Amazon Web Services (AWS) is the world’s most comprehensive and broadly adopted cloud platform, offering over 200 fully-featured services from data centres globally.
It’s time to do something with that data! I want to analyse my iTunes data and look for trends and insights into my listening habits. I also want to access these insights in the cloud, as my laptop is a bit bulky and quite slow. Finally, I’d prefer to keep my costs to a minimum.
Here, I’ll show how AWS and Python can be used together to meet these requirements. Let’s start with AWS.
Amazon S3
In this section, I will update my S3 setup. I’ll create some new buckets and explain my approach.
New S3 Buckets
Currently, I have a single S3 bucket containing my iTunes Export CSV. Moving forward, this bucket will contain all of my unmodified source objects, otherwise known as raw data.
To partner the raw objects bucket, I now have an ingested objects bucket. This bucket will contain objects where the data has been transformed in some way. My analytics tools and Athena tables will point here for their data.
Speaking of Athena, the other new bucket will be used for Athena’s query results. Although Athena is serverless, it still needs a place to record queries and store results. Creating this bucket now will save time later on.
Having separate buckets for each of these functions isn’t a requirement, although it is something I prefer to do. Before moving on, I’d like to run through some of the benefits I find with this approach.
Advantages Of Multiple Buckets
Firstly, having buckets with clearly defined purposes makes navigation way easier. I always know where to find objects, and rarely lose track of or misplace them.
Secondly, having multiple buckets usually makes my S3 paths shorter. This doesn’t sound like much of a benefit upfront, but the S3 path textboxes in the AWS console are quite small, and using long S3 paths in the command line can be a pain.
Finally, I find security and access controls are far simpler to implement with a multi-bucket setup. Personally I prefer “You can’t come into this house/bucket” over “You can come into this house/bucket, but you can’t go into this room/prefix”. However, both S3 buckets and S3 prefixes can be used as IAM policy resources so there’s technically no difference.
That concludes the S3 section. Next, let’s set up Athena.
Amazon Athena
In this section, I’ll get Athena ready for use. I’ll show the process I followed and explain my key decisions. Let’s start with my reasons for choosing Athena.
Why Athena?
Plenty has been written about Athena’s benefits over the years. So instead of retreading old ground, I’ll discuss what makes Athena a good choice for this particular use case.
Firstly, Athena is cheap. The serverless nature of Athena means I only pay for what I query, scan and store, and I’ve yet to see a charge for Athena in the three years I’ve been an AWS customer.
Secondly, like S3, Athena’s security is managed by IAM. I can use IAM policies to control who and what can access my Athena data, and can monitor that access in CloudTrail. This also means I can manage access to Athena independently of S3.
Finally, Athena is highly available. Authorised calls to the service have a 99.9% Monthly Uptime Percentage SLA and Athena benefits from S3’s availability and durability. This allows 24/7 access to Athena data for users and applications.
Setting Up Athena
To start this section, I recommend reading the AWS Athena Getting Started documentation for a great Athena introduction. I’ll cover some basics here, but I can’t improve on the AWS documentation.
Athena needs three things to get off the ground:
An S3 path for Athena query results.
A database for Athena tables.
A table for interacting with S3 data objects.
I’ve already talked about the S3 path, so let’s move on to the database. A database in Athena is a logical grouping for the tables created in it. Here, I create a blog_amazonwebshark database using the following script:
CREATE DATABASE blog_amazonwebshark
Next, I enter the column names from my iTunes Export CSV into Athena’s Create Table form, along with appropriate data types for each column. In response, the form creates this Athena table:
Please note that I have removed the S3 path from the LOCATION property to protect my data. The actual Athena table is pointing at an S3 prefix in my ingested objects bucket that will receive my transformed iTunes data.
Speaking of data, the form offers several choices of source data format including CSV, JSON and Parquet. I chose Parquet, but why do this when I’m already getting a CSV? Why create extra work?
Let me explain.
About Parquet
Apache Parquet is a file format that supports fast processing for complex data. It can essentially be seen as the next generation of CSV. Both formats have their place, but at scale CSV files have large file sizes and slow performance.
In contrast, Parquet files have built-in compression and indexing for rapid data location and retrieval. In addition, the data in Parquet files is organized by column, resulting in smaller sizes and faster queries.
This also results in Athena cost savings as Athena only needs to read the columns relevant to the queries being run. If the same data was in a CSV, Athena would have to read the entire CSV whether the data is needed or not.
That’s everything for Athena. Now I need to update my Python scripts.
Python
In this section, I’ll make changes to my Basic iTunes ETL to include my new S3 and Athena resources and to replace the CSV output with a Parquet file. Let’s start with some variables.
New Python Variables
My first update is a change to ETL_ITU_Play_Variables.py, which contains my global variables. Originally there were two S3 global variables – S3_BUCKET containing the bucket name and S3_PREFIX containing the S3 prefix path leading to the raw data:
S3_BUCKET
S3_PREFIX
Now I have two buckets and two prefixes, so it makes sense to update the variable names. I now have two additional global variables, adding _RAW to the originals and _INGESTED to the new ones for clarity:
The next change is to ETL_ITU_Play.py. The initial version converts a Pandas DataFrame to CSV using pandas.DataFrame.to_csv. I’m now replacing this with awswrangler.s3.to_parquet, which needs three parameters:
Before committing my changes, I took the time to put the main workings of my ETL in a class. This provides a clean structure for my Python script and will make it easier to reuse in future projects.
That completes the changes. Let’s review what has been created.
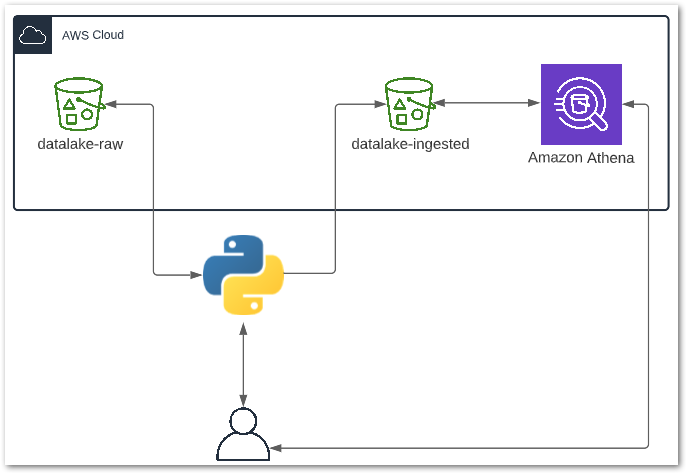
Architecture
Here is an architectural diagram of how everything fits together:
Here is a breakdown of the processes involved:
User runs the Python ETL script locally.
Python reads the CSV object in datalake-raw S3 bucket.
Python extracts data from CSV into a DataFrame and transforms several columns.
Python writes the DataFrame to datalake-ingested S3 bucket as a Parquet file.
Python notifies User of a successful run.
User sends query to Athena.
Athena reads data from datalake-ingested S3 bucket.
Athena returns query results to User.
Testing
In this section, I will test my resources to make sure they work as expected. Bare in mind that this setup hasn’t been designed with production use in mind, so my testing is somewhat limited and would be insufficient for production deployment.
Testing Python
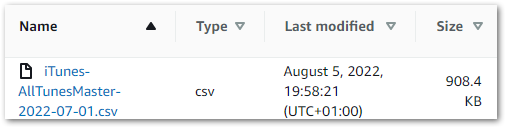
TEST: Upload a CSV to the datalake-raw S3 bucket, then run the Python script. The Python script must run successfully and print updates in the terminal throughout.
RESULT: I upload an iTunes Export CSV to the datalake-raw S3 bucket:
The Python script runs, printing the following output in the terminal:
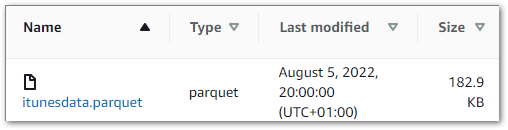
TEST: After the Python script successfully runs, the datalake-ingested S3 bucket must contain an itunesdata.parquet object.
RESULT: Upon accessing the datalake-ingested S3 bucket, an itunesdata.parquet object is found:
(On an unrelated note, look at the size difference between the Parquet and CSV files!)
Testing Athena
TEST: When the datalake-ingested S3 bucket contains an itunesdata.parquet object, data from the iTunes Export CSV must be shown when the following Athena query is run:
SELECT * FROM basic_itunes_python_etl;
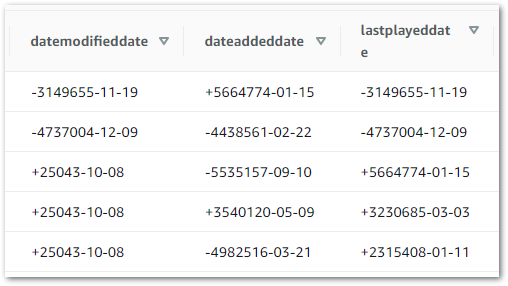
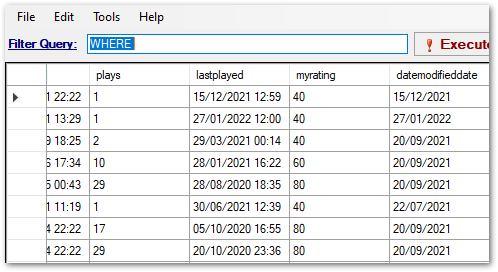
RESULT: Most of the Athena results match the iTunes Export data. However, the transformed dates did not match expectations:
This appears to be a formatting problem, as some parts of a date format are still visible.
To diagnose the problem I wanted to see how these columns were being stored in the Parquet file. I used mukunku’sParquetViewer for this, which is described in the GitHub repo as:
…a quick and dirty utility that I created to easily view Apache Parquet files on Windows desktop machines.
It works very well!
Here is a screenshot of the data. The lastplayed column has dates and times, while the datamodifieddate column has dates only:
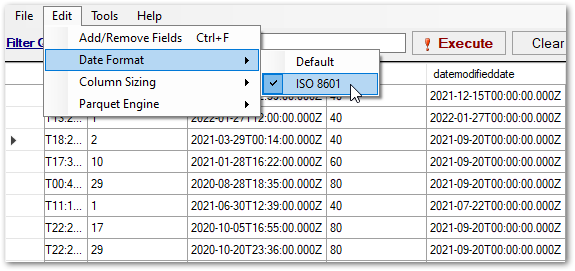
The cause of the problem becomes apparent when the date columns are viewed using the ISO 8601 format:
The date columns are all using timestamps, even when no times are included!
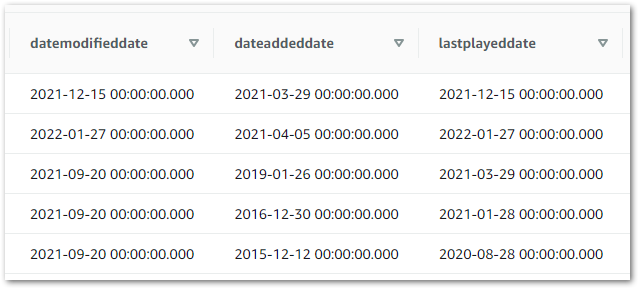
A potential fix would be to change the section of my Python ETL script that handles data types. Instead, I update the data types used in my Athena table from date:
This time, when I view my Athena table the values all appear as expected:
Scripts
My ETL_ITU_Play.py file commit from 2022-08-08 can be viewed here:
ETL_ITU_Play.py on GitHub
My updated repo readme can be viewed here:
README.md on GitHub
Summary
In this post, I updated my existing iTunes Python ETL to return a Parquet file, which I then uploaded S3 and viewed using Athena. I explained my reasoning for choosing S3, Athena and the Parquet file format, and I handled a data formatting issue.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
In this post I will use Python and AWS Data Wrangler to create a basic iTunes ETL that extracts data from an iTunes export file into a Pandas DataFrame.
For many years I have enjoyed various forms of dance music. Starting with my first compilation CDs in 2000, I’ve since amassed a large collection of records, CDs and virtual media ranging from the late 80s to modern times.
I started using iTunes as my main media player in 2010. Since then I have built up a large database of iTunes metadata that includes various counts, ratings and timestamps.
Currently I use this data for a series of iTunes Smart Playlists. To derive further meaning from the data and to practise my Python skills, I want to extract this data from iTunes and analyse it using the various data tools at my disposal.
To get the ball rolling I’m going to build a basic iTunes ETL, which I will continue to develop over the coming months.
Let’s start by looking at the iTunes export process.
iTunes Export Files
I use iTunes 12.6.4.3. This isn’t by choice – iTunes 12.6.4.3 is the last version with a built-in App Store, allowing my battered old iPhone 3GS to live on in its second life as an iPod Touch:
Still works!
I mention this as newer versions of iTunes may be different, or may not offer an export feature at all. Why do I persist with this ageing setup? That…is a post for another time.
Every week I sync my Not-iPhone via iTunes, and then create an export of my master playlist:
iTunes doesn’t have many export options, and exports playlists as tab-delimited txt files by default:
To give myself an easier time for this post, I manually made the following changes to a recent iTunes export file:
Imported the txt file into Microsoft Excel.
Removed columns I didn’t want.
Saved the altered file as a csv.
Uploaded the csv to Amazon S3.
This Franken-File will be what I use to build my basic iTunes ETL. I understand there are ways of dealing with txt files in Python – I’ll be exploring this in future posts.
Setup
Before starting to write any code, I have done the following:
During this post, I will make several decisions that will be revisited in the coming months as my skills improve. I have taken steps to protect my AWS credentials (more on that shortly) but at this stage my basic iTunes ETL Python script is a work in progress and should not be used in a Production environment.
Creating Secure Variables
My first job is to create the variables I’m going to need. As these variables can compromise my AWS account in the wrong hands, I want to create them as securely as possible.
Python’s import statement can import other Python scripts in the same way as modules. With this in mind, I create a new ETL_ITU_Play_Variables.py file for my variables.
Importing ETL_ITU_Play_Variables into my main script will allow Python to locate the variables and call them successfully:
Next I create a gitignore file and add ETL_ITU_Play_Variables.py to it. I can now use these variables in my local environment, safe in the knowledge that Git will not track ETL_ITU_Play_Variables and will not include it in any commits.
With that taken care of, I need two sets of variables.
Creating Authentication Variables
AWS authenticates every request before completing it. As none of my AWS resources are public, I need to provide credentials that have the necessary IAM permissions.
There are various ways to provide these credentials – in this case I’m using an AWS Access Key / Secret Key combination with a variable for each string:
I then use these variables to create s3_path for AWS Data Wrangler to use:
s3_path = f"s3://{s3_bucket}/{s3_prefix}"
Making The ETL
With my variables in place, I can start working on my basic iTunes ETL! AWS is now accepting my requests, so let’s start configuring AWS Data Wrangler.
Creating The DataFrame
AWS Data Wrangler is essentially Pandas on AWS, and the two tools share many commands. This DataEng Uncomplicated AWS Data Wrangler Overview does a great job of explaining the fundamentals:
I read the iTunes Export csv‘s contents by using awswrangler.s3.read_csv with the following parameters:
path: My s3_path variable.
path_suffix: The files I want to read, in this case .csv.
boto3_session: My session variable.
This reads all the csv files in the S3 path, which is fine for now.
This tells Pandas how to interpret the dates. In the case of 05/04/2021, dayfirst=True tells Pandas this is 5th April 2021, as opposed to 4th May 2021.
Pandas then parses the rest of my dates in the same way, giving me the formatting I want:
I repeat this for the datemodified and lastplayed columns.
Creating Date Columns From DateTime Columns
I now want to create some new columns in my DataFrame.
The first of these new columns will mirror the values in the existing date columns. However, these columns will not contain the full timestamp – they will only contain the date instead. This will make it easier to aggregate my data.
To do this, I use pandas.Series.dt.date to create three new columns in the DataFrame:
I now want to add another column to the DataFrame to simplify reporting against a track’s rating. Ratings in iTunes export files appear in multiples of twenty:
1 star = 20
2 stars = 40
3 stars = 60
4 stars = 80
5 stars = 100
In my current DataFrame, printing myrating produces this:
print (f'Dataframe My Rating is {df.myrating}')
1 40.0
2 40.0
3 60.0
4 80.0
This produces a disconnect between the data in the DataFrame and the data in the iTunes GUI. I would prefer to keep things simple by having a column where the rating value mirrors the iTunes GUI.
This can be added to my DataFrame by using a function. I define an itunes_rating function that will return an integer based on the value that is passed to it:
def itunes_rating(r):
"""Converts ratings in export file to familiar format"""
if r == 20:
return 1
elif r == 40:
return 2
elif r == 60:
return 3
elif r == 80:
return 4
elif r == 100:
return 5
else:
return 0
I then create a new myratingdigit column in my DataFrame by passing each value in the myrating column to the itunes_rating function and capturing the result:
And when I print the new column, the results are as expected:
print (f'Dataframe My Rating Digit is {df.myratingdigit}')
1 2
2 2
3 3
4 4
Setting Data Types
Finally, I want to make sure the DataFrame is using the correct data types for each column. Pandas will usually infer data types correctly but doesn’t always get it right.
I can use pandas.DataFrame.dtypes to see the current data types in my DataFrame. At the moment they are:
name object
artist object
album object
genre object
tracknumber int64
year int64
datemodified datetime64[ns]
dateadded datetime64[ns]
plays float64
lastplayed datetime64[ns]
myrating float64
datemodifieddate object
dateaddeddate object
lastplayeddate object
myratingdigit int64
Most of these are correct but some need changing. For example, plays will never have decimal places so should be int, and columns like datemodifieddate should be datetime64.
Pandas has several options for this, which are laid out in this helpful Stack Overflow thread. Here, I use astype to assign data types to my dataframe:
Unfortunately, while testing the newly assigned dtypes I started getting an error:
Exception has occurred: IntCastingNaNError
Cannot convert non-finite values (NA or inf) to integer
This error means that at least one of the columns I’m trying to cast as int contains an empty value. An infinite value is possible, but unlikely due to the various integrity checks iTunes performs on its library.
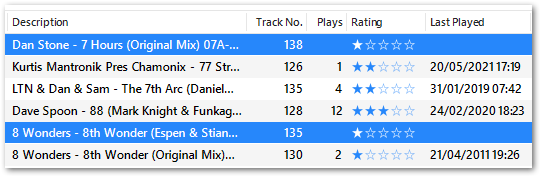
Included within the resulting DataFrame were the following tracks:
3571 7 Hours (Original Mix) Dan Stone 07A-Dm ... 2019-01-26 NaT 1
3575 8th Wonder (Espen & Stian Remix) 8 Wonders 04A-Fm ... 2019-01-26 NaT 1
Checking iTunes shows that these tracks have no plays:
iTunes represents no plays as an empty string as opposed to a zero. This is then extracted into the DataFrame as NA, causing the IntCastingNaN error.
To fix this, I use pandas.DataFrame.fillna to replace the empty fields with zero. Although only the plays column is generating the error, I apply fillna to all the columns being cast as int to prevent any future problems for the ETL:
The myratingint column doesn’t need this approach, since my itunes_rating function always returns zero if no conditions are met.
This time, printing the data types shows an acceptable list:
name object
artist object
album object
genre object
tracknumber int64
year int64
datemodified datetime64[ns]
dateadded datetime64[ns]
plays int64
lastplayed datetime64[ns]
myrating int64
datemodifieddate datetime64[ns]
dateaddeddate datetime64[ns]
lastplayeddate datetime64[ns]
myratingdigit int64
Exporting The DataFrame As A CSV
This is as far as I’m going to take the DataFrame in this post. As a final check, I want to extract the DataFrame in some form to confirm its suitability for future work I have planned.
The quickest way to do this is with pandas.DataFrame.to_csv. This writes the entire DataFrame to a csv file. When I run:
df.to_csv('ETL-ITU.csv')
A ETL-ITU.csv file is created in the terminal’s working directory that can be viewed and sandboxed as needed.
Scripts
My gitignore file commit from 2022-07-17 can be viewed here:
Basic_iTunes_Python_ETL .gitignore on GitHub
My ETL_ITU_Play.py file commit from 2022-07-17 can be viewed here:
ETL_ITU_Play.py on GitHub
A requirements.txt file has also been created to aid installation. The file commit from 2022-07-20 can be viewed here:
Basic_iTunes_Python_ETL requirements.txt on GitHub
Summary
In this post I used Python and AWS Data Wrangler to create a basic iTunes ETL that extracts data from an iTunes export file into a Pandas DataFrame. I have used various Python modules to extract and transform the data, and the data is now ready to be loaded to a staging area of my choosing.
Expect to see further posts on this in the coming months. This basic iTunes ETL probably won’t stay basic for long!
If this post has been useful, please feel free to follow me on the following platforms for future updates:
For several months I’ve been going through some music from an old hard drive. These music files are currently on my laptop, and exist mainly as lossless .flac files.
For each file I’m doing the following:
Creating an .mp3 copy of each lossless file.
Storing the .mp3 file on my laptop.
Uploading a copy of the lossless file to S3 Glacier.
Transferring the original lossless file from my laptop to my desktop PC.
I usually do the uploads using the S3 console, and have been meaning to automate the process for some time. So I decided to write some code to upload files to S3 for me, in this case using PowerShell.
Prerequisites
Before starting to write my PowerShell script, I have done the following on my laptop:
Version 0 gets the basic functionality in place. No bells and whistles here – I just want to upload a file to an S3 bucket prefix, stored using the Glacier Flexible Retrieval storage class.
V0: Writing To S3
I am using the PowerShell Write-S3Object cmdlet to upload my files to S3. This cmdlet needs a couple of parameters to do what’s required:
-BucketName: The S3 bucket receiving the files.
-Folder: The folder on my laptop containing the files.
-KeyPrefix: The S3 bucket key prefix to assign to the uploaded objects.
-StorageClass: The S3 storage class to assign to the uploaded objects.
I create a variable for each of these so that my script is easier to read as I continue its development. I couldn’t find the inputs that the -StorageClass parameter uses in the Write-S3Object documentation. In the end, I found them in the S3 PutObject API Reference.
I don’t have to log onto the S3 console for uploads anymore.
Forgetting to specify Glacier Flexible Retrieval as the S3 storage class is no longer a problem. The script does this for me.
Starting an upload to S3 is now as simple as right-clicking the script and selecting Run With PowerShell from the Windows Context Menu.
Version 0 works great, but I’ll give away one of my S3 bucket names if I start sharing a non-redacted version. This has been known to cause security issues in severe cases. Ideally, I’d like to separate the variables from the Powershell commands, so let’s work on that next.
Version 1: Security
Version 1 enhances the security of my script by separating my variables from my PowerShell commands. To make this work without breaking things, I’m using the following features:
To take advantage of these features, I’ve made two new files in my repo:
Variables.ps1 for my variables.
V1Security.ps1 for my Write-S3Object command.
So let’s now talk about how this all works.
V1: Isolating Variables With Dot Sourcing
At the moment, my script is broken. Running Variables.ps1 will create the variables but do nothing with them. Running V1Security.ps1 will fail as the variables aren’t in that script anymore.
This is where Dot Sourcing comes in. Using Dot Sourcing lets PowerShell look for code in other places. Here, when I run V1Security.ps1 I want PowerShell to look for variables in Variables.ps1.
To dot source a script, type a dot (.) and a space before the script path. As both of my files are in the same folder, PowerShell doesn’t even need the full path:
. .\EDMTracksLosslessS3Upload-Variables.ps1
Now my script works again! But I still have the same problem – if Variables.ps1 is committed to GitHub at any point then my variables are still visible. How can I stop that?
This time it’s Git to the rescue. I need a .gitignore file.
V1: Selective Tracking With .gitignore
.gitignore is a way of telling Git what not to include in commits. Entering a file, folder or pattern into a repo’s .gitignore file tells Git not to track it.
When Visual Studio Code finds a .gitignore file, it helps out by making visual changes in response to the file’s contents. When I create a .gitignore file and add the following lines to it:
#Set Variables
#The local file path for objects to upload to S3
#E.g. "C:\Users\Files\"
$LocalSource =
#The S3 bucket to upload the objects to
#E.g. "my-s3-bucket"
$S3BucketName =
#The S3 bucket prefix / folder to upload the objects to (if applicable)
#E.g. "Folder\SubFolder\"
$S3KeyPrefix =
#The S3 Storage Class to upload to
#E.g. "GLACIER"
$S3StorageClass =
Version 1 VariablesBlank.ps1 On GitHub
V1: Evaluation
Version 1 now gives me the benefits of Version 0 with the following additions:
My variables and commands have now been separated.
I can now call Variables.ps1 from other scripts in the same folder, knowing the variables will be the same each time for each script.
I can use .gitignore to make sure Variables.ps1 is never uploaded to my GitHub repo.
The next problem is one of visibility. I have no way to know if my uploads have been successful. Or if they were duplicated. Nor do I have any auditing.
The S3 console gives me a summary at the end of each upload:
It would be great to have something similar with my script! In addition, some error handling and quality control checks would increase my confidence levels.
Let’s get to work!
Version 2: Visibility
Version 2 enhances the visibility of my script. The length of the script grows a lot here, so let’s run through the changes and I’ll explain what’s going on.
As a starting point, I copied V1Security.ps1 and renamed it to V2Visibility.ps1.
V2: Variables.ps1 And .gitignore Changes
Additions are being made to these files as a result of the Version 2 changes. I’ll mention them as they come up, but it makes sense to cover a few things up-front:
I added External to all variable names in Variables.ps1 to keep track of them in the script. For example, $S3BucketName is now $ExternalS3BucketName.
There are some additional local file paths in Variables.ps1 that I’m using for transcripts and some post-upload checks.
The first change is perhaps the simplest. PowerShell has built-in cmdlets for creating transcripts:
Start-Transcript creates a record of all or part of a PowerShell session in a separate file.
Stop-Transcript stops a transcript that was started by the Start-Transcript cmdlet.
These go at the start and end of V2Visibility.ps1, along with a local file path for the EDMTracksLosslessS3Upload.log file I’m using to record everything.
This new path is stored in Variables.ps1. In addition, EDMTracksLosslessS3Upload.log has been added to .gitignore.
V2: Check If There Are Any Files
Now the error handing begins. I want the script to fail gracefully, and I start by checking that there are files in the correct folder. First I count the files using Get-ChildItem and Measure-Object:
And then stop the script running if no files are found:
If ($LocalSourceCount -lt 1)
{
Write-Output "No Local Files Found. Exiting."
Start-Sleep -Seconds 10
Stop-Transcript
Exit
}
There are a couple of cmdlets here that make several appearances in Version 2:
Start-Sleep suspends PowerShell activity for the time stated. This gives me time to read the output when I’m running the script using the context menu.
Exit causes PowerShell to completely stop everything it’s doing. In this case, there’s no point continuing as there’s nothing in the folder.
If files are found, PowerShell displays the count and carries on:
Else
{
Write-Output "$LocalSourceCount Local Files Found"
}
V2: Check If The Files Are Lossless
Next, I want to stop any file uploads that don’t belong in the S3 bucket. The bucket should only contain lossless music – anything else should be rejected.
So now, if I attempt to upload an unacceptable .log file, the transcript will say:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Unacceptable .log file found. Exiting.
**********************
Whereas an acceptable .flac file will produce:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Acceptable .flac file.
**********************
And when uploading multiple files:
**********************
Transcript started, output file is C:\Files\EDMTracksLosslessS3Upload.log
Checking extensions are valid for each local file.
Acceptable .flac file.
Acceptable .wav file.
Acceptable .flac file.
**********************
V2: Check If The Files Are Already In S3
The next step checks if the files are already in S3. This might not seem like a problem, as S3 usually overwrites an object if it already exists.
Thing is, this bucket is replicated. This means it’s also versioned. As a result, S3 will keep both copies in this scenario. In the world of Glacier this doesn’t cost much, but it will distort the bucket’s S3 Inventory. This could lead to confusion when I check them with Athena. And if I can stop this situation with some automation then I might as well.
I’m going to use the Get-S3Object cmdlet to query my bucket for each file. For this to work, I need two things:
-BucketName: This is in Variables.ps1.
-Key
-Key is the object’s S3 file path. For example, Folder\SubFolder\Music.flac. As the files shouldn’t be in S3 yet, these keys shouldn’t exist. So I’ll have to make them using PowerShell.
Get-S3Object should return null as the object shouldn’t exist.
If this doesn’t happen then the object is already in the bucket. In this situation, PowerShell identifies the file causing the problem and then exits the script:
If the file isn’t found then PowerShell continues to run:
Else
{
Write-Output "$LocalSourceObjectFileName does not currently exist in S3 bucket."
}
Assuming no files are found at this point, the log will read as follows:
Checking if local files already exist in S3 bucket.
Checking S3 bucket for Artist-Track-ExtendedMix.flac
Artist-Track-ExtendedMix.flac does not currently exist in S3 bucket.
Checking S3 bucket for Artist-Track-OriginalMix.flac
Artist-Track-OriginalMix.flac does not currently exist in S3 bucket.
V2: Uploading Files Instead Of Folders
Now to start uploading to S3!
In Version 2 I’ve altered how this is done. Previously my script’s purpose was to upload a folder to S3 using the PowerShell cmdlet Write-S3Object.
Version 2 now uploads individual files instead. There is a reason for this that I’ll go into shortly.
This means I have to change things around as Write-S3Object now needs different parameters:
Instead of telling the -Folder parameter where the local folder is, I now need to tell the -File parameter where each file is located.
Instead of telling the -KeyPrefix parameter where to store the uploaded objects in S3, I now need to tell the -Key parameter the full S3 path for each object.
I’ll do -Key first. I start by opening another ForEach loop, and create an S3 key for each file in the same way I did earlier:
The main benefit of this approach is that, if something goes wrong mid-upload, the transcript will tell me which uploads were successful. Version 1’s script would only tell me that uploads had started, so in the event of failure I’d need to check the S3 bucket’s contents.
Speaking of failure, wouldn’t it be good to check that the uploads worked?
V2: Were The Uploads Successful?
For this, I’m still working in the ForEach loop I started for the uploads. After an upload finishes, PowerShell checks if the object is in S3 using the Get-S3Object command I wrote earlier:
This time I want the object to be found, so null is a bad result.
Next, I get PowerShell to do some heavy lifting for me. I’ve created a pair of new local folders called S3WriteSuccess and S3WriteFail. The paths for these are stored in Variables.ps1.
If my S3 upload check doesn’t find anything and returns null, PowerShell moves the file from the source folder to S3WriteFail using Move-Item:
If ($null -eq $LocalSourceObjectFileNameS3Check)
{
Write-Output "S3 Upload Check FAIL: $LocalSourceObjectFileName. Moving to local Fail folder"
Move-Item -Path $LocalSourceObjectFilepath -Destination $ExternalLocalDestinationFail
}
If the object is found, PowerShell moves the file to S3WriteSuccess:
Else
{
Write-Output "S3 Upload Check Success: $LocalSourceObjectFileName. Moving to local Success folder"
Move-Item -Path $LocalSourceObjectFilepath -Destination $ExternalLocalDestinationSuccess
}
The ForEach loop then repeats with the next file until all are processed.
So now, a failed upload produces the following log:
**********************
Beginning S3 Upload Checks On Following Objects: StephenJKroos-Micrsh-OriginalMix
S3 Upload Check: StephenJKroos-Micrsh-OriginalMix.flac
S3 Upload Check FAIL: StephenJKroos-Micrsh-OriginalMix. Moving to local Fail folder
**********************
Windows PowerShell transcript end
**********************
While a successful S3 upload produces this one:
**********************
Beginning S3 Upload Checks On Following Objects: StephenJKroos-Micrsh-OriginalMix
S3 Upload Check: StephenJKroos-Micrsh-OriginalMix.flac
S3 Upload Check Success: StephenJKroos-Micrsh-OriginalMix. Moving to local Success folder
**********************
Windows PowerShell transcript end
**********************
PowerShell then shows a final message before ending the transcript:
Write-Output "All files processed. Exiting."
Start-Sleep -Seconds 10
Stop-Transcript
##################################
####### EXTERNAL VARIABLES #######
##################################
#Load External Variables Via Dot Sourcing
. .\EDMTracksLosslessS3Upload-Variables.ps1
#Start Transcript
Start-Transcript -Path $ExternalTranscriptPath -IncludeInvocationHeader
###############################
####### LOCAL VARIABLES #######
###############################
#Get count of items in $ExternalLocalSource
#Get list of filenames in $ExternalLocalSource
$LocalSourceCount = (Get-ChildItem -Path $ExternalLocalSource | Measure-Object).Count
#Get list of extensions in $ExternalLocalSource
$LocalSourceObjectFileExtensions = Get-ChildItem -Path $ExternalLocalSource | ForEach-Object -Process { [System.IO.Path]::GetExtension($_) }
#Get list of filenames in $ExternalLocalSource
$LocalSourceObjectFileNames = Get-ChildItem -Path $ExternalLocalSource | ForEach-Object -Process { [System.IO.Path]::GetFileName($_) }
##########################
####### OPERATIONS #######
##########################
#Check there are files in local folder.
Write-Output "Counting files in local folder."
#If local folder less than 1, output this and stop the script.
If ($LocalSourceCount -lt 1)
{
Write-Output "No Local Files Found. Exiting."
Start-Sleep -Seconds 10
Stop-Transcript
Exit
}
#If files are found, output the count and continue.
Else
{
Write-Output "$LocalSourceCount Local Files Found"
}
#Check extensions are valid for each file.
Write-Output " "
Write-Output "Checking extensions are valid for each local file."
ForEach ($LocalSourceObjectFileExtension In $LocalSourceObjectFileExtensions)
{
#If any extension is unacceptable, output this and stop the script.
If ($LocalSourceObjectFileExtension -NotIn ".flac", ".wav", ".aif", ".aiff")
{
Write-Output "Unacceptable $LocalSourceObjectFileExtension file found. Exiting."
Start-Sleep -Seconds 10
Stop-Transcript
Exit
}
#If extension is fine, output the extension for each file and continue.
Else
{
Write-Output "Acceptable $LocalSourceObjectFileExtension file."
}
}
#Check if local files already exist in S3 bucket.
Write-Output " "
Write-Output "Checking if local files already exist in S3 bucket."
#Do following actions for each file in local folder
ForEach ($LocalSourceObjectFileName In $LocalSourceObjectFileNames)
{
#Create S3 object key using $ExternalS3KeyPrefix and current object's filename
$LocalSourceObjectFileNameS3Key = $ExternalS3KeyPrefix + $LocalSourceObjectFileName
#Create local filepath for each object for the file move
$LocalSourceObjectFilepath = $ExternalLocalSource + "\" + $LocalSourceObjectFileName
#Output that S3 upload check is starting
Write-Output "Checking S3 bucket for $LocalSourceObjectFileName"
#Attempt to get S3 object data using $LocalSourceObjectFileNameS3Key
$LocalSourceObjectFileNameS3Check = Get-S3Object -BucketName $ExternalS3BucketName -Key $LocalSourceObjectFileNameS3Key
#If local file found in S3, output this and stop the script.
If ($null -ne $LocalSourceObjectFileNameS3Check)
{
Write-Output "File already exists in S3 bucket: $LocalSourceObjectFileName. Please review. Exiting."
Start-Sleep -Seconds 10
Stop-Transcript
Exit
}
#If local file not found in S3, report this and continue.
Else
{
Write-Output "$LocalSourceObjectFileName does not currently exist in S3 bucket."
}
}
#Output that S3 uploads are starting - count and file names
Write-Output " "
Write-Output "Starting S3 Upload Of $LocalSourceCount Local Files."
Write-Output "These files are as follows: $LocalSourceObjectFileNames"
Write-Output " "
#Do following actions for each file in local folder
ForEach ($LocalSourceObjectFileName In $LocalSourceObjectFileNames)
{
#Create S3 object key using $ExternalS3KeyPrefix and current object's filename
$LocalSourceObjectFileNameS3Key = $ExternalS3KeyPrefix + $LocalSourceObjectFileName
#Create local filepath for each object for the file move
$LocalSourceObjectFilepath = $ExternalLocalSource + "\" + $LocalSourceObjectFileName
#Output that S3 upload is starting
Write-Output "Starting S3 Upload Of $LocalSourceObjectFileName"
#Write object to S3 bucket
Write-S3Object -BucketName $ExternalS3BucketName -File $LocalSourceObjectFilepath -Key $LocalSourceObjectFileNameS3Key -StorageClass $ExternalS3StorageClass
#Output that S3 upload check is starting
Write-Output "Starting S3 Upload Check Of $LocalSourceObjectFileName"
#Attempt to get S3 object data using $LocalSourceObjectFileNameS3Key
$LocalSourceObjectFileNameS3Check = Get-S3Object -BucketName $ExternalS3BucketName -Key $LocalSourceObjectFileNameS3Key
#If $LocalSourceObjectFileNameS3Key doesn't exist in S3, move to local Fail folder.
If ($null -eq $LocalSourceObjectFileNameS3Check)
{
Write-Output "S3 Upload Check FAIL: $LocalSourceObjectFileName. Moving to local Fail folder"
Move-Item -Path $LocalSourceObjectFilepath -Destination $ExternalLocalDestinationFail
}
#If $LocalSourceObjectFileNameS3Key does exist in S3, move to local Success folder.
Else
{
Write-Output "S3 Upload Check Success: $LocalSourceObjectFileName. Moving to local Success folder"
Move-Item -Path $LocalSourceObjectFilepath -Destination $ExternalLocalDestinationSuccess
}
}
#Stop Transcript
Write-Output " "
Write-Output "All files processed. Exiting."
Start-Sleep -Seconds 10
Stop-Transcript
V2Visibility.ps1 On GitHub
VariablesBlank.ps1 Version 2
##################################
####### EXTERNAL VARIABLES #######
##################################
#The local file path for the transcript file
#E.g. "C:\Users\Files\"
$ExternalTranscriptPath =
#The local file path for objects to upload to S3
#E.g. "C:\Users\Files\"
$ExternalLocalSource =
#The S3 bucket to upload objects to
#E.g. "my-s3-bucket"
$ExternalS3BucketName =
#The S3 bucket prefix / folder to upload objects to (if applicable)
#E.g. "Folder\SubFolder\"
$ExternalS3KeyPrefix =
#The S3 Storage Class to upload to
#E.g. "GLACIER"
$ExternalS3StorageClass =
#The local file path for moving successful S3 uploads to
#E.g. "C:\Users\Files\"
$ExternalLocalDestinationSuccess =
#The local file path for moving failed S3 uploads to
#E.g. "C:\Users\Files\"
$ExternalLocalDestinationFail =
Version 2 VariablesBlank.ps1 On GitHub
V2: Evaluation
Overall I’m very happy with how this all turned out! Version 2 took a script that worked with some supervision, and turned it into something I can set and forget.
The various checks now have my back if I select the wrong files or if my connection breaks. And, while the Get-S3Object checks mean that I’m making more S3 API calls, the increase won’t cause any bill spikes.
The following is a typical transcript that my script produces following a successful upload of two .flac files:
**********************
Transcript started, output file is C:\Users\Files\EDMTracksLosslessS3Upload.log
Counting files in local folder.
2 Local Files Found
Checking extensions are valid for each local file.
Acceptable .flac file.
Acceptable .flac file.
Checking if local files already exist in S3 bucket.
Checking S3 bucket for MarkOtten-Tranquility-OriginalMix.flac
MarkOtten-Tranquility-OriginalMix.flac does not currently exist in S3 bucket.
Checking S3 bucket for StephenJKroos-Micrsh-OriginalMix.flac
StephenJKroos-Micrsh-OriginalMix.flac does not currently exist in S3 bucket.
Starting S3 Upload Of 2 Local Files.
These files are as follows: MarkOtten-Tranquility-OriginalMix StephenJKroos-Micrsh-OriginalMix.flac
Starting S3 Upload Of MarkOtten-Tranquility-OriginalMix.flac
Starting S3 Upload Check Of MarkOtten-Tranquility-OriginalMix.flac
S3 Upload Check Success: MarkOtten-Tranquility-OriginalMix.flac. Moving to local Success folder
Starting S3 Upload Of StephenJKroos-Micrsh-OriginalMix.flac
Starting S3 Upload Check Of StephenJKroos-Micrsh-OriginalMix.flac
S3 Upload Check Success: StephenJKroos-Micrsh-OriginalMix.flac. Moving to local Success folder
All files processed. Exiting.
**********************
Windows PowerShell transcript end
End time: 20220617153926
**********************
In this post, I created a script to upload lossless music files from my laptop to one of my Amazon S3 buckets using PowerShell.
I introduced automation to perform checks before and after each upload, and logged the outputs to a transcript. I then produced a repo for the scripts, accompanied by a ReadMe document.
If this post has been useful, please feel free to follow me on the following platforms for future updates: