. It integrates seamlessly with AWS services like Lambda and API Gateway, providing built-in security, automated backups, and global replication to ensure reliability at any scale.
Popular use cases include:
Serverless backends (paired with AWS Lambda/API Gateway) for API-driven apps.
Real-time workloads like user sessions, shopping carts, or live leaderboards.
High-velocity data streamsfrom IoT devices or clickstream analytics.
Diagram
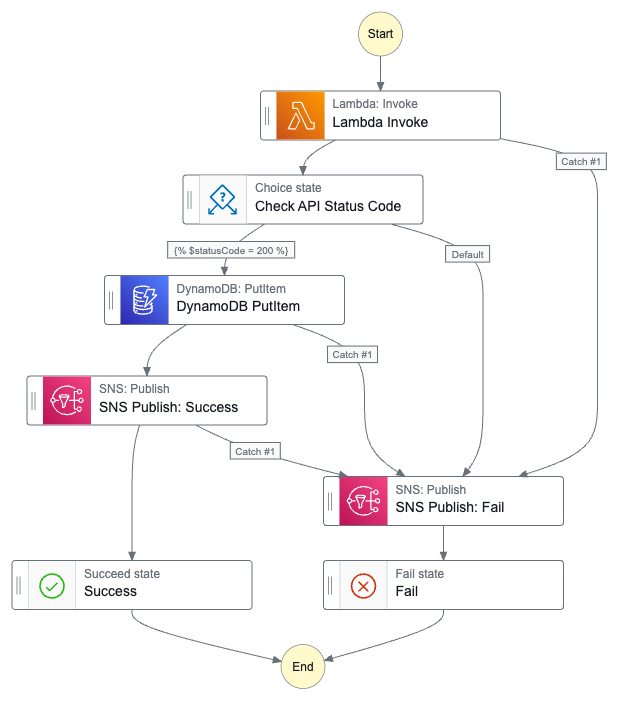
Finally, here is an architectural diagram of my simplified Step Functions variables workflow:
In which:
The user triggers an AWS Step Functions state machine with a JSON key-value pair as input.
A Lambda function is invoked with the input payload.
The Lambda function sends a POST request to a third-party API.
The API server responds with JSON data.
The Lambda function assigns Step Functions variables to store API response values and enters a Choice state that checks the API response code.
If the Choice state condition fails, SNS publishes a failure notification email.
The state machine terminates with an ExecutionFailed status.
If the Choice state condition passes, the processed API response data is written to a DynamoDB table.
SNS publishes a success notification email.
The state machine terminates with an ExecutionSucceeded status.
If an error occurs at any point in execution, SNS publishes a failure notification email and the state machine terminates with an ExecutionFailed status.
Resources
In this section, I create and configure my simplified Step Functions variables workflow resources, which are:
AWS Lambda function
AWS Step Functions Choice state
Amazon DynamoDB table
Amazon SNS topic
AWS Lambda
This section details how I created an AWS Lambda function to interact with a REST API. The function makes a secure POST request, manages potential errors and parses the response for use in downstream states. Additionally, I will discuss an issue I encountered while attempting to create variables from the function’s output using JSONata.
Lambda Function
First, I need to write a function. It’s nothing special – I have the API link and security key I need, and I just want to retrieve some data. So I decided to give Amazon Q Developer a try!
I used this prompt:
I have an HTTPS hyperlink for a REST API and an API key. I want to send a POST request to the API using the key. I have a USERID parameter that I will pass as JSON.
Please write a Python function for AWS Lambda with error handling. Please use security best practises and Pythonic standards.
Yes I do say Please in my prompts.
Amazon Q produced a decent script with:
API endpoint and key stored as environment variables.
Use of the requests module with a timeout to prevent indefinite hangs.
Error handling for request failures, validation errors, and unexpected issues.
A structured JSON response including the status code and parsed response.
Python
import jsonimport osimport loggingimport requestsfrom typing import Dict, Anyfrom botocore.exceptions import ClientError# Configure logginglogger = logging.getLogger()logger.setLevel(logging.INFO)deflambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:""" AWS Lambda function to make POST request to API endpoint Args: event: Lambda event object containing request data context: Lambda context object Returns: API response as dictionary """try:# Get API endpoint and key from environment variables api_endpoint = os.environ['API_ENDPOINT'] api_key = os.environ['API_KEY']# Extract user ID from event user_id = event.get('userId')ifnot user_id:raiseValueError("userId is required in the request")# Set request headers headers = {'Content-Type': 'application/json','x-api-key': api_key }# Prepare request payload payload = {'userId': user_id }# Make POST request response = requests.post( api_endpoint,headers=headers,json=payload,timeout=30# Set timeout for the request )# Raise exception for bad status codes response.raise_for_status()return {'statusCode': response.status_code,'body': response.json() }except requests.exceptions.RequestException as e: logger.error(f"API request failed: {str(e)}")return {'statusCode': 500,'body': json.dumps({'error': 'Failed to make API request'}) }exceptValueErroras e: logger.error(f"Validation error: {str(e)}")return {'statusCode': 400,'body': json.dumps({'error': str(e)}) }exceptExceptionas e: logger.error(f"Unexpected error: {str(e)}")return {'statusCode': 500,'body': json.dumps({'error': 'Internal server error'}) }
It needed some tweaks for my purposes, but was still faster than typing it all out manually!
Step Functions Config
The Lambda: Invoke action defaults to using the state input as the payload, so "Payload": "{% $states.input %}" is scripted automatically:
JSON
"Lambda Invoke": {"Type": "Task","Resource": "arn:aws:states:::lambda:invoke","Output": "{% $states.result.Payload %}","Arguments": {"FunctionName": "[LAMBDA_ARN]:$LATEST","Payload": "{% $states.input %}" },"Next": "Check API Status Code" }
This is going to be helpful in the next section!
Step Functions manages retries and error handling. If my Lambda function fails, it will retry up to three times with exponential backoff before sending a failure notification through SNS:
I mentioned earlier about Lambda: Invoke‘s default Payload setting. This default creates a {% $states.result.Payload %} JSONata expression output that I can use to assign variables for downstream states.
In this example, {% $states.result.Payload %} returns this:
Let’s make a variable for statusCode. In the response, statusCode is a property of Payload:
JSON
{"Payload": {"statusCode": 200 }}
In JSONata this is expressed as {% $states.result.Payload.statusCode %}. Then I can assign the JSONata expression to a statusCode variable via JSON. In the AWS console, I do this via:
Note that variables returning numbers from the response body like yearOfManufacture have an additional $string JSONata expression. I’ll explain the reason for this in the DynamoDB section.
Lambda Issues
When I first started using Step Functions variables, I used a different Lambda function for the API call and kept getting this error:
An error occurred.
The JSONata expression '$states.input.body.make' specified for the field 'Assign/make' returned nothing (undefined).
After getting myself confused, I checked the function’s return statement and found this:
That string isn’t compatible with dot notation. So while $states.input.body will match the whole body, $states.input.body.make can’t match anything because the string can’t be traversed. So nothing is returned, causing the error.
Using response.json() fixes this, as the response is now correctly structured for JSONata expressions:
The Choice state here is very similar to a previous one. This Choice state checks the Lambda function’s API response and routes accordingly.
Here, the Choice state uses the JSONata expression {% $statusCode = 200 %} to check the $statusCode variable value. By default, it will transition to the SNS Publish: Fail state. However, if $statusCode equals 200, then the Choice state will transition to the DynamoDB PutItem state instead:
This step prevents silent failures by ensuring unsuccessful API responses trigger an SNS notification instead of proceeding to DynamoDB. It also helps maintain data integrity by isolating success and failure paths, and ensuring only valid responses are saved in DynamoDB.
So now I’ve captured the data and confirmed its integrity. Next, let’s store it somewhere!
Amazon DynamoDB
It’s time to think about storing the API data. Enter DynamoDB! This section covers creating a table, writing data and integrating DynamoDB with AWS Step Functions and JSONata. I’ll share key lessons learned, especially about handling data types correctly.
Let’s start by creating a table.
Creating A Table
Before inserting data into DynamoDB, I need to create a table. Since DynamoDB is a schemaless database, all that is required to create a new table is a table name and a primary key. Naming the table is straightforward, so let’s focus on the key.
DynamoDB has two types of key:
Partition key(required): Part of the table’s primary key. It’s a hash value that is used to retrieve items from the table and allocate data across hosts for scalability and availability.
Sort key (optional): The second part of a table’s primary key. The sort key enables sorting or searching among all items sharing the same partition key.
Let’s look at an example using a Login table. In this table, the user ID serves as the partition key, while the login date acts as the sort key. This structure enables efficient lookups and sorting, allowing quick retrieval of a user’s login history while minimizing operational overhead.
To use a physical analogy, consider the DynamoDB table as a filing cabinet, the Partition key as a drawer, and the Sort key as a folder. If I wanted to retrieve User 123‘s logins for 2025, I would:
Access the Logins filing cabinet (DynamoDB table).
Find User 123’s drawer (Partition Key).
Get User 123’s 2025 folder (Sort Key).
DynamoDB provides many features beyond those discussed here. For the latest features, please refer to the Amazon DynamoDB Developer Guide.
Writing Data
So now I have a table, how do I put data in it?
DynamoDB offers several ways to write data, and a common one is PutItem. This lets me insert or replace an item in my table. Here’s a basic example of adding a login event to a UserLogins table:
TableName specifies the name of the DynamoDB table where the item will be stored.
Item represents the data being inserted into the table. It contains key-value pairs, where the attributes (e.g. UserID) are mapped to their corresponding data types (e.g. "S") and values (e.g. "123").
UserID is an attribute in the item being inserted.
"S" is a data type descriptor, ensuring that DynamoDB knows how to store and index it.
"123" is the value assigned to the UserID attribute.
While DynamoDB is NoSQL, it still enforces strict data types and naming rules to ensure consistency. These are detailed in the DynamoDB Developer Guide, but here’s a quick rundown of supported data types as of March 2025:
S – String
N – Number
B – Binary
BOOL – Boolean
NULL – Null
M – Map
L – List
SS – String Set
NS – Number Set
BS – Binary Set
Step Functions Config
So how do I apply this to Step Functions? Well, remember when I set variables in the output of the Lambda function? Step Functions lets me reference those variables here.
Here’s how I store a make attribute in DynamoDB, using my $make variable in a JSONata expression:
Finally, DynamoDB:PutAction gets the same error handling as Lambda:Invoke.
So I got all this working first time, right? Well…
DynamoDB Issues
During my first attempts, I got this error:
An error occurred while executing the state 'DynamoDB PutItem'.
The Parameters '{"TableName":"REDACTED","Item":{"make":{"S":"FORD"},"yearOfManufacture":{"N":2014}}}' could not be used to start the Task:
[The value for the field 'N' must be a STRING]
Ok. Not the first time I’ve seen data type problems. I’ll just change the yearOfManufacture data type to "S"(string) and try again…
An error occurred while executing the state 'DynamoDB PutItem'.
The Parameters '{"TableName":"REDACTED","Item":{"make":{"S":"FORD"},"yearOfManufacture":{"S":2014}}}' could not be used to start the Task:
[The value for the field 'S' must be a STRING]
DynamoDB rejected both approaches (╯°□°)╯︵ ┻━┻
The issue wasn’t the data type, but how it was formatted. DynamoDB treats numbers as strings in its JSON-like structure, so even when using numbers they must be wrapped in quotes.
In the case of yearOfManufacture, where I was providing 2014:
Plaintext
"yearOfManufacture": {"N": 2014}
DynamoDB needed "2014":
Plaintext
"yearOfManufacture": {"N": "2014"}
Thankfully, JSONata came to the rescue again! Remember the $string function from the Lambda section? Well, $string casts the given argument to a string!
This solved the problem with no Lambda function changes or additional states!
Amazon SNS
After successfully writing data to DynamoDB, I want to include a confirmation step by sending a notification through Amazon SNS.
While this approach is not recommended for high-volume use cases because of potential costs and notification fatigue, it can be helpful for testing, monitoring, and debugging. Additionally, it offers an opportunity to reuse variables from previous states and dynamically format a message using JSONata.
The goal is to send an email notification like this:
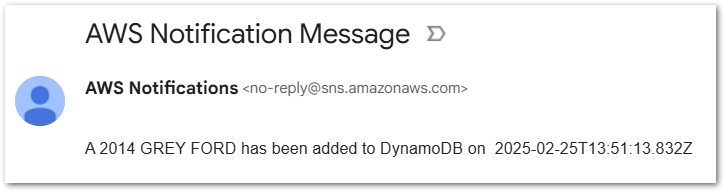
A 2014 GREY FORD has been added to DynamoDB on (current date and time)
To do this, I’ll use:
$yearOfManufacture for the vehicle’s year (2014)
$colour for the vehicle’s colour (GREY)
$make for the manufacturer (FORD)
Plus the JSONata $now() function for the current date and time. This generates a UTC timestamp in ISO 8601-compatible format and returns it as a string. E.g. "2025-02-25T19:12:59.152Z"
So the code will look something like:
A $yearOfManufacture$colour$make has been added to DynamoDB on $now()
Which translates to this JSONata expression:
Plaintext
{% 'A ' & $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}
Let’s analyse each part of the JSONata expression to understand how it builds the final message:
Plaintext
{% 'A '& $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}"
Each part of this expression plays a specific role:
‘A ‘ | ‘ has been added to DynamoDB on ‘: Static strings & spaces.
‘ ‘: Static spaces to separate JSONata variable outputs.
The static spaces are important! Without them, I’d get this:
2014GREYFORD
Instead of the expected:
2014 GREY FORD
This JSONata expression is passed as the Message argument in the SNS:Publish action, ensuring the notification contains the correctly formatted message:
JSON
"Message": "{% 'A ' & $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}"
Finally, to integrate this with Step Functions it is included in the SNS Publish: Success task ASL:
JSON
"SNS Publish: Success": {"Type": "Task","Resource": "arn:aws:states:::sns:publish","Arguments": {"Message": "{% 'A ' & $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}","TopicArn": "arn:aws:sns:REDACTED:success-stepfunction"}
Final Workflow
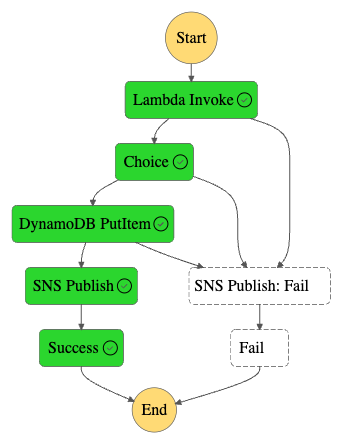
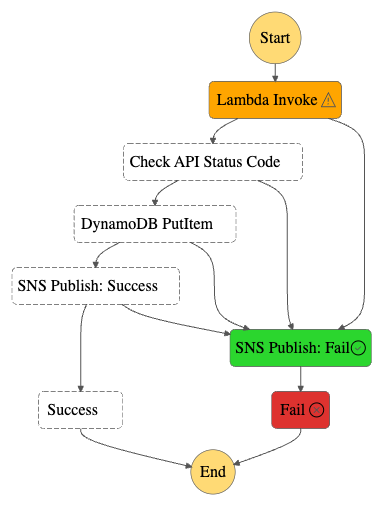
Finally, let’s see what the workflows look like. Here’s the workflow graph:
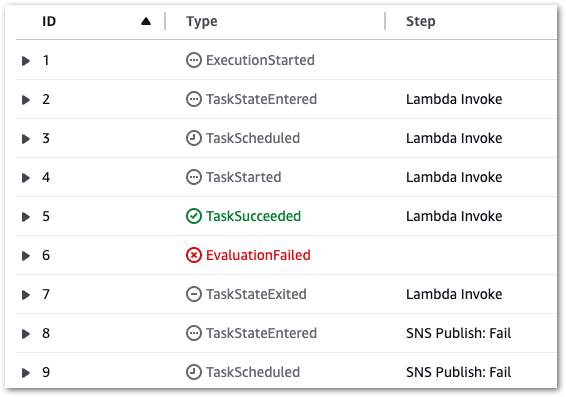
In this section, I run some test executions against my simplified Step Functions workflow and check the variables. I’ll test four requests – two valid and two invalid.
Valid Request: Ford
Firstly, what happens when a valid API request is made and everything works as expected?
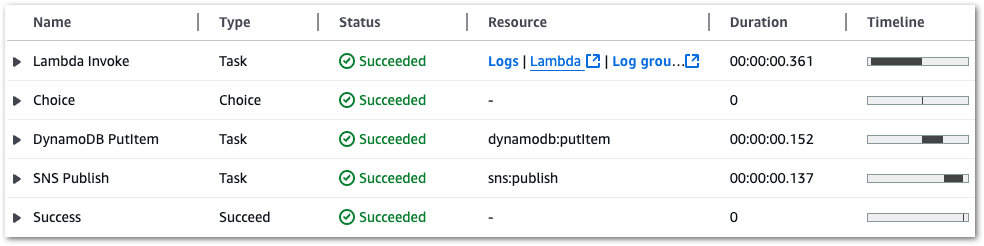
The Step Functions execution succeeds:
Each state completes successfully:
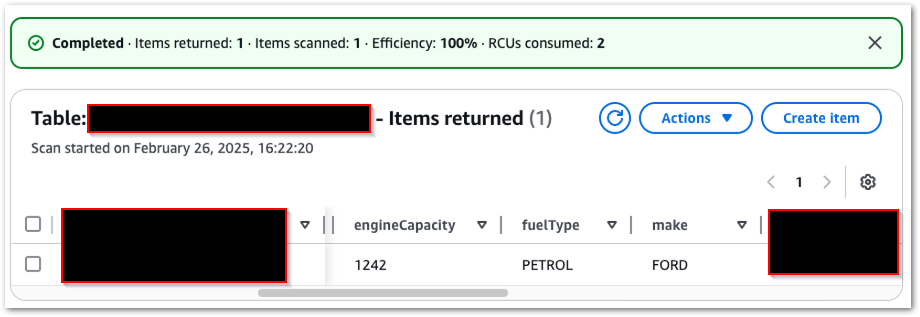
My DynamoDB table now contains one item:
I receive a confirmation email from SNS:
If I send the same request again, the existing DynamoDB item is overwritten because the primary key remains the same.
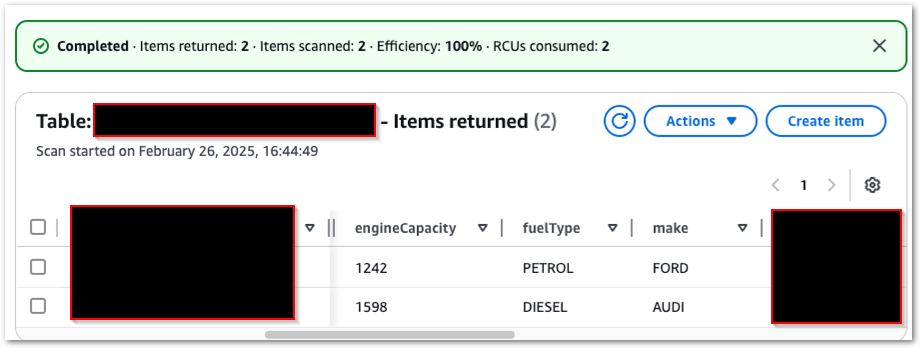
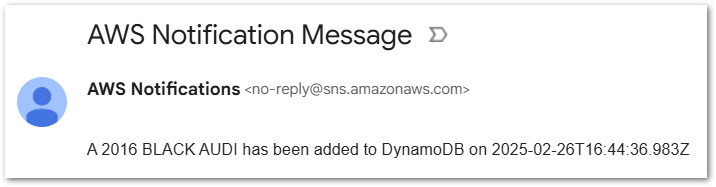
Valid Request: Audi
Next, what happens if I make a valid request for a different car? The steps repeat as above, and my DynamoDB table now has two items:
And I get a different email:
Invalid Request
Next, what happens if the car in my request doesn’t exist? Well, it does fail, but in an unexpected way:
The API returns an error response:
JSON
"Payload": {"statusCode": 500,"body": "{\"error\": \"API request failed: 400 Client Error: Bad Request for url"}" }
I’d expected the response to be passed to the Choice state, which would then notice the 500 status code and start the Fail process. But this happened instead:
The failure occurs at the assignment of the Lambda action variable! It attempts to assign a yearOfManufacture value from the API response body to a variable, but since there is no response body the assignment fails:
JSON
{"cause": "An error occurred while executing the state 'Lambda Invoke' (entered at the event id #2). The JSONata expression '$states.result.Payload.body.yearOfManufacture ' specified for the field 'Assign/yearOfManufacture ' returned nothing (undefined).","error": "States.QueryEvaluationError","location": "Assign/registrationNumber","state": "Lambda Invoke"}
I also get an email, but this one is less fancy as it just dumps the whole output:
So I still get my Fail outcome – just not in the expected way. Despite this, the Choice state remains valuable for preventing invalid data from entering DynamoDB.
No Request
Finally, what happens if no data is passed to the state machine at all?
Actually, this situation is very similar to the invalid request! There’s a different error message in the log:
JSON
"Payload": {"statusCode": 400,"body": "{\"error\": \"Registration number not provided\"}" }
But otherwise it’s the same events and outcome. The Lambda variable assignment fails, triggering an SNS email and an ExecutionFailed result.
Cost Analysis
This section examines the costs of my simplified Step Functions variables workflow. This section is brief since all services used in this workflow fall within the AWS Free Tier! For transparency, I’ll include my billing metrics for the month. These are account-wide, and I’m still nowhere near paying AWS anything!
DynamoDB:
$0.1415 per million read request units (EU (Ireland))
30.5 ReadRequestUnits
$0.705 per million write request units (EU (Ireland))
First 1,000 Amazon SNS Email/Email-JSON Notifications per month are free
19 Notifications
First 1,000,000 Amazon SNS API Requests per month are free
289 Requests
Step Functions:
$0 for first 4,000 state transitions
431 StateTransitions
This experiment demonstrates how cost-effective Step Functions can be. As long as my usage remains within the Free Tier, I pay nothing! If my workflow grows, I’ll monitor costs and optimise accordingly.
Summary
In this post, I used AWS Step Functions variables and JSONata to create a simplified API data capture workflow with Lambda and DynamoDB.
With a background in SQL and Python, I’m no stranger to variables, and I love that they’re now a native part of Step Functions. AWS keeps enhancing Step Functions every few months, making it more powerful and versatile. The introduction of variables unlocks new possibilities for data manipulation, serverless applications and event-driven workflows, and I’m excited to explore them further in the coming months!
In 2024, I worked a lot with AWS Step Functions. I built several for different tasks, wrote multiple blog posts about them and talked about them a fair bit. So when AWS introduced JSONata support for Step Functions last year, I was very interested. Although I had no prior JSONata experience, I heard positive feedback and made a mental note to explore its use cases.
Well, there’s no time like the present! And as I was starting to create the first Project Wolfie resources I realised some of my requirements were a perfect fit.
Firstly, I will examine what JSONata is, how it works and why it’s useful. Next, I will outline my architecture and create some low-code S3 key validation JSONata expressions. Finally, I’ll test these expressions and review their outputs.
JSONata & AWS
This section introduces JSONata and examines its syntax and benefits.
Introducing JSONata
JSONata is a lightweight query and transformation language for JSON, developed by Andrew Coleman in 2016. Specifically inspired by XPath and SQL, it enables sophisticated queries using a compact and intuitive notation.
JSONata provides built-in operators and functions for efficiently extracting and transforming data into any JSON structure. It also supports user-defined functions, allowing for advanced expressions that enhance the querying of dynamic JSON data.
For a visual introduction, check out this JSONata overview:
JSONata Syntax Essentials
JSONata has a simple and expressive syntax. Its path-based approach lets developers easily navigate nested structures. It combines functional programming with dot notation for navigation, brackets for filtering and pipeline operators for chaining.
JSONata was introduced to AWS Step Functions in November 2024. Using JSONata in Step Functions requires setting the QueryLanguage field to JSONata in the state machine definition. This action replaces the traditional JSONPath fields with two JSONata fields:
Arguments: Used to customise data sent to state actions.
Output: Used to transform results into custom state output.
Additionally, the Assign field sets variables that can be stored and reused across the workflow.
In AWS Step Functions, JSONata expressions are enclosed in {% %} delimiters but otherwise follow standard JSONata syntax. They access data using the $states reserved variable with the following structures:
State input is accessed using $states.input
Context information is accessed using $states.context
Task results (if successful) are accessed using $states.result
Error outputs (if existing) are accessed using $states.errorOutput
Step Functions includes standard JSONata functions as well as AWS-specific additions like $partition, $range, $hash, $random, and $uuid. Some functions, such as $eval, are not supported.
Talking more about this subject is AWS Principle Developer Advocate Eric Johnson:
JSONata Benefits
So why is JSONata in AWS a big deal?
Low Maintenance: JSONata use removes the need for Lambda runtime updates, dependency management and security patching. JSONata expressions are self-contained and version-free, reducing debugging and testing effort.
Simpler Development Workflow: JSONata’s standardised syntaxremoves decisions about languages, runtimes and tooling. This improves consistency, simplifies collaboration and speeds up development.
Releases Capacity: JSONata use reduces reliance on AWS Lambda, freeing up Lambda concurrency slots for more complex tasks. This minimises throttling risks and can lower Lambda costs.
Faster Execution: JSONata runs inside AWS services, avoiding cold starts, IAM role checks and network latency. Most JSONata transformations are complete in milliseconds, making it ideal for high-throughput APIs and real-time systems.
Architecture
This section explains the key features and events used in my low-code S3 validation architecture with JSONata.
Object Created Event
My process starts when an S3 object is created. For this post, I’m using Amazon EventBridge‘s sample S3 Object Created event:
Here, the highlighted key field is vital as it identifies the uploaded object. This field will be used in the validation processes.
Choice State
In AWS Step Functions, Choice states introduce conditional logic to a state machine. They assess conditions and guide execution accordingly, allowing workflows to branch dynamically based on input data. When used with JSONata, a Choice state must contain the following fields:
Condition field – a JSONata expression that evaluates to true/false.
Next field – a value that must match a state name in the state machine.
For example, this Choice state checks if a variable foo equals 1:
Amazon EventBridge matches the event record to an event rule.
Eventbridge executes the AWS Step Functions state machine and passes the event to it as JSON input.
The state machine transitions through the various choice states.
The state machine transitions to the fail state if any choice state criteria are not met.
The state machine transitions to the success state if all choice state criteria are met.
Expression Creation
In this section, I create JSONata expressions to perform low-code S3 validation. For clarity, I’ll use this sample S3 event including an object key which closely resembles my actual S3 path:
Now, retrieve the array’s last element (the object name) using [-1]:
Plaintext
$split(...)[-1]
➡ Output:"iTunes-AllTunes-2025-02-01.txt"
3. Splitting By . To Extract The File Suffix
Break the filename with $split again, using . as the delimiter:
Plaintext
$split($split(...)[-1], '.')
➡ Output:["iTunes-AllTunes-2025-02-01", "txt"]
Now, retrieve the last element (the suffix) using [-1]:
Plaintext
$split($split(...)[-1], '.')[-1]
➡ Output:"txt"
4. Converting To Lowercase For Case-Insensitive Matching
Use $lowercase to convert the suffix to lowercase:
Plaintext
$lowercase($split(...)[-1], '.')[-1])
➡ Output:"txt"
The $lowercase function ensures consistency, as files with TXT, Txt, or tXt extensions will still match correctly. Here, there is no change as txt is already lowercase.
5. Comparing Against 'txt'
Finally, compare the result to 'txt':
Plaintext
$lowercase($split(...)[-1], '.')[-1]) = 'txt'
➡ Output:true ✅
This means that files ending in .txt pass validation, while others fail.
S3 Key iTunes String Check
This JSONata expression checks if the S3 object key contains iTunes.
The $match function applies the substring to the provided regular expression (regex). If found, an array of objects is returned containing the following fields:
match – the substring that was matched by the regex.
index – the offset (starting at zero) within the substring.
groups – if the regex contains capturing groups (parentheses), this contains an array of strings representing each captured group.
In this JSONata expression:
Plaintext
$match(..., /\d{4}-\d{2}-\d{2}/)
The regex looks for:
\d{4} → Four digits (year)
- → Hyphen separator
\d{2} → Two digits (month)
- → Another hyphen
\d{2} → Two digits (day)
➡ Output:
JSON
{"match": "2025-02-01","index": 16,"groups": []}
3. Convert To Boolean With $exists
I can’t use the $match output yet as the Choice state needs a boolean output. Enter $exists. This function returns true for a successful match; otherwise, it returns false.
Plaintext
$exists($match(..., /\d{4}-\d{2}-\d{2}/))
➡ Output:true ✅ if a date is found.
Here, $exists returns true as a date is present. However, note that JSONata lacks built-in functions to validate dates. For example:
"2025-02-01" → true (valid date)
"2025-02-31" → true (invalid date but still matches format)
An AWS Lambda function would be needed for strict date validation.
Combining JSONata Expressions
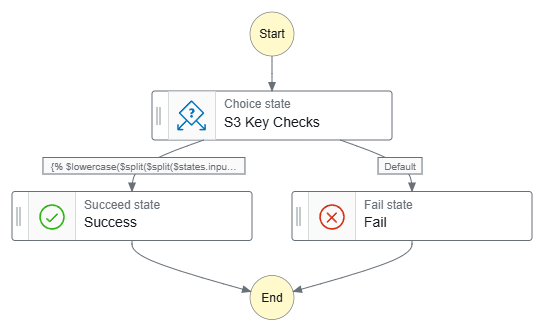
Although I’ve created separate Choice states for each JSONata expression in this section, I will add that all the expressions can be combined into a single Choice state using and:
Plaintext
{% $lowercase($split($split($states.input.detail.object.key, '/')[-1], '.')[-1]) = 'txt' and $contains($split($states.input.detail.object.key, '/')[-1], 'iTunes') and $exists($match($split($states.input.detail.object.key, '/')[-1], /\\d{4}-\\d{2}-\\d{2}/)) %}
When deciding whether to do this, consider these benefits:
Simplified Structure: Reducing the number of states can make the state machine easier to understand and maintain visually. Instead of multiple branching paths, all logic is in one centralised Choice state.
Cost Optimisation: AWS Step Functions Standard Workflows pricing is based on the number of state transitions. Combining multiple Choice states into one reduces transitions, potentially lowering costs for high-volume workflows.
Minimises Transition Latency: Each state transition adds a slight delay. By managing all logic within a single Choice state, the workflow runs more efficiently due to the reduced transitions.
Against these tradeoffs:
Added Complexity: A complex Choice state with many conditions can be difficult to read, debug, and modify. It may require deeply nested logic, which makes future updates challenging.
Limited Observability: If multiple conditions are combined into one state, debugging failures becomes more difficult as it is unclear which condition caused an unexpected transition.
Potential ScalingDifficulty: As the workflow evolves, adding more conditions to a single Choice state can become unmanageable. Ultimately, this situation may require breaking it up.
Final Workflows
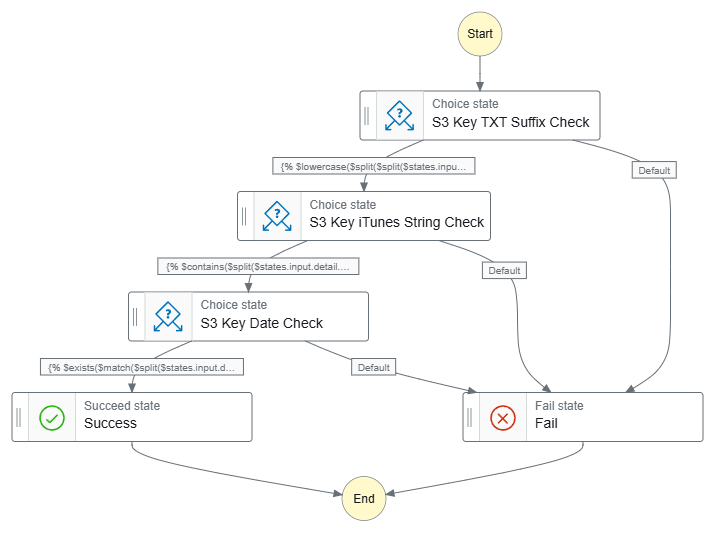
Finally, let’s see what the workflows look like. Firstly, this workflow has separate Choice states for each JSONata expression:
To ensure my low-code JSONata expressions work as expected, I ran several tests against different S3 object keys. These tests validate:
File Suffix (.txt)
Key Content (iTunes)
Date Format (YYYY-MM-DD)
Suffix Validation Tests
Test Case
S3 Key
Expected
Actual
✅ Valid Suffix (.txt)
"iTunes/iTunes-2025-02-01.txt"
Proceed to iTunes Check
✅ Success → Next: iTunes String Check
❌ Invalid Suffix (.csv)
"iTunes/iTunes-2025-02-01.csv"
Fail (No further checks)
❌ Failure → No further checks
❌ Missing Suffix
"iTunes/iTunes-2025-02-01"
Fail (No further checks)
❌ Failure → No further checks
Key Content Validation Tests
Test Case
S3 Key
Expected
Actual
✅ Valid “iTunes” Key
"iTunes/iTunes-2025-02-01.txt"
Proceed to Date Check
✅ Success → Next: Date Check
❌ Incorrect Case (itunes instead of iTunes)
"iTunes/itunes-2025-02-01.txt"
Fail (No further checks)
❌ Failure → No further checks
❌ Missing Key String
""
Fail (No further checks)
❌ Failure → No further checks
Date Format Validation Tests
Test Case
S3 Key
Expected
Actual
✅ Correct Date Format (YYYY-MM-DD)
"iTunes/iTunes-2025-02-01.txt"
Success (Validation complete)
✅ Success → Validation complete!
❌ Incorrect Date Format (Missing Day)
"iTunes/iTunes-2025-02.txt"
Fail (No further checks)
❌ Failure → No further checks
❌ Missing Date
"iTunes/iTunes.txt"
Fail (No further checks)
❌ Failure → No further checks
Edge Case: Impossible Date
Test Case
S3 Key
Expected
Actual
⚠️ Impossible Date (2025-02-31)
"iTunes/iTunes-2025-02-31.txt"
Fail (Ideally)
❌ Unexpected Success (JSONata does not validate real-world dates)
These tests confirm that JSONata expressions can effectively validate S3 object keys based on file suffixes, key contents and date formats. However, while JSONata can check formatting (YYYY-MM-DD) it does not validate real-world dates. If strict date validation is needed then an AWS Lambda function would be required.
Summary
In this post, I used JSONata to add low-code S3 object key validation to an AWS Step Functions state machine. This approach simplifies the validation process and reduces the reliance on more complex Lambda functions.
My first impressions of JSONata are very good! It’s already reduced both the number and size of Project Wolfie’s Lambda functions, and there’s still lots of JSONata to explore. In the meantime, these further videos by Eric Johnson explore more advanced JSONata Step Function applications:
If this post has been useful then the button below has links for contact, socials, projects and sessions: