In this post, I use Simba Athena to create a secure connection between my iTunes data in Amazon Athena and Microsoft Power BI.
Table of Contents
Introduction
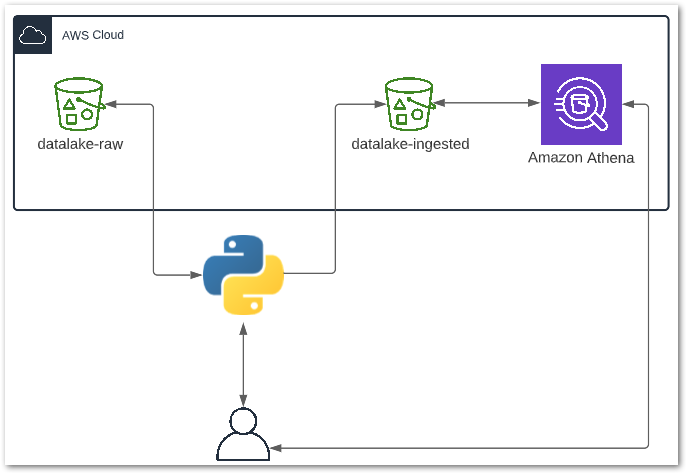
In my recent posts, I’ve been transforming an iTunes Export CSV file using Python and AWS.
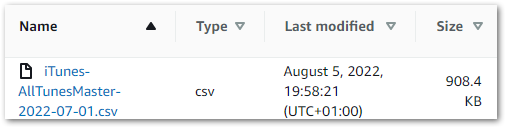
Firstly, in July I built a Python ETL that extracts data from my iTunes CSV into a Pandas DataFrame and transforms some columns.
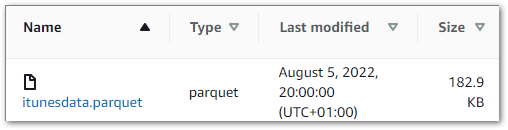
Next, I updated my ETL script at the start of August. It now uploads the changed data to S3 as a Parquet file. Then I made my data available in an Athena table so I could use some of Athena’s benefits:
- My data now has high availability at low cost.
- My data can be queried faster from Athena than from the CSV.
- I can limit what data is accessed, as opposed to all-or-nothing.
Now I want to start analysing my data. There are many business intelligence (BI) tools available to help me with this. I will be using the latest version of Power BI on my Windows 10 laptop.
But wait. If Power BI is on my laptop and my data is in Athena, how can Power BI access my data? Do I need to make my AWS resources publically accessible? Do I need to download the data to my laptop?
Fortunately not! Welcome to the world of data connectors. Meet Simba Athena.
Simba Athena
In this section, I will look at how Simba Athena bridges the gap between my locally-installed BI tool and my data in AWS.
What Is Simba Athena?
Simba Athena is an Open Database Connectivity (ODBC) driver built for Athena. The history of Simba dates back to 1992 when Simba Technologies co-developed the first standards-based ODBC driver with Microsoft. Magnitude acquired Simba Technologies in 2016.
Simba offers numerous data connectors that all work in roughly the same way:
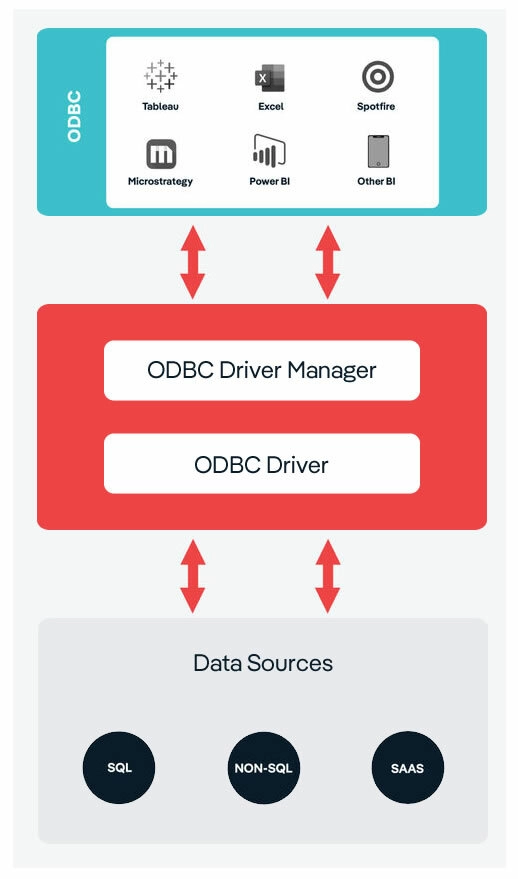
Relating this diagram to Athena and Power BI:
- The user sends a query to Power BI.
- Power BI passes the query to Simba Athena via the ODBC Device Manager.
- Simba Athena queries Athena and gets the results.
- Simba Athena passes the results to Power BI via the ODBC Device Manager.
- Power BI shows the results to the user.
Features Of Simba Athena
Simba Athena has several features that make it a great partner for Athena:
- Simba Athena works with Windows, macOS and Linux. Just as Athena supports multiple operating systems, Simba Athena is also OS-agnostic.
- Simba Athena supports a range of AWS IAM and Azure Active Directory Federation Services (AD FS) authentication methods. This opens up options like IAM credentials, STS tokens and Federated Identity.
- Simba Athena supports many Athena features including querying the AWS Glue Data Catalog and connecting to an Apache Hive metastore.
- Numerous applications support Simba Athena including Excel, Tableau and Power BI.
Speaking of Power BI…
Microsoft Power BI
In this section, I will examine Power BI and explain why I chose to use it.
What Is Power BI?
Microsoft Power BI is a data visualization solution with a primary focus on BI. At the time of writing, Power BI’s main components are:
- Power BI Desktop: a free locally-installed application designed for connecting to, transforming, and visualizing data.
- Power BI Service: a cloud-based SaaS supporting the deployment and sharing of dashboards.
- Power BI Mobile: a mobile app platform for Windows, iOS, and Android devices.
So what makes Power BI a good choice here?
Choosing Power BI
My decision to use Power BI came down to three factors:
- Prior Experience. I’ve used Power BI many times over the years, and have become very familiar with it. This will let me deliver results quickly.
- Support: Both Microsoft and AWS have rich documentation for Simba Athena. This gives me confidence in setting it up and reduces the chance of any blockers.
- Reputation: 2022 is Microsoft’s 15th consecutive year as a leader in the Gartner Magic Quadrant for Analytics and Business Intelligence Platforms as a result of Power BI and their other BI tools:

So now I’ve talked about Simba Athena and Power BI, let’s get them working together.
Setting Up Simba Athena
In this section, I will install and configure Simba Athena on my laptop. I will then attempt to extract data from Athena using Power BI.
The remainder of this post will focus on the Windows version of Simba Athena. AWS offers download links for Windows, Linux and macOS, and provides installation instructions in the Simba Athena Documentation.
Downloading Simba Athena
The first step is to download the Simba Athena ODBC driver provided by AWS. The options vary depending on platform and bitness.
The installation process mainly focuses on the end-user license agreement and destination folder selection. Once Simba Athena is installed, it can be configured.
Configuring Simba Athena
Simba Athena’s configuration settings are available via the Windows ODBC Data Source Administrator. This can be found in the Start Bar’s Windows Administrative Tools folder, or by running a Windows search for ODBC.
Accessing this and selecting the System DSN tab shows Simba Athena as a System Data Source:
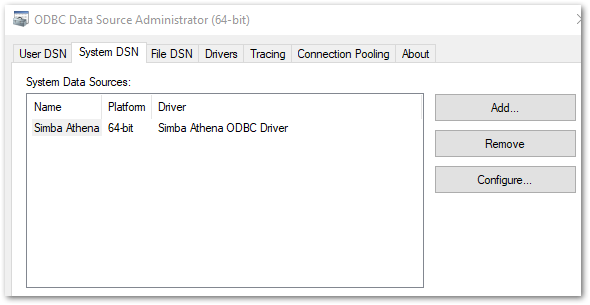
From here, selecting Configure shows a setup screen with a few familiar fields:
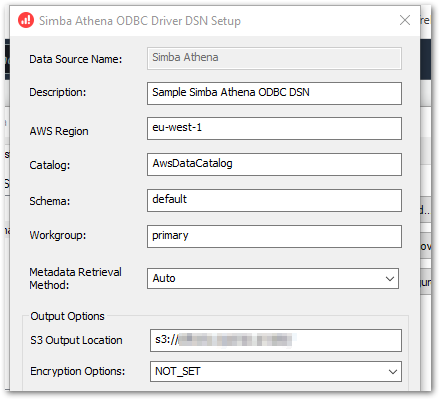
Of these, Catalog, Schema and Workgroup are pre-populated with Athena defaults and Metadata Retrieval Method is set to Auto.
That leaves the Data Source Name and Description to identify the data source, and the AWS Region containing the Athena data.
In Output Options, I can state my S3 Output Location and Encryption Options. The output location is Athena’s Query Result Location, and the encryption options should mirror the S3 bucket’s encryption settings.
If the S3 Output Location is left blank, this will cause an error when Power BI tries to connect to Athena:
Details: "ODBC: ERROR [HY000] [Simba][Athena] (1040) An error has been thrown from the AWS Athena client. Athena Error No: 130, HTTP Response Code: 400, Exception Name: InvalidRequestException, Error Message: outputLocation is null or empty Simba Athena’s remaining settings are out of scope for this post, although there’s one I definitely need to mention – Authentication Options:
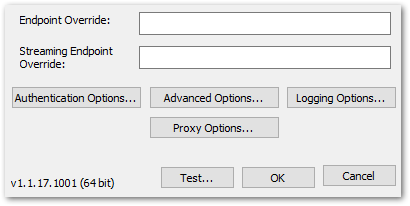
This is how Simba Athena authenticates its requests to AWS. As mentioned earlier, there are several options here. Depending on the authentication type selected, Simba Athena can store Access Keys, Session Tokens, TenantIDs and any other required credentials.
That’s all the Simba Athena configuration I’m going to do here. For full details on all of Simba Athena’s features, please refer to the Simba Athena Documentation.
Now let’s use Simba Athena to get Athena and Power BI talking to each other!
Using Simba Athena
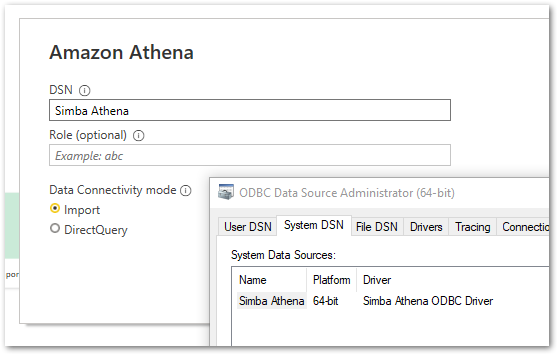
The Athena documentation has a great section about using the Athena Power BI connector. After launching Power BI and selecting Amazon Athena as a data source, Power BI will need to know which DSN to use.
This is the Simba Athena DSN in the System DSN tab:
The Navigator screen then shows my Athena data catalog, my blog_amazonwebshark database, and my basic_itunes_python_etl table with a sample of the data it contains:
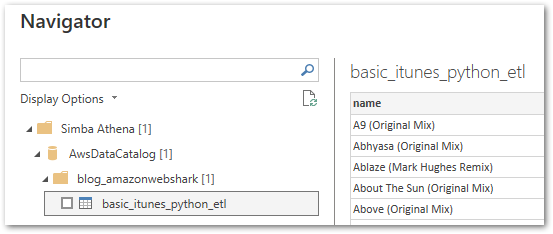
That’s everything! My basic_itunes_python_etl Athena table is now available in Power BI.
Summary
In this post, I used Simba Athena to create a secure connection between my iTunes data in Amazon Athena and Microsoft Power BI.
This post was originally part of a larger post that is still being written. But after I’d finished my Simba Athena section it made sense to have a separate post for it!
Finally, in other news, this post’s featured image is a DALL·E 2 creation. This was by far the best image it gave me for pixel art baby lion and shark – I’m sure it’ll improve soon!
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~