
In this post, I respond to November 2022’s T-SQL Tuesday #156 Invitation and give my thoughts on some production code qualities.
Table of Contents
Introduction
This month, Tomáš Zíka’s T-SQL Tuesday invitation was as follows:
Which quality makes code production grade?
Please be as specific as possible with your examples and include your reasoning.
Good question!
In each section, I’ll use a different language. Firstly I’ll create a script, and then show a problem the script could encounter in production. Finally, I’ll show how a different approach can prevent that problem from occurring.
I’m limiting myself to three production code qualities to keep the post at a reasonable length, and so I can show some good examples.
Precision
In this section, I use T-SQL to show how precise code in production can save a data pipeline from unintended failure.
Setting The Scene
Consider the following SQL table:
USE [amazonwebshark]
GO
CREATE TABLE [2022].[sharkspecies](
[shark_id] [int] IDENTITY(1,1) NOT NULL,
[name_english] [varchar](100) NOT NULL,
[name_scientific] [varchar](100) NOT NULL,
[length_max_cm] [int] NULL,
[url_source] [varchar](1000) NULL
)
GO
This table contains a list of sharks, courtesy of the Shark Foundation.
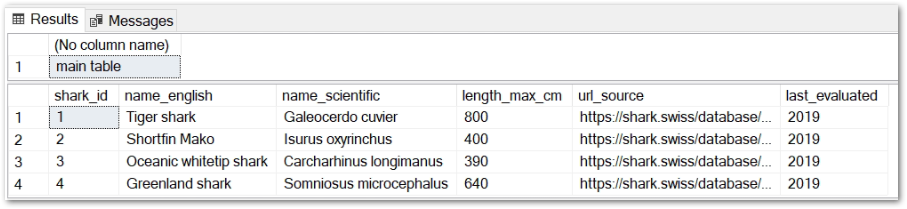
Now, let’s say that I have a data pipeline that uses data in amazonwebshark.2022.sharkspecies for transformations further down the pipeline.
No problem – I create a #tempsharks temp table and insert everything from amazonwebshark.2022.sharkspecies using SELECT *:
When this script runs in production, I get two tables with the same data:

What’s The Problem?
One day a new last_evaluated column is needed in the amazonwebshark.2022.sharkspecies table. I add the new column and backfill it with 2019:
ALTER TABLE [2022].sharkspecies
ADD last_evaluated INT DEFAULT 2019 WITH VALUES
GO
However, my script now fails when trying to insert data into #tempsharks:
(1 row affected)
(4 rows affected)
Msg 213, Level 16, State 1, Line 17
Column name or number of supplied values does not match table definition.
Completion time: 2022-11-02T18:00:43.5997476+00:00
#tempsharks has five columns but amazonwebshark.2022.sharkspecies now has six. My script is now trying to insert all six sharkspecies columns into the temp table, causing the msg 213 error.
Doing Things Differently
The solution here is to replace row 21’s SELECT * with the precise columns to insert from amazonwebshark.2022.sharkspecies:
While amazonwebshark.2022.sharkspecies now has six columns, my script is only inserting five of them into the temp table:
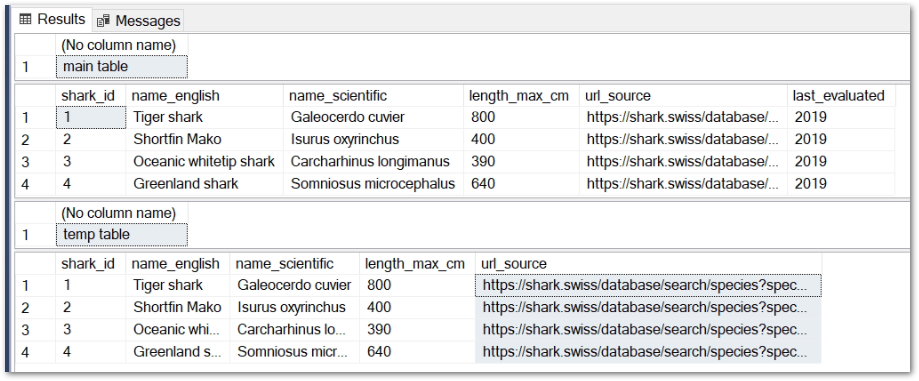
I can add the last_evaluated column into #tempsharks in future, but its absence in the temp table isn’t causing any immediate problems.
Works The Same In Other Environments
In this section, I use Python to show the value of production code that works the same in non-production.
Setting The Scene
Here I have a Python script that reads data from an Amazon S3 bucket using a boto3 session. I pass my AWS_ACCESSKEY and AWS_SECRET credentials in from a secrets manager, and create an s3bucket variable for the S3 bucket path:
When I deploy this script to my dev environment it works fine.
What’s The Problem?
When I deploy this script to production, s3bucket will still be s3://dev-bucket. The potential impact of this depends on the AWS environment setup:
Different AWS account for each environment:
dev-bucketdoesn’t exist in Production. The script fails.
Same AWS account for all environments:
- Production IAM roles might not have any permissions for
dev-bucket. The script fails. - Production processes might start using a dev resource. The script succeeds but now data has unintentionally crossed environment boundaries.
Doing Things Differently
A solution here is to dynamically set the s3bucket variable based on the ID of the AWS account the script is running in.
I can get the AccountID using AWS STS. I’m already using boto3, so can use it to initiate an STS client with my AWS credentials.
STS then has a GetCallerIdentity action that returns the AWS AccountID linked to the AWS credentials. I capture this AccountID in an account_id variable, then use that to set s3bucket‘s value:
More details about get_caller_identity can be found in the AWS Boto3 documentation.
For bonus points, I can terminate the script if the AWS AccountID isn’t defined. This prevents undesirable states if the script is run in an unexpected account.
Speaking of which…
Prevents Undesirable States
In this section, I use PowerShell to demonstrate how to stop production code from doing unintended things.
Setting The Scene
In June I started writing a PowerShell script to upload lossless music files from my laptop to one of my S3 buckets.
I worked on it in stages. This made it easier to script and test the features I wanted. By the end of Version 1, I had a script that dot-sourced its variables and wrote everything in my local folder $ExternalLocalSource to my S3 bucket $ExternalS3BucketName:
#Load Variables Via Dot Sourcing
. .\EDMTracksLosslessS3Upload-Variables.ps1
#Upload File To S3
Write-S3Object -BucketName $ExternalS3BucketName -Folder $ExternalLocalSource -KeyPrefix $ExternalS3KeyPrefix -StorageClass $ExternalS3StorageClass
What’s The Problem?
NOTE: There were several problems with Version 1, all of which were fixed in Version 2. In the interests of simplicity, I’ll focus on a single one here.
In this script, Write-S3Object will upload everything in the local folder $ExternalLocalSource to the S3 bucket $ExternalS3BucketName.
Problem is, the $ExternalS3BucketName S3 bucket isn’t for everything! It should only contain lossless music files!
At best, Write-S3Object will upload everything in the local folder to S3 whether it’s music or not.
At worst, if the script is pointing at a different folder it will start uploading everything there instead! PowerShell commonly defaults to C:\Windows, so this could cause all kinds of problems.
Doing Things Differently
I decided to limit the extensions that the PowerShell script could upload.
Firstly, the script captures the extensions for each file in the local folder $ExternalLocalSource using Get-ChildItem and [System.IO.Path]::GetExtension:
$LocalSourceObjectFileExtensions = Get-ChildItem -Path $ExternalLocalSource | ForEach-Object -Process { [System.IO.Path]::GetExtension($_) }
Then it checks each extension using a ForEach loop. If an extension isn’t in the list, PowerShell reports this and terminates the script:
ForEach ($LocalSourceObjectFileExtension In $LocalSourceObjectFileExtensions)
{
If ($LocalSourceObjectFileExtension -NotIn ".flac", ".wav", ".aif", ".aiff")
{
Write-Output "Unacceptable $LocalSourceObjectFileExtension file found. Exiting."
Start-Sleep -Seconds 10
Exit
}
So now, if I attempt to upload an unacceptable .log file, PowerShell raises an exception and terminates the script:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Unacceptable .log file found. Exiting.
**********************While an acceptable .flac file will produce this message:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Acceptable .flac file.
**********************To see the code in full, as well as the other problems I solved, please check out my post from June.
Summary
In this post, I responded to November 2022’s T-SQL Tuesday #156 Invitation and gave my thoughts on some production code qualities. I gave examples of each quality and showed how they could save time and prevent unintended problems in a production environment.
Thanks to Tomáš for this month’s topic! My previous T-SQL Tuesday posts are here.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~











