In this post, I have a hands-on with AWS CloudFormation‘s new IaC Generator feature and give my thoughts on the experience.
Table of Contents
Introduction
Earlier this month, AWS launched new CloudFormation features for importing existing AWS resources:
AWS CloudFormation launches a new feature that makes it easy to generate AWS CloudFormation templates and AWS CDK apps for existing AWS resources that are managed outside CloudFormation.
You can use the generated templates and apps to import resources into CloudFormation and CDK or replicate resources in a new AWS Region or account.
https://aws.amazon.com/about-aws/whats-new/2024/02/aws-cloudformation-templates-cdk-apps-minutes/
An announcement from AWS Ray Of Sunshine Matheus Guimaraes followed this:
I’ve suggested something like this to AWS before, so I was very keen to try IaC Generator with my recently created WordPress data pipeline resources!
Firstly, I’ll explain some of the fundamental concepts of CloudFormation and the IaC Generator. Next, I’ll run the generator on my AWS account and see what comes back. Finally, I’ll run some tests and give my findings and thoughts.
Services Primer
This section introduces AWS CloudFormation and the IaC Generator, and explains what they’re for.
AWS CloudFormation
AWS CloudFormation is an infrastructure as code (IaC) service that manages and provisions AWS resources using code and automation instead of manual processes. It can configure resources, handle dependencies and estimate costs as part of a reproducible version-controlled CI/CD pipeline.
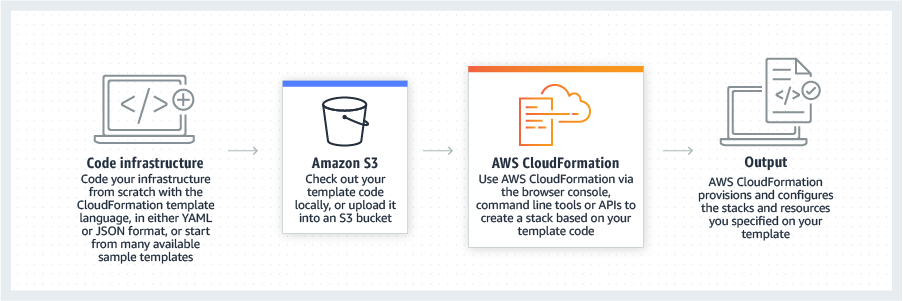
CloudFormation has extensive functionality. For this post, the two concepts I’m most interested in are:
CloudFormation Templates: JSON or YAML formatted text files which serve as blueprints for building AWS resources. Templates form the basis of CloudFormation Stacks.
CloudFormation Stacks: Collections of AWS resources that are managed as a single unit. Creating, updating or deleting a stack directly influences the related resources. Stacks can represent constructs like serverless applications, web servers and event-driven architectures.
The CloudFormation User Guide has further reading with sample code.
CloudFormation IaC Generator
The IaC Generator is a CloudFormation feature designed for use with manually provisioned resources:
With the AWS CloudFormation IaC generator (infrastructure as code generator), you can generate a template using AWS resources provisioned in your account that are not already managed by CloudFormation. Use the template to import resources into CloudFormation or replicate resources in a new account or Region.
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/generate-IaC.html
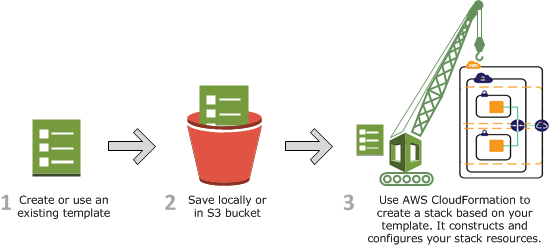
The generator has three steps:

IaC Generator can be used from the CloudFormation console and the AWS CLI.
IaC Generator Hands-On
In this section, I have an IaC Generator hands-on using CloudFormation’s console. Let’s start with an account scan.
Account Scan
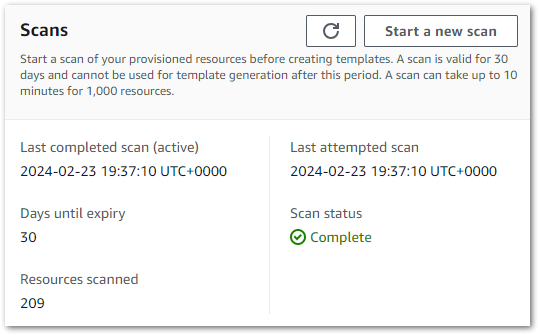
Firstly, IaC Generator needs to know about my AWS account’s resources. The generator then uses a completed scan to create a resource inventory which is valid for 30 days.
IaC Generator scans are limited per day. Accounts with under 10,000 resources can perform 3 daily scans, while larger accounts can perform a single daily scan. Like CloudFormation, IaC Generator is a regional service that scans resources in the selected region. Avoid wasted scans and unintended confusion by checking the selected region is correct before starting the scan!
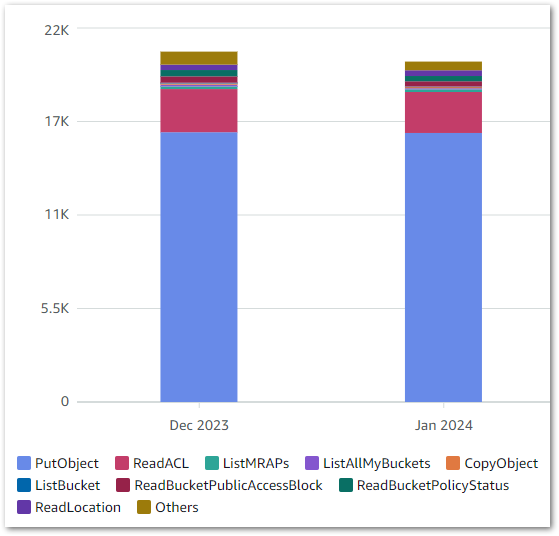
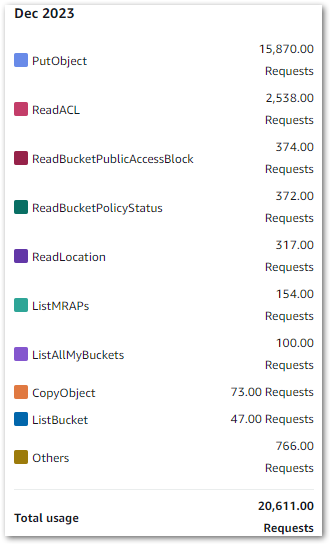
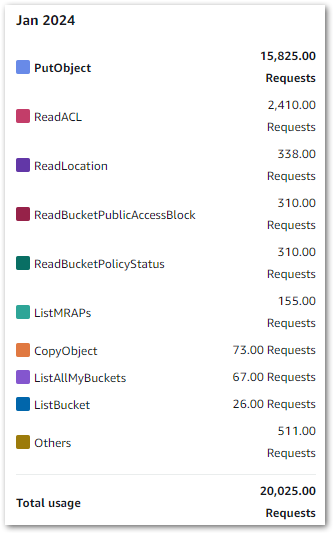
In my account, IaC Generator found 209 resources in my main region in about two minutes.
I then ran a second scan in a different region to see what would happen. It found 71 resources, so a clear difference. Interestingly, resources from global services like S3 and IAM were included in both scans while regional services like Lambda and CloudWatch resources weren’t. So pay attention to the selected region!
With a successful scan, I can now make a template.
Template Generation
There are three steps to making an IaC Generator template:
- Specify template details
- Add scanned resources
- Add related resources
Template Details
Firstly, the generator asks if it’s creating a new template or updating an existing one. Selecting the latter displays that region’s CloudFormation stacks, but I don’t have any yet so let’s move on.
Secondly, the generator asks for a template name and sets the stack DeletionPolicy and UpdateReplacePolicy attributes to Retain:
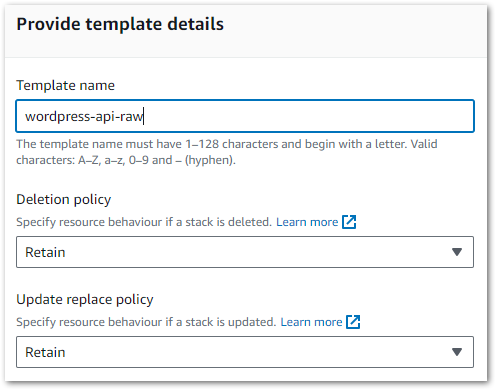
These are important decisions, so let’s clarify what they mean and why they default to Retain.
The DeletionPolicy attribute controls what happens to resources when a stack is deleted. It has two options:
- Delete: CloudFormation deletes the stack and the resources. Nothing is kept.
- Retail: CloudFormation deletes the stack and keeps the resources and their data.
The UpdateReplacePolicy attribute controls what happens to a resource that must be changed during a stack update. For example, upgrading an EC2 instance or a Lambda function.
It has three options:
- Delete: CloudFormation makes new resources and then deletes the old ones.
- Retain: CloudFormation makes new resources and keeps the existing ones. The old resources are then removed from CloudFormation’s scope.
- Snapshot: For resources that support snapshots like RDS and EBS, CloudFormation creates a snapshot for the resource before deleting it.
The Retain default for both policies ensures that no unintended resource deletions happen while using the generator. When using Retain, remember that CloudFormation-created resources cost the same as their manual counterparts and can get expensive if forgotten about!
The IaC Generator applies these attributes to every resource in the template. After creation, they can be changed for specific resources if needed.
Adding Resources
Next, IaC Generator shows the resources found in the most recent scan. For example:
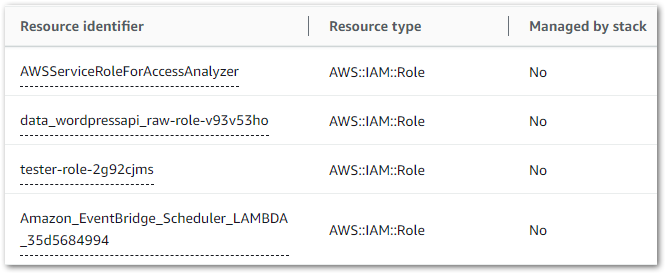
This can be a big list, and can be filtered by:
- Resource Type
- Tag Key
- Tag Value
- Resource Identifier
So, filtering on Resource Type = bucket returns S3 buckets and S3 bucket policies, while Resource Identifier = rtb returns VPC route tables. Desired resources can then be selected, appearing in a list under the scan results.
Next, IaC Generator checks my selections and recommends related resources that enable service interactions or belong to the same workload. Here, it suggested two IAM roles for my Lambda function and EventBridge scheduler that I’d missed. This is great, as that would have caused big problems down the line!
Finally, IaC Generator summarises the selections and creates a CloudFormation template.
IaC Generator Outputs
In this section, I examine the template and notifications provided by IaC Generator following my hands-on.
Summary
After IaC Generator has created a template, three tabs are presented:
- Template Definition: The IaC Generator template in
YAMLandJSON, with options to download it, copy it and import it to a CloudFormation stack. - Template Resources: A list of the template’s resource types, each resource’s CloudFormation Logical ID (which can be changed) and each resource’s status within the template. Resources can be added to the template and resynced if they’ve changed since the initial scan.
- AWS CDK: A two-step process to generate a CDK application for the template using the
cdk migratecommand. This is out of scope for this post, but this is the generated Python command:
cdk migrate --stack-name wordpress-api-raw --from-path ./wordpress-api-raw.yaml --language pythonSo let’s take a look at the template!
Template Examination
The full template comes in at 500 lines! So I’ll pull out some sections and take a closer look instead of going through the whole thing. Firstly, one of my SNS topics. I’ve highlighted the FIFO setting, subscription protocol and topic name:
SNSTopic00lambdageneralfailure00CeVCO:
UpdateReplacePolicy: "Retain"
Type: "AWS::SNS::Topic"
DeletionPolicy: "Retain"
Properties:
FifoTopic: false
Subscription:
- Endpoint: "[REDACTED_EMAIL]"
Protocol: "email"
TracingConfig: "PassThrough"
ArchivePolicy: {}
TopicName: "lambda-general-failure"Next, my data lakehouse S3 bucket. I’ve highlighted the bucket name, object ownership setting and default encryption setting:
S3Bucket00datalakehouseraw[REDACTED_AWS_ACC_ID]00GtGFU:
UpdateReplacePolicy: "Retain"
Type: "AWS::S3::Bucket"
DeletionPolicy: "Retain"
Properties:
PublicAccessBlockConfiguration:
RestrictPublicBuckets: true
IgnorePublicAcls: true
BlockPublicPolicy: true
BlockPublicAcls: true
BucketName: "data-lakehouse-raw-[REDACTED]"
OwnershipControls:
Rules:
- ObjectOwnership: "BucketOwnerEnforced"
BucketEncryption:
ServerSideEncryptionConfiguration:
- BucketKeyEnabled: true
ServerSideEncryptionByDefault:
SSEAlgorithm: "AES256"Finally, my EventBridge Schedule including the cron expression, IAM role and schedule name:
SchedulerSchedule00daily0700006qr2E:
UpdateReplacePolicy: "Retain"
Type: "AWS::Scheduler::Schedule"
DeletionPolicy: "Retain"
Properties:
GroupName: "default"
ScheduleExpression: "cron(0 7 * * ? *)"
Target:
Arn:
Fn::GetAtt:
- "LambdaFunction00datawordpressapiraw006Ybdu"
- "Arn"
RetryPolicy:
MaximumEventAgeInSeconds: 86400
MaximumRetryAttempts: 3
RoleArn:
Fn::GetAtt:
- "IAMRole00AmazonEventBridgeSchedulerLAMBDA35d568499400iuCzM"
- "Arn"
Description: ""
State: "ENABLED"
FlexibleTimeWindow:
Mode: "OFF"
ScheduleExpressionTimezone: "Europe/London"
Name: "daily-0700"In this example, CloudFormation will get the Lambda function and IAM role ARNs after they are created to avoid any EventBridge stack failures.
So everything’s fine, yes? Well…
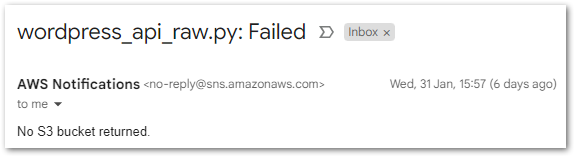
Errors
Alongside the template, the Template Definition tab threw this warning:
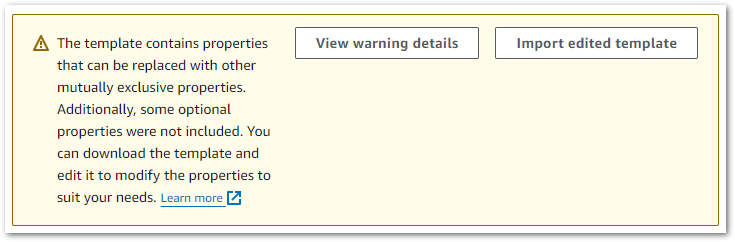
Uh, ok.
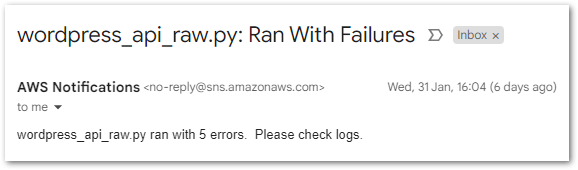
I was a bit thrown by this one so started investigating. View Warning Details had a lot to say, raising these Lambda issues:
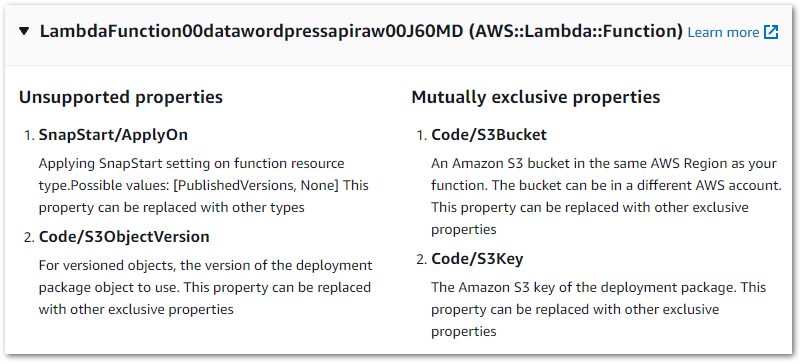
The warning’s Learn More link leads to IaC Generator and write-only properties. This, along with the accompanying page about updating AWS::Lambda::Function resources started to fill in the blanks:
The IaC Generator cannot determine which set of exclusive properties was applied to the resource during creation. For example, you can provide the code for a
AWS::Lambda::Functionusing one of these sets of properties.https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/generate-IaC-write-only-properties.html
Code/S3Bucket,Code/S3Key, and optionallyCode/S3ObjectVersionCode/ImageUriCode/ZipFile
The generator doesn’t know how the function code was provided, and can’t guess. So these warnings are included by design to stop IaC Generator from using the wrong function code:
When a generated template contains
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/generate-IaC-lambda-function.htmlAWS::Lambda::Functionresources, then warnings are generated stating thatCode/S3BucketandCode/S3Keyproperties are identified asMUTUALLY_EXCLUSIVE_PROPERTIES. In addition, theCode/S3ObjectVersionproperty receives aUNSUPPORTED_PROPERTIESwarning.
So what’s in the template’s Lambda code block exactly?
Lambda Function
This part of the template is my Lambda function:
LambdaFunction00datawordpressapiraw006Ybdu:
UpdateReplacePolicy: "Retain"
Type: "AWS::Lambda::Function"
DeletionPolicy: "Retain"
Properties:
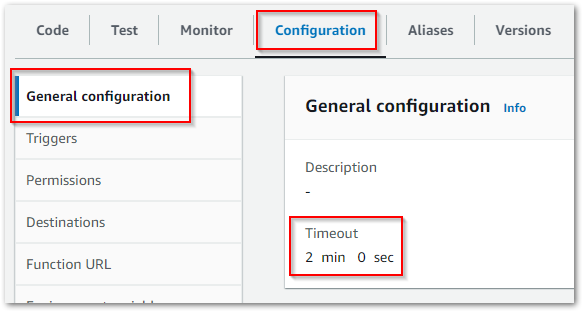
MemorySize: 250
Description: ""
TracingConfig:
Mode: "PassThrough"
Timeout: 120
RuntimeManagementConfig:
UpdateRuntimeOn: "Auto"
Handler: "lambda_function.lambda_handler"
Code:
S3Bucket:
Ref: "LambdaFunction00datawordpressapiraw006YbduCodeS3BucketOneOfmPyvF"
S3Key:
Ref: "LambdaFunction00datawordpressapiraw006YbduCodeS3KeyOneOfLqj3f"
Role:
Fn::GetAtt:
- "IAMRole00datawordpressapirawroleygxg4wz400zzf3d"
- "Arn"
FileSystemConfigs: []
FunctionName: "data_wordpressapi_raw"
Runtime: "python3.12"
PackageType: "Zip"
LoggingConfig:
LogFormat: "Text"
LogGroup: "/aws/lambda/data_wordpressapi_raw"
EphemeralStorage:
Size: 512
Architectures:
- "x86_64"Some items of note:
- Function name and CloudWatch Log Group:
Role:
Fn::GetAtt:
- "IAMRole00datawordpressapirawroleygxg4wz400zzf3d"
- "Arn"
FileSystemConfigs: []
FunctionName: "data_wordpressapi_raw"
Runtime: "python3.12"
PackageType: "Zip"
LoggingConfig:
LogFormat: "Text"
LogGroup: "/aws/lambda/data_wordpressapi_raw"
EphemeralStorage:
Size: 512
Architectures:
- "x86_64"- Memory allocation and timeout config settings:
LambdaFunction00datawordpressapiraw006Ybdu:
UpdateReplacePolicy: "Retain"
Type: "AWS::Lambda::Function"
DeletionPolicy: "Retain"
Properties:
MemorySize: 250
Description: ""
TracingConfig:
Mode: "PassThrough"
Timeout: 120
RuntimeManagementConfig:
UpdateRuntimeOn: "Auto"- Function runtime and instruction set architecture:
FileSystemConfigs: []
FunctionName: "data_wordpressapi_raw"
Runtime: "python3.12"
PackageType: "Zip"
LoggingConfig:
LogFormat: "Text"
LogGroup: "/aws/lambda/data_wordpressapi_raw"
EphemeralStorage:
Size: 512
Architectures:
- "x86_64"Now let’s focus on the parts causing the warnings – the function’s Code block:
RuntimeManagementConfig:
UpdateRuntimeOn: "Auto"
Handler: "lambda_function.lambda_handler"
Code:
S3Bucket:
Ref: "LambdaFunction00datawordpressapiraw006YbduCodeS3BucketOneOfmPyvF"
S3Key:
Ref: "LambdaFunction00datawordpressapiraw006YbduCodeS3KeyOneOfLqj3f"
Role:
Fn::GetAtt:
- "IAMRole00datawordpressapirawroleygxg4wz400zzf3d"
- "Arn"Those don’t look like any S3 resources in my account, so what are they? To begin to answer that question, let’s take a look at one of Bytescale’s example CloudFormation Lambda templates:
Code:
S3Bucket: my-lambda-function-code
S3Key: MyBundledLambdaFunctionCode.zipThis is simple to break down, with a clear bucket name and object key. The big difference is the lack of Ref in the sample code block. So what’s it doing in my template?
CloudFormation’s Ref is an intrinsic function that returns the value of a specified parameter or resource. Here, both Ref functions point to CloudFormation Parameters defined earlier in the template:
Parameters:
LambdaFunction00datawordpressapiraw006YbduCodeS3KeyOneOfLqj3f:
NoEcho: "true"
Type: "String"
Description: "The Amazon S3 key of the deployment package.\nThis property can\
\ be replaced with other exclusive properties"
LambdaFunction00datawordpressapiraw006YbduCodeS3BucketOneOfmPyvF:
NoEcho: "true"
Type: "String"
Description: "An Amazon S3 bucket in the same AWS-Region as your function. The\
\ bucket can be in a different AWS-account.\nThis property can be replaced with\
\ other exclusive properties"Now we’re getting somewhere! These parameters clearly reference an S3 key and an S3 bucket.
When this template is imported into a stack, CloudFormation will use these parameters to request the function code’s S3 location. The parameter values will then be passed to the Lambda code block when creating the function. The template can be manually updated with these values, but I’ll use the template as-is to see how the standard process unfolds.
This is a good time to talk about IaC Generator’s other limitations.
Limitations
CloudFormation has several operations, not all of which support every AWS resource. These operations are:
- IaC Generator.
- Resource Import: bringing resources into existing stacks.
- Drift detection: finding differences between a stack’s expected and actual configurations.
The AWS CloudFormation User Guide has a table of operations supported by resource types. This is a substantial table, so let’s focus on my template’s resources.
Firstly, there’s currently no IaC Generator support for the AWS::Lambda::EventInvokeConfig resource that handles Lambda Destinations. My template will deploy the Destination SNS topic, but will not configure the destination’s parameters.
Additionally, IaC Generator doesn’t currently support the AWS::SSM::Parameter resource. This is great from a security angle (no plain text credentials!) but adds an important manual step when using the stack.
Everything else is fully supported, so let’s try using the template.
Testing
In this section, I import the template from my IaC Generator Hands-On into a CloudFormation stack and see what happens.
CloudFormation Designer
A good way to check the template’s contents is to import it to CloudFormation Designer – an AWS tool for visually creating, viewing, and modifying CloudFormation templates.
This is Designer’s first diagram using IaC Generator’s template:
Eek!
Here, Designer is visualising all the CloudWatch resources. It looks fine on a big screen but isn’t great here, so I made a second template with no CloudWatch resources and imported that:
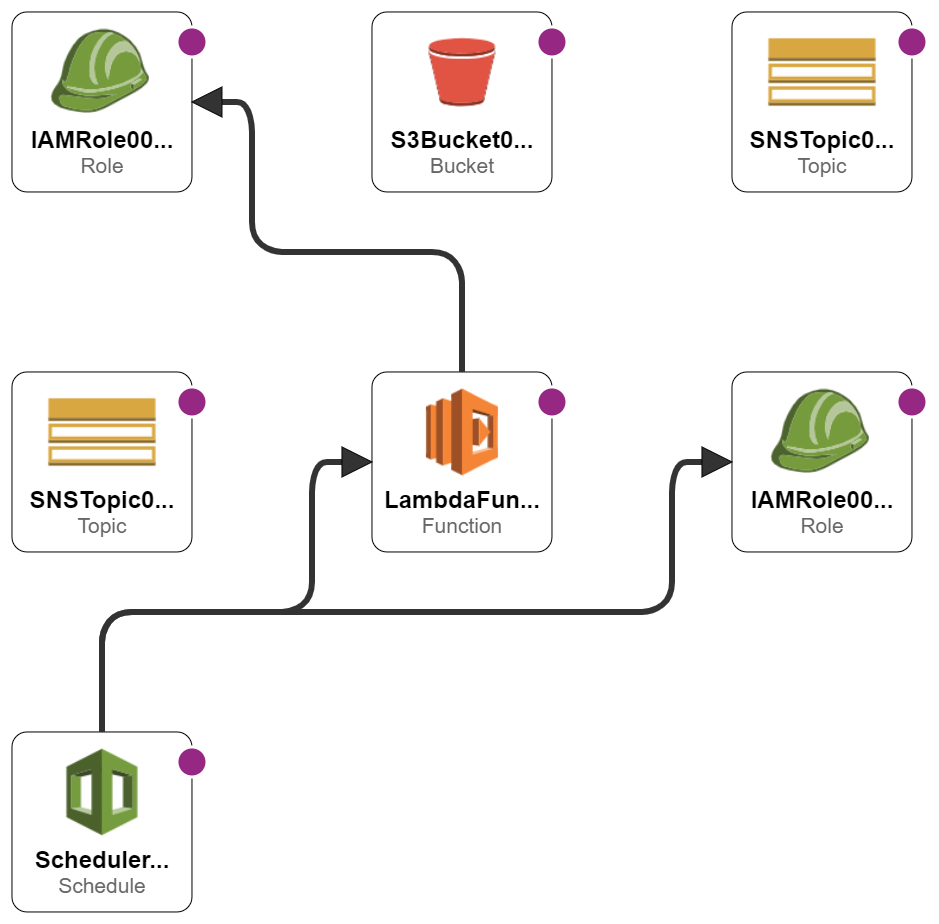
Much clearer! My EventBridge schedule and Lambda function are mapped to their respective IAM roles, and the SNS and S3 resources are present. As discussed, no Parameter Store resources or SNS destinations appear because these are not currently supported.
For comparison, here’s the AWS section of my pipeline’s architectural diagram:
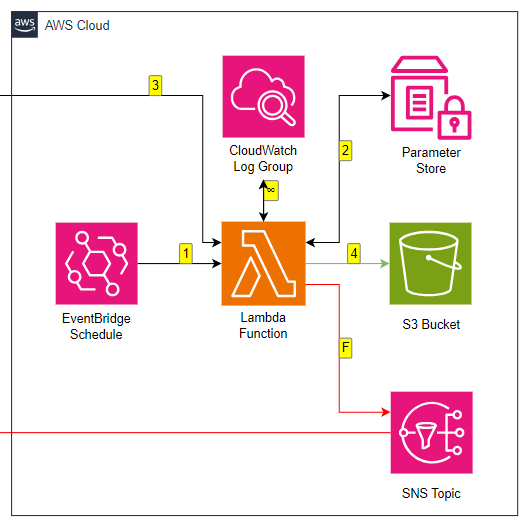
Now, I can add the missing resources to the generated template myself. However, because I want to see how the standard template behaves in testing I’ll be using it as-is.
Stack Import
A stack import is the process of transforming a template into a CloudFormation Stack. The stack is then used to provision AWS resources.
Stack imports are triggered in the IaC Generator’s Template Definition tab. After choosing the stack’s name, the Lambda parameters are requested:
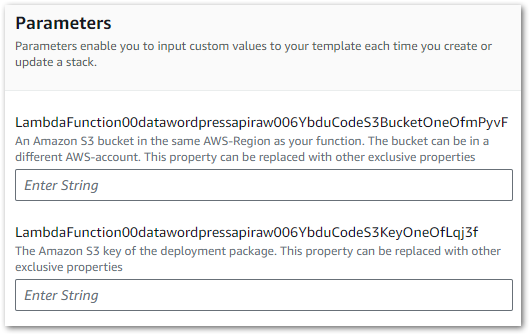
These values are then assigned to the Lambda code block’s S3Bucket and S3Key parameters.
Next, some basic admin. The stack needs an IAM role for all operations performed. IaC Generator then checks for any resource changes resulting from the stack’s creation. This is a completely new stack so this doesn’t apply.
With these details, CloudFormation starts creating the stack, which can then be deployed as usual.

Thoughts
So what do I think after my IaC Generator Hands-On? Well, there are some quality of life improvements that I think would make IaC Generator even more useful:
Direct Links To Scanned Resources
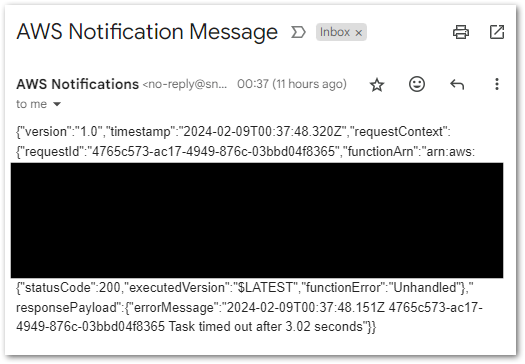
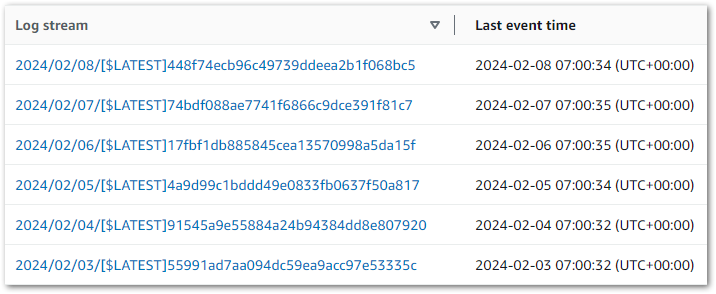
When browsing the scanned resources while making a template, I’d love to have direct links to the resources in the same way that I can see the EBS volumes attached to an EC2 instance and a Lambda function’s CloudWatch Log Stream.
While some resources have fairly friendly Resource Identifier names, others appear with names like aclassoc-0295235ac2e7c7e98 and rtb-0f28bd9a05e4ea696. Having a direct link to these resources from the selection screen would be massively helpful.
Simpler Errors
If IaC Generator is intended for people with little or no CloudFormation experience, then the Lambda and API Gateway warnings could be simpler.
I had some theoretical CloudFormation knowledge and have no qualms about reading documentation, so I got by. But users completely new to CloudFormation could easily see those warnings, assume they made a mistake and forget the whole thing.
Improved Reproducibility
When I deployed the template to my preferred region everything went fine. But when I tried to deploy it in a different AWS region it failed and threw CREATE_FAILED errors:
Resource handler returned message: "Resource of type 'AWS::SNS::Topic' with identifier 'data-lakehouse-raw' already exists." (RequestToken: e71fe163-af5e-bc59-4fd3-95dce19c9494, HandlerErrorCode: AlreadyExists)Resource handler returned message: "Resource of type 'AWS::SNS::Topic' with identifier 'lambda-general-failure' already exists." (RequestToken: f6e9722f-0f01-8c54-353a-cf62f4f266f4, HandlerErrorCode: AlreadyExists)For now, this can be resolved by using the generator’s template as a starting point for further templates. However, generating templates that can be immediately deployed in other regions would be very helpful.
Fewer Missing Resources
Finally, it would be good to see fewer missing resource types over time. Some of them will present AWS with some challenges, but hopefully others are just a matter of dev time.
For example, Lambda Destinations are already on the automated AWS SAM templates that can be generated from the Lambda console:
#***# indicates that sections have been removed.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
datawordpressapiraw:
Type: AWS::Serverless::Function
Properties:
#***#
EventInvokeConfig:
DestinationConfig:
OnFailure:
Destination: arn:aws:sns:eu-west-1:REDACTED:lambda-general-failure
Type: SNS
MaximumEventAgeInSeconds: 21600
MaximumRetryAttempts: 0
#***#Summary
In this post, I had a hands-on with AWS CloudFormation’s new IaC Generator feature. I think it’s really impressive! It makes CloudFormation more accessible than it was before, and I’m excited to see how it develops over time.
If this post has been useful, the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~