
In this post, I will talk about my main takeaways from my visit to the AWS Summit London 2022 event.
Table of Contents
Introduction
Anyone following my Instagram will have seen that I attended the AWS Summit London 2022 event in April. This was my first AWS event, and I had a great time watching the presentations, taking in the atmosphere and finding things that a magnetic shark could stick to.
Besides stickers and badges, I left the event with pages of notes and photos of slides that fell roughly into two lists:
- Consider for work
- Consider for me
I’ve done the work list, so it’s time for mine! This post has two halves. Firstly, I’ll talk about some of the AWS services I want to try out on the blog over the next few months.
Then, in the second half, I’ll talk about some of the third party presentations that introduced me to interesting things that I hadn’t heard about before.
Let’s get started!
AWS Presentations
In this section, I’ll talk about some of the services mentioned in the AWS Summit London 2022 sessions that I want to try out over the next few months.
Amazon CloudWatch SDK For Python
Having seen the CloudWatch SDK in passing while studying for my Certified Developer Associate certification, I saw a demo of it in one of the sessions.
I was impressed with how quick and simple the SDK is to use, and have a few ideas for it as part of some Python ETLs and IoT functions I want to try. In addition, I can create and then re-use common monitoring modules to save myself some time in future.
Amazon Timestream
From the Amazon Timestream website:
Amazon Timestream is a fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day up to 1,000 times faster and at as little as 1/10th the cost of relational databases.
Some time soon I’m hoping to try out a Raspberry Pi project that uses a temperature sensor. Timestream looks like a good fit for this! It’s built with IoT in mind, is serverless and offers built-in analytics. In addition, it offers integrations with Amazon Kinesis and Grafana, so it sounds simple to get off the ground.
AWS Data Exchange
From the AWS Data Exchange website:
AWS Data Exchange makes it easy to find, subscribe to, and use third-party data in the cloud.
After you’ve subscribed to a data product, you can use the AWS Data Exchange API to load data directly into Amazon Simple Storage Service (S3) and use a range of AWS analytics and machine learning (ML) services to analyze it.
One of the challenges of trying out services aimed at big data is a lack of big data.
Sample databases like Northwind, AdventureWorks and WideWorldImporters have been around for a while, helping generations of people learn their craft. However, Northwind was intended for SQL Server 2000. And although WideWorldImporters is more recent it’s a bit limited by modern standards.
AWS Data Exchange offers a variety of modern Data Products via the AWS Marketplace. Currently, there are over 3500 Data Products and almost half of them cost nothing to access. So lots to use for potential EMR, Glue and SageMaker projects!
AWS DataOps Development Kit (DDK)
From the AWS DataOps Development Kit repo:
The AWS DataOps Development Kit is an open source development framework for customers that build data workflows and modern data architecture on AWS. Based on the AWS CDK, it offers high-level abstractions allowing you to build pipelines that manage data flows on AWS, driven by DevOps best practices.
The DDK joins the CDK as something I want to try out. I’ve not done anything with infrastructure as code on the blog yet. However, the CDK sounds like a good place to start, and the DDK could quickly spin me up some infrastructure to use with some Data Exchange data.
AWS One Observability Workshop
From the One Observability Workshop Studio:
You will learn about AWS observability functionalities on Amazon CloudWatch, AWS X-Ray, Amazon Managed Service for Prometheus, Amazon Managed Grafana and AWS Distro for OpenTelemetry (ADOT). The workshop will deploy a micro-service application and help you learn monitoring.
I’ve already made some bespoke monitoring for my main AWS account. I’m interested in trying this workshop out to see what else I can learn. I’m also keen on getting some first-hand experience with X-Ray, Prometheus and Grafana.
Third-Party Presentations
In this section, I’ll talk about some of the third party presentations that introduced me to interesting things that I hadn’t heard about before.
Cazoo’s Serverless Architecture
Cazoo‘s Engineering Coach Bob Gregory spoke about their use of AWS serverless technologies including Lambda, DynamoDB and Athena. As a result, Cazoo was the first to market and could scale quickly in response to rapid customer demand.
This was my first time hearing about Cazoo, and Bob turned a very business-oriented presentation into a chat with some mates at the pub. He has a great speaking style, an example of which is here:
Amazon published a press release about Cazoo on the day of the Summit. It details Cazoo’s current and future relationship with AWS and includes Cazoo’s plans to integrate various AWS machine learning tools. Examples include Textract for paperwork processing and invoice management and Rekognition for inventory handling and rapid image and video analytics.
And speaking of analytics…
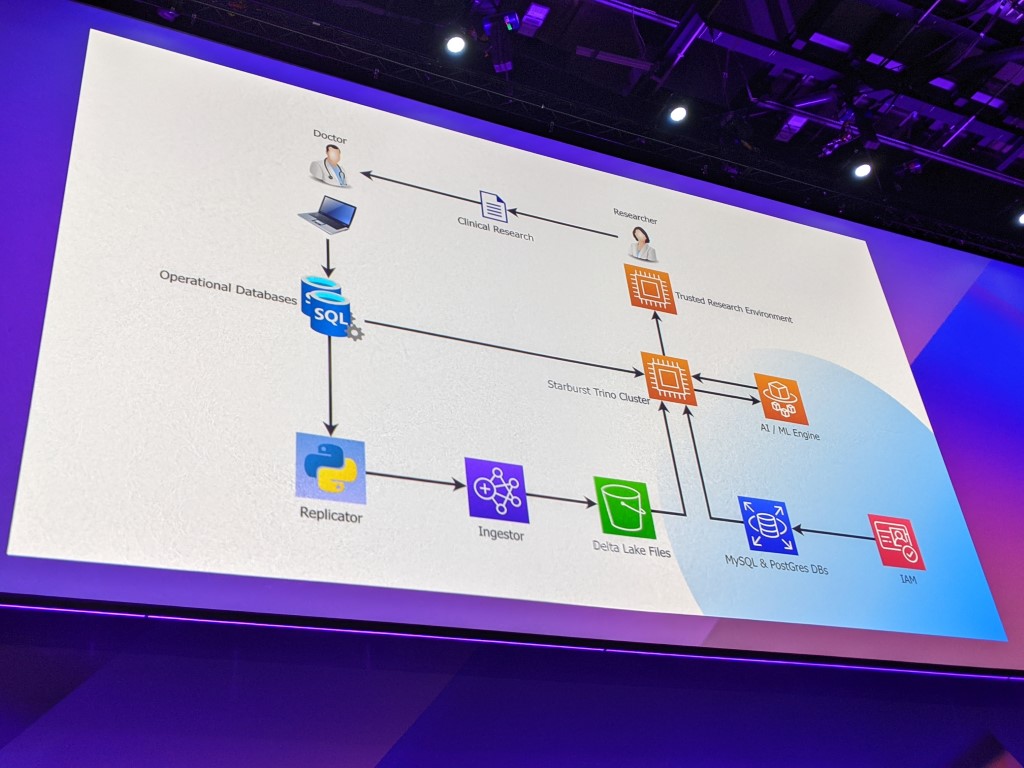
EMIS Group’s Data Architecture
EMIS Group‘s CTO Richard Jarvis spoke about how they use various AWS services to ingest, analyse and present health care data. During the 2020 Pandemic, they were able to quickly analyse national COVID-19 data and provide clinical research about topics including transmission, treatment and vaccination.
EMIS Group’s data security includes a Data Mesh architecture, which separates data producers from data consumers. Meanwhile, AWS IAM handles the security of their applications by controlling how users access them and how they interact with each other.
As a result, EMIS Group can ensure that the right applications are accessible by the right people, and that sensitive and personal data is stored appropriately and in line with GDPR.
Ocado’s Fulfilment Robots
Ocado‘s Chief Technology Officer James Donkin and Chief of Advanced Technology Alex Harvey spoke about the use of AWS at their fulfilment centres. Ocado has made a name for itself in the field of robotics and has used this technology to drive efficiency and innovation.
That video is from 2018 and a lot has changed since then. This year Ocado have begun upgrading to their new 600 Series fulfilment robot, pictured here:

Wait. That’s a Borg Cube. Hold on.

Alex and James talked about the challenges of operating thousands of robots, and how AWS help them innovate and scale while maintaining low latency and cost. Ocado deploys microservices and web applications to AWS, which the robots rely on for communication and navigation.
Further information is available on an Ocado case study on the AWS website.
Summary
In this post, I discussed the main takeaways from my recent visit to the AWS Summit London 2022 event. I talked about some of the services I want to try out on the blog over the next few months, as well as some of the third party presentations that introduced me to interesting things that I hadn’t heard about before.
In conclusion, I had a great time at the summit! I came away with a lot of good ideas and had some great conversations. Hopefully, I’ll be able to go back next year!
If this post has been useful, please feel free to follow me on the following platforms for future updates:
Thanks for reading ~~^~~
















