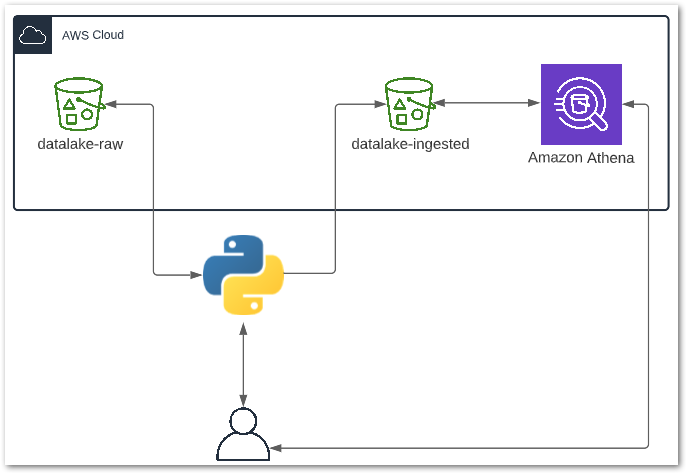
In this post, I try automating my laptop’s application management with the Windows Package Manager tool Winget.
Table of Contents
- Introduction
- User Story
- Introducing Winget
- Winget Scripting With VSCode
- Automation With Task Scheduler
- Summary
Introduction
After much frustration with my laptop’s performance, I finally booked it in for upgrades to an SSD hard drive and 16GB RAM. It’s now very responsive and far faster!
The shop originally planned to clone my existing HDD drive onto the new SSD. Unfortunately, the clone kept failing due to some bad sectors. Fortunately, this didn’t present a risk of data loss – most of my files are in OneDrive, and everything else is either in Amazon S3 or on external drives.
The failing clone meant that none of my previously installed programs and packages were on the new drive. I wasn’t flying blind here though, as I regularly use the free Belarc Advisor tool to create a list of installed programs.
But this is a heavily manual process, and the Belarc Advisor files contain a lot of unnecessary data that isn’t easy to use. So I found myself looking for an alternative!
User Story
In this section, I outline the problem I want to solve.
I want to capture a list of all applications installed on a given Windows device so that I can audit my device and have a better disaster recovery strategy.
ACCEPTANCE CRITERIA:
The process must be fully automated. I don’t want another job to do – I want the device to own this process.
The process must be efficient. Belarc Advisor gets the job done, but it takes time to load and does a bunch of other stuff that I don’t need.
There is no budget. Belarc Advisor isn’t ideal, but it’s free. I don’t want to start spending money on this problem now.
Introducing Winget
This section explains what Winget is and examines some of the features and benefits it offers.
What Is Winget?
Winget is a Windows Package Manager that helps install, upgrade, configure and delete applications on Windows 10 and Windows 11.
Package Managers look through configured repositories like the Windows Package Manager Community Repository for applications. If the application is available, it will be downloaded from the repository and installed onto the device.
Microsoft has open-sourced Winget, and has committed it to their GitHub account. After installation, Winget is accessible via the Windows Terminal, PowerShell, and the Command Prompt.
Package Manager Benefits
Package Managers like Winget offer several benefits over traditional methods:
- Applications are installed as CLI commands, so there is no need to navigate to different websites or go through multiple installation steps.
- Their repositories enforce a strict submission policy and use standardized package formats, so applications are installed consistently and reliably.
- They manage application dependencies. If a desired application needs another application to work, the package manager will automatically install that application as well.
- They lend themselves well to CI/CD pipelines, IAC and disaster recovery, as package manager commands can be used in scripts and automated processes.
- Community tools like winstall exist that can create batch-installation Winget commands and scripts using a web GUI.
Winget Commands
Winget regularly receives new commands, a list of which is maintained by Microsoft. These commands can be loosely grouped into:
- Winget & Device Info e.g.
info,sourceandfeatures - Package Operations e.g.
search,installandupgrade - Package Visibility e.g.
listandexport
For this post, I will be focusing on the last group.
winget list displays a list of installed applications. The list includes the current version and the package’s source, and has several filtration options.
The winget list syntax is:
winget list [[-q] \<query>] [\<options>]winget export creates and exports a JSON file of apps to a specified path.
This JSON file can combine with the winget import command to allow the batch-installing of applications and the creation of build environments.
winget export‘s JSON files do not include applications that are unavailable in the Windows Package Manager Community Repository. In these cases, the export command will show a warning.
The winget export syntax is:
winget export [-o] <output> [<options>]Winget Scripting With VSCode
In this section, I write a script that will run the Winget commands.
I’m writing the script using Visual Studio Code, as this allows me to write the Winget script in the same way as other PowerShell scripts I’ve written.
Unique Filename
Firstly, I want to give each file a unique filename to make sure nothing is overwritten. A good way to do that here is by capturing Get-Date‘s output formatted as the ISO 8601 standard:
$RunDate = Get-Date -Format 'yyyy-MM-dd-HHmm'
This returns a string with an appropriate level of granularity, as I’m not going to be running this script multiple times a minute:
2023-04-26-1345Winget Export Code
Next, I’ll script my export command.
I need to tell Winget where to create the file, and what to call it. I create a new folder for the exports and capture its path in a $ExportsFilePath variable.
Then I create a $ExportsFileName variable for the first part of the export file’s name. It uses a WingetExport string and the device’s name, which PowerShell can access using $env:computername:
$ExportsFileName = 'WingetExport' + '-' + $env:computername + '-'
Including the computer’s name means I can run this script on different devices and know which export files belong to which device:
WingetExport-LAPTOP-IFIJ32T-My third $ExportsOutput variable joins everything together to produce an acceptable string for winget export‘s output argument:
$ExportsOutput = $ExportsFilePath + '\' + $ExportsFileName + $RunDate + '.json'
An example of which is:
C:\{PATH}\WingetExport-LAPTOP-IFIJ32T-2023-04-26-1345.jsonFinally, I can script the full command. This command creates an export file at the desired location and includes application version numbers for accuracy and auditing:
winget export --output $ExportsOutput --include-versions
Here are some sample exports:
{
"$schema": "https://aka.ms/winget-packages.schema.2.0.json",
"CreationDate": "2023-04-27T11:02:04.321-00:00",
"Sources": [
{
"Packages": [
{
"PackageIdentifier": "Git.Git",
"Version": "2.40.0"
},
{
"PackageIdentifier": "Anki.Anki",
"Version": "2.1.61"
},
{
"PackageIdentifier": "Microsoft.PowerToys",
"Version": "0.69.1"
}
],
"SourceDetails": {
"Argument": "https://cdn.winget.microsoft.com/cache",
"Identifier": "Microsoft.Winget.Source_8wekyb3d8bbwe",
"Name": "winget",
"Type": "Microsoft.PreIndexed.Package"
}
}
],
"WinGetVersion": "1.4.10173"
}As a reminder, these exports don’t include applications that are unavailable in Winget. This means winget export alone doesn’t meet the user story requirements, so there is still work to do!
Winget List Code
Finally, I’ll script my list command. This is mostly similar to the export command and I create the file path in the same way:
$ListsOutput = $ListsFilePath + '\' + $ListsFileName + $RunDate + '.txt'
The filename is changed for accuracy, and the suffix is now TXT as no JSON is produced:
WingetList-LAPTOP-IFIJ32T-2023-04-25-2230.txtNow, while winget list shows all applications on the device, it has no argument to save this list anywhere. For that, I need to pipe the winget list output to a PowerShell command that does create files – Out-File:
winget list | Out-File -FilePath $ListsOutput
Out-File writes the list to the $ListsOutput path, producing rows like these:
| Name | Id | Version | Available | Source |
|---|---|---|---|---|
| Anki | Anki.Anki | 2.1.61 | winget | |
| Audacity 2.4.2 | Audacity.Audacity | 2.4.2 | 3.2.4 | winget |
| DBeaver 23.0.2 | dbeaver.dbeaver | 23.0.2 | winget | |
| S3 Browser version 10.8.1 | S3 Browser_is1 | 10.8.1 |
The entire script takes around 10 seconds to run in an open PowerShell session and produces no CPU spikes or memory load. The script is on my GitHub with redacted file paths.
Automation With Task Scheduler
In this section, I put Task Scheduler in charge of automating my application management Winget script.
What Is The Task Scheduler?
Task Scheduler began life on Windows 95 and is still used today by applications including Dropbox, Edge and OneDrive. Parts of it aren’t great. The Send Email and Display Message features are deprecated, and monitoring and error handling relies on creating additional tasks that are triggered by failure events.
However, it’s handy for running local scripts and has no dependencies as it’s built into Windows. It supports a variety of use cases which can be scripted or created in the GUI. Existing tasks are exportable as XML.
Creating A New Task
There is plentiful documentation for the Task Scheduler. The Microsoft Learn developer resources cover every inch of it, and these Windows Central and Windows Reports guides are great resources with extensive coverage.
In my case, I create a new ApplicationInventory task, set to trigger every time I log on to Windows:
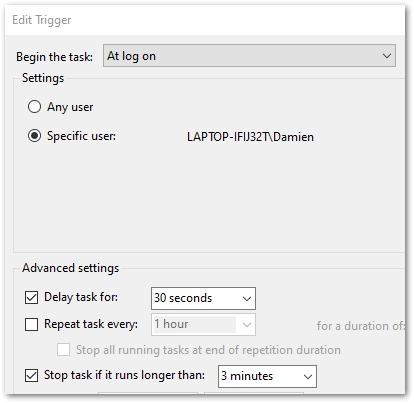
The task starts powershell.exe, passing an argument of -file "C:\{PATH}\ApplicationInventory.ps1".
This works, but will force a PowerShell window to open every time the schedule runs. This can be stopped by configuring the task to Run whether user is logged on or not. Yup – it feels a bit hacky. But it works!
I now have a new scheduled task:

Testing
An important part of automating my application management with Winget is making sure everything works! In this section, I check the script and automation processes are working as expected.
I’ll start with the task automation. Task Scheduler has a History tab, which filters events from Event Viewer. Upon checking this tab, I can see the chain of events marking a successful execution:
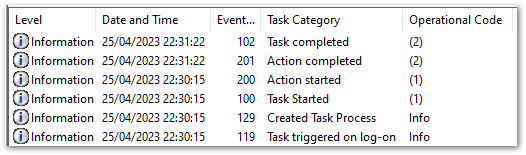
When I check the WingetExport folder, it contains an export file created on 25/04/2023 at 22:30:

And there are similar findings in the WingetList folder:
Both files open successfully and contain the expected data. Success!
Summary
In this post, I try automating my laptop’s application management with the Windows Package Manager tool Winget.
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~