In this post, I use AWS Step Functions variables and JSONata to create a simplified API data capture workflow with Lambda and DynamoDB.
Table of Contents
Introduction
I’ve become an AWS Step Functions convert in recent times. Back in 2020 when I first studied it for some AWS certifications, Step Functions defined workflows entirely in JSON, making it less approachable and often overlooked.
How times change! With 2021’s inclusion of a visual editor, Step Functions became far more accessible, helping it become a key tool in serverless application design. And in 2024 two major updates significantly enhanced Step Functions’ flexibility: JSONata support, which I recently explored, and built-in variables, which simplify state transitions and data management. This post focuses on the latter.
To demonstrate the power of Step Functions variables, I’ll walk through a practical example: fetching API data, verifying the response, and inserting it into DynamoDB. Firstly, I’ll examine the services and features I’ll use. Then I’ll create a state machine and examine each state’s use of variables. Finally, I’ll complete some test executions to ensure everything works as expected.
If a ‘simplified’ workflow seems hard to justify as a 20-minute read…that’s fair. But mastering Step Functions variables now can save hours of debugging and development in the long run! – Ed
Also, special thanks to AWS Community Builder Md. Mostafa Al Mahmud for generously providing AWS credits to support this and future posts!
Architecture
This section provides a top-level view of the architecture behind my simplified Step Functions variables workflow, highlighting the main AWS services involved in getting and processing API data. I’ll briefly cover the data being used, the role of Step Functions variables and the integration of DynamoDB within the workflow.
API Data
The data comes from a RESTful API that provides UK car details. The API needs both an authentication key and query parameters. Response data is provided in JSON.
The data used in this post is about my car. As some of it is sensitive, I will only use data that is already publicly available:
{
"make": "FORD",
"yearOfManufacture": 2014,
"engineCapacity": 1242,
"co2Emissions": 120,
"fuelType": "PETROL",
"markedForExport": false,
"colour": "GREY",
}There are several data types here. This will be important when writing to DynamoDB!
AWS Step Functions Variables
In my last post, I talked about JSONata in AWS Step Functions. This time let’s talk about Step Functions variables, which were introduced alongside JSONata in November 2024.
Step Functions variables offer a simple way to store and reuse data within a state machine, enabling dynamic workflows without complex transformations. They work well with both JSONata and JSONPath and are available at no extra cost in all AWS regions that support Step Functions.
Variables are set using Assign. They can be assigned static values for fixed values:
"Assign": {
"productName": "product1",
"count" : 42,
"available" : true
}As well as dynamic values for changing values. To dynamically set variables, Step Functions uses JSONata expressions within {% ... %}. The following example extracts productName and available from the state input using the JSONata $states reserved variable:
"Assign": {
"product": "{% $states.input.productName %}",
"available": "{% $states.input.available %}"
}Variables are then referenced using dollar signs ($), e.g. $productName.
There’s tonnes more to this. For details on name syntax, ASL integration and creating JSONPath variables, check the Step Functions Developer Guide variables section. Additionally, watch AWS Principal Developer Advocate Eric Johnson‘s related video:
With Step Functions variables handling data transformation and persistence, the next step is storing processed data efficiently. This is where Amazon DynamoDB comes in.
Amazon DynamoDB
DynamoDB is a fully managed NoSQL database built for high performance and seamless scalability. Its flexible, schema-less design makes it perfect for storing and retrieving JSON-like data with minimal overhead.
DynamoDB can automatically scale to manage millions of requests per second while maintaining low latency. It integrates seamlessly with AWS services like Lambda and API Gateway, providing built-in security, automated backups, and global replication to ensure reliability at any scale.
Popular use cases include:
- Serverless backends (paired with AWS Lambda/API Gateway) for API-driven apps.
- Real-time workloads like user sessions, shopping carts, or live leaderboards.
- High-velocity data streams from IoT devices or clickstream analytics.
Diagram
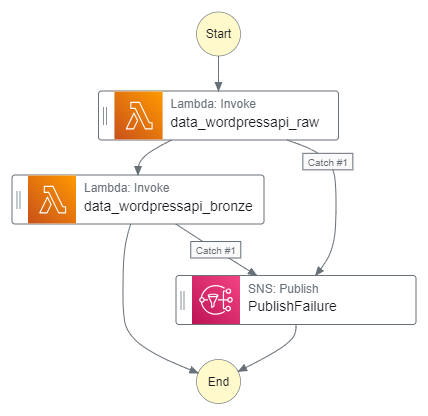
Finally, here is an architectural diagram of my simplified Step Functions variables workflow:
In which:
- The user triggers an AWS Step Functions state machine with a JSON key-value pair as input.
- A Lambda function is invoked with the input payload.
- The Lambda function sends a
POSTrequest to a third-party API. - The API server responds with JSON data.
- The Lambda function assigns Step Functions variables to store API response values and enters a
Choicestate that checks the API response code. - If the
Choicestate condition fails, SNS publishes a failure notification email. - The state machine terminates with an
ExecutionFailedstatus. - If the
Choicestate condition passes, the processed API response data is written to a DynamoDB table. - SNS publishes a success notification email.
- The state machine terminates with an
ExecutionSucceededstatus.
If an error occurs at any point in execution, SNS publishes a failure notification email and the state machine terminates with an ExecutionFailed status.
Resources
In this section, I create and configure my simplified Step Functions variables workflow resources, which are:
- AWS Lambda function
- AWS Step Functions Choice state
- Amazon DynamoDB table
- Amazon SNS topic
AWS Lambda
This section details how I created an AWS Lambda function to interact with a REST API. The function makes a secure POST request, manages potential errors and parses the response for use in downstream states. Additionally, I will discuss an issue I encountered while attempting to create variables from the function’s output using JSONata.
Lambda Function
First, I need to write a function. It’s nothing special – I have the API link and security key I need, and I just want to retrieve some data. So I decided to give Amazon Q Developer a try!
I used this prompt:
I have an HTTPS hyperlink for a REST API and an API key. I want to send a POST request to the API using the key. I have a USERID parameter that I will pass as JSON.
Please write a Python function for AWS Lambda with error handling. Please use security best practises and Pythonic standards.
Yes I do say Please in my prompts.
Amazon Q produced a decent script with:
- API endpoint and key stored as environment variables.
- Use of the
requestsmodule with a timeout to prevent indefinite hangs. - Error handling for request failures, validation errors, and unexpected issues.
- A structured JSON response including the status code and parsed response.
import json
import os
import logging
import requests
from typing import Dict, Any
from botocore.exceptions import ClientError
# Configure logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
"""
AWS Lambda function to make POST request to API endpoint
Args:
event: Lambda event object containing request data
context: Lambda context object
Returns:
API response as dictionary
"""
try:
# Get API endpoint and key from environment variables
api_endpoint = os.environ['API_ENDPOINT']
api_key = os.environ['API_KEY']
# Extract user ID from event
user_id = event.get('userId')
if not user_id:
raise ValueError("userId is required in the request")
# Set request headers
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}
# Prepare request payload
payload = {
'userId': user_id
}
# Make POST request
response = requests.post(
api_endpoint,
headers=headers,
json=payload,
timeout=30 # Set timeout for the request
)
# Raise exception for bad status codes
response.raise_for_status()
return {
'statusCode': response.status_code,
'body': response.json()
}
except requests.exceptions.RequestException as e:
logger.error(f"API request failed: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({'error': 'Failed to make API request'})
}
except ValueError as e:
logger.error(f"Validation error: {str(e)}")
return {
'statusCode': 400,
'body': json.dumps({'error': str(e)})
}
except Exception as e:
logger.error(f"Unexpected error: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({'error': 'Internal server error'})
}It needed some tweaks for my purposes, but was still faster than typing it all out manually!
Step Functions Config
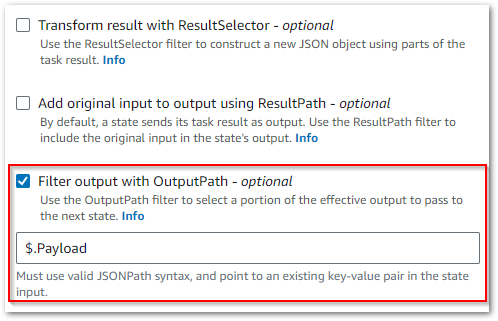
The Lambda: Invoke action defaults to using the state input as the payload, so "Payload": "{% $states.input %}" is scripted automatically:
"Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Output": "{% $states.result.Payload %}",
"Arguments": {
"FunctionName": "[LAMBDA_ARN]:$LATEST",
"Payload": "{% $states.input %}"
},
"Next": "Check API Status Code"
}This is going to be helpful in the next section!
Step Functions manages retries and error handling. If my Lambda function fails, it will retry up to three times with exponential backoff before sending a failure notification through SNS:
"Lambda Invoke": {
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"Next": "Check API Status Code",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "SNS Publish: Fail"
}
]
}Next, let’s talk about the function’s outputs.
Outputs & JSONata Variables
The Lambda function returns a nested JSON structure. Here’s a redacted example of it:
{
"output": {
"ExecutedVersion": "$LATEST",
"Payload": {
"statusCode": 200,
"body": {
"make": "FORD",
"yearOfManufacture": 2014,
"engineCapacity": 1242,
"co2Emissions": 120,
"fuelType": "PETROL",
"markedForExport": false,
"colour": "GREY"
}
},
"SdkHttpMetadata": {
"AllHttpHeaders": {
"REDACTED": "REDACTED"
},
"HttpHeaders": {
"REDACTED": "REDACTED"
},
"HttpStatusCode": 200
},
"SdkResponseMetadata": {
"REDACTED": "REDACTED"
},
"StatusCode": 200
}
}I mentioned earlier about Lambda: Invoke‘s default Payload setting. This default creates a {% $states.result.Payload %} JSONata expression output that I can use to assign variables for downstream states.
In this example, {% $states.result.Payload %} returns this:
{
"Payload": {
"statusCode": 200,
"body": {
"make": "FORD",
"yearOfManufacture": 2014,
"engineCapacity": 1242,
"co2Emissions": 120,
"fuelType": "PETROL",
"markedForExport": false,
"colour": "GREY"
}
}
}Let’s make a variable for statusCode. In the response, statusCode is a property of Payload:
{
"Payload": {
"statusCode": 200
}
}In JSONata this is expressed as {% $states.result.Payload.statusCode %}. Then I can assign the JSONata expression to a statusCode variable via JSON. In the AWS console, I do this via:
{
"statusCode": "{% $states.result.Payload.statusCode %}"
}And in Step Functions ASL via:
"Assign": {"statusCode": "{% $states.result.Payload.statusCode %}"}I can then call this variable using $statusCode. Here, this will return 200.
Next, let’s make a make variable. This is slightly more involved as make is a property of body, which is itself a property of Payload:
{
"Payload": {
"body": {
"make": "FORD"
}
}
}So this time I need:
CONSOLE:
"make": "{% $states.result.Payload.body.make%}"
ASL:
"Assign": {"make": "{% $states.result.Payload.body.make%}"}And now $make will return "FORD".
So let’s do the other values:
"Assign": {
"statusCode": "{% $states.result.Payload.statusCode %}",
"make": "{% $states.result.Payload.body.make%}",
"yearOfManufacture": "{% $string($states.result.Payload.body.yearOfManufacture) %}",
"engineCapacity": "{% $string($states.result.Payload.body.engineCapacity) %}",
"co2Emissions": "{% $string($states.result.Payload.body.co2Emissions) %}",
"fuelType": "{% $states.result.Payload.body.fuelType %}",
"markedForExport": "{% $states.result.Payload.body.markedForExport%}",
"colour": "{% $states.result.Payload.body.colour%}"
}Note that variables returning numbers from the response body like yearOfManufacture have an additional $string JSONata expression. I’ll explain the reason for this in the DynamoDB section.
Lambda Issues
When I first started using Step Functions variables, I used a different Lambda function for the API call and kept getting this error:
An error occurred.
The JSONata expression '$states.input.body.make' specified for the field 'Assign/make' returned nothing (undefined).After getting myself confused, I checked the function’s return statement and found this:
return {
'statusCode': response.status_code,
'body': response.text
}Here, response.text returns the response body as a JSON-formatted string rather than as a nested dictionary:
{
"statusCode": 200,
"body": "{\"make\":\"FORD\",\"yearOfManufacture\":2014,\"engineCapacity\":1242,\"co2Emissions\":120,\"fuelType\":\"PETROL\",\"markedForExport\":false,\"colour\":\"GREY\"}"
}That string isn’t compatible with dot notation. So while $states.input.body will match the whole body, $states.input.body.make can’t match anything because the string can’t be traversed. So nothing is returned, causing the error.
Using response.json() fixes this, as the response is now correctly structured for JSONata expressions:
return {
'statusCode': response.status_code,
'body': response.json()
}Choice State
The Choice state here is very similar to a previous one. This Choice state checks the Lambda function’s API response and routes accordingly.
Here, the Choice state uses the JSONata expression {% $statusCode = 200 %} to check the $statusCode variable value. By default, it will transition to the SNS Publish: Fail state. However, if $statusCode equals 200, then the Choice state will transition to the DynamoDB PutItem state instead:
"Check API Status Code": {
"Type": "Choice",
"Choices": [
{
"Next": "DynamoDB PutItem",
"Condition": "{% $statusCode = 200 %}"
}
],
"Default": "SNS Publish: Fail"
}This step prevents silent failures by ensuring unsuccessful API responses trigger an SNS notification instead of proceeding to DynamoDB. It also helps maintain data integrity by isolating success and failure paths, and ensuring only valid responses are saved in DynamoDB.
So now I’ve captured the data and confirmed its integrity. Next, let’s store it somewhere!
Amazon DynamoDB
It’s time to think about storing the API data. Enter DynamoDB! This section covers creating a table, writing data and integrating DynamoDB with AWS Step Functions and JSONata. I’ll share key lessons learned, especially about handling data types correctly.
Let’s start by creating a table.
Creating A Table
Before inserting data into DynamoDB, I need to create a table. Since DynamoDB is a schemaless database, all that is required to create a new table is a table name and a primary key. Naming the table is straightforward, so let’s focus on the key.
DynamoDB has two types of key:
- Partition key (required): Part of the table’s primary key. It’s a hash value that is used to retrieve items from the table and allocate data across hosts for scalability and availability.
- Sort key (optional): The second part of a table’s primary key. The sort key enables sorting or searching among all items sharing the same partition key.
Let’s look at an example using a Login table. In this table, the user ID serves as the partition key, while the login date acts as the sort key. This structure enables efficient lookups and sorting, allowing quick retrieval of a user’s login history while minimizing operational overhead.
To use a physical analogy, consider the DynamoDB table as a filing cabinet, the Partition key as a drawer, and the Sort key as a folder. If I wanted to retrieve User 123‘s logins for 2025, I would:
- Access the Logins filing cabinet (DynamoDB table).
- Find User 123’s drawer (Partition Key).
- Get User 123’s 2025 folder (Sort Key).
DynamoDB provides many features beyond those discussed here. For the latest features, please refer to the Amazon DynamoDB Developer Guide.
Writing Data
So now I have a table, how do I put data in it?
DynamoDB offers several ways to write data, and a common one is PutItem. This lets me insert or replace an item in my table. Here’s a basic example of adding a login event to a UserLogins table:
{
"TableName": "UserLogins",
"Item": {
"UserID": { "S": "123" },
"LoginDate": { "S": "2025-02-25T12:00:00Z" },
"Device": { "S": "Laptop" }
}
}Here:
TableNamespecifies the name of the DynamoDB table where the item will be stored.Itemrepresents the data being inserted into the table. It contains key-value pairs, where the attributes (e.g.UserID) are mapped to their corresponding data types (e.g."S") and values (e.g."123").UserIDis an attribute in the item being inserted."S"is a data type descriptor, ensuring that DynamoDB knows how to store and index it."123"is the value assigned to theUserIDattribute.
While DynamoDB is NoSQL, it still enforces strict data types and naming rules to ensure consistency. These are detailed in the DynamoDB Developer Guide, but here’s a quick rundown of supported data types as of March 2025:
S– StringN– NumberB– BinaryBOOL– BooleanNULL– NullM– MapL– ListSS– String SetNS– Number SetBS– Binary Set
Step Functions Config
So how do I apply this to Step Functions? Well, remember when I set variables in the output of the Lambda function? Step Functions lets me reference those variables here.
Here’s how I store a make attribute in DynamoDB, using my $make variable in a JSONata expression:
{
"TableName": "REDACTED",
"Item": {
"make": { "S": "{% $make %}" }
}
}This is equivalent to:
{
"TableName": "REDACTED",
"Item": {
"make": { "S": "FORD" }
}
}Using JSONata, I can dynamically inject values during execution instead of hardcoding them.
Now let’s add a yearOfManufacture attribute:
{
"TableName": "REDACTED",
"Item": {
"make": { "S": "{% $make %}" },
"yearOfManufacture": { "N": "{% $yearOfManufacture %}" }
}
}This pattern continues for my other attributes:
{
"TableName": "REDACTED",
"Item": {
"make": {
"S": "{% $make %}"
},
"yearOfManufacture": {
"N": "{% $yearOfManufacture%}"
},
"engineCapacity": {
"N": "{% $engineCapacity %}"
},
"co2Emissions": {
"N": "{% $co2Emissions%}"
},
"fuelType": {
"S": "{% $fuelType %}"
},
"markedForExport": {
"BOOL": "{% $markedForExport %}"
},
"colour": {
"S": "{% $colour %}"
}
}
}All this is then passed as an Argument to the DynamoDB: PutItem action in the state machine’s ASL:
"DynamoDB PutItem": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Arguments": {
"TableName": "REDACTED",
"Item": {
"make": {
"S": "{% $make %}"
},
"yearOfManufacture": {
"N": "{% $yearOfManufacture%}"
},
"engineCapacity": {
"N": "{% $engineCapacity %}"
},
"co2Emissions": {
"N": "{% $co2Emissions%}"
},
"fuelType": {
"S": "{% $fuelType %}"
},
"markedForExport": {
"BOOL": "{% $markedForExport %}"
},
"colour": {
"S": "{% $colour %}"
}
}
}Finally, DynamoDB:PutAction gets the same error handling as Lambda:Invoke.
So I got all this working first time, right? Well…
DynamoDB Issues
During my first attempts, I got this error:
An error occurred while executing the state 'DynamoDB PutItem'.
The Parameters '{"TableName":"REDACTED","Item":{"make":{"S":"FORD"},"yearOfManufacture":{"N":2014}}}' could not be used to start the Task:
[The value for the field 'N' must be a STRING]Ok. Not the first time I’ve seen data type problems. I’ll just change the yearOfManufacture data type to "S"(string) and try again…
An error occurred while executing the state 'DynamoDB PutItem'.
The Parameters '{"TableName":"REDACTED","Item":{"make":{"S":"FORD"},"yearOfManufacture":{"S":2014}}}' could not be used to start the Task:
[The value for the field 'S' must be a STRING]DynamoDB rejected both approaches (╯°□°)╯︵ ┻━┻
The issue wasn’t the data type, but how it was formatted. DynamoDB treats numbers as strings in its JSON-like structure, so even when using numbers they must be wrapped in quotes.
In the case of yearOfManufacture, where I was providing 2014:
"yearOfManufacture": {"N": 2014}DynamoDB needed "2014":
"yearOfManufacture": {"N": "2014"}Thankfully, JSONata came to the rescue again! Remember the $string function from the Lambda section? Well, $string casts the given argument to a string!
So this:
"yearOfManufacture": "{% $states.result.Payload.body.yearOfManufacture %}"
> 2014Becomes this:
"yearOfManufacture": "{% $string($states.result.Payload.body.yearOfManufacture) %}"
> "2014"This solved the problem with no Lambda function changes or additional states!
Amazon SNS
After successfully writing data to DynamoDB, I want to include a confirmation step by sending a notification through Amazon SNS.
While this approach is not recommended for high-volume use cases because of potential costs and notification fatigue, it can be helpful for testing, monitoring, and debugging. Additionally, it offers an opportunity to reuse variables from previous states and dynamically format a message using JSONata.
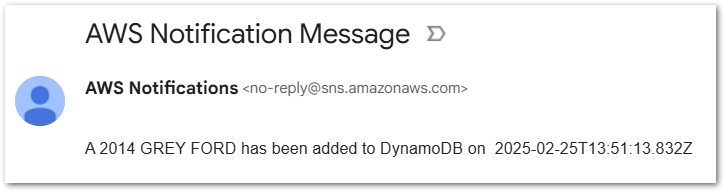
The goal is to send an email notification like this:
A 2014 GREY FORD has been added to DynamoDB on (current date and time)
To do this, I’ll use:
$yearOfManufacturefor the vehicle’s year (2014)$colourfor the vehicle’s colour (GREY)$makefor the manufacturer (FORD)
Plus the JSONata $now() function for the current date and time. This generates a UTC timestamp in ISO 8601-compatible format and returns it as a string. E.g. "2025-02-25T19:12:59.152Z"
So the code will look something like:
A
$yearOfManufacture$colour$makehas been added to DynamoDB on$now()
Which translates to this JSONata expression:
{% 'A ' & $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}Let’s analyse each part of the JSONata expression to understand how it builds the final message:
{%
'A '
&
$yearOfManufacture
&
' '
&
$colour
&
' '
&
$make
&
' has been added to DynamoDB on '
&
$now()
%}"Each part of this expression plays a specific role:
- ‘A ‘ | ‘ has been added to DynamoDB on ‘: Static strings & spaces.
$yearOfManufacture|$colour|$make: Dynamic values.$now(): JSONata function.- ‘ ‘: Static spaces to separate JSONata variable outputs.
The static spaces are important! Without them, I’d get this:
2014GREYFORD
Instead of the expected:
2014 GREY FORD
This JSONata expression is passed as the Message argument in the SNS:Publish action, ensuring the notification contains the correctly formatted message:
"Message": "{% 'A ' & $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}"Finally, to integrate this with Step Functions it is included in the SNS Publish: Success task ASL:
"SNS Publish: Success": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Arguments": {
"Message": "{% 'A ' & $yearOfManufacture & ' ' & $colour & ' ' & $make & ' has been added to DynamoDB on ' & $now() %}",
"TopicArn": "arn:aws:sns:REDACTED:success-stepfunction"
}Final Workflow
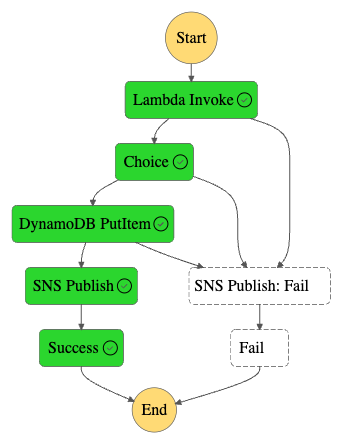
Finally, let’s see what the workflows look like. Here’s the workflow graph:
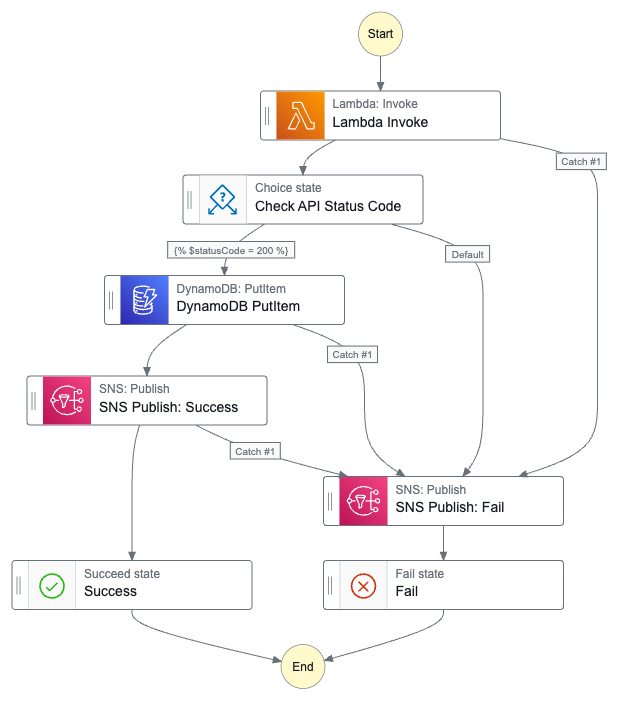
And here’s the workflow ASL on GitHub.
Testing
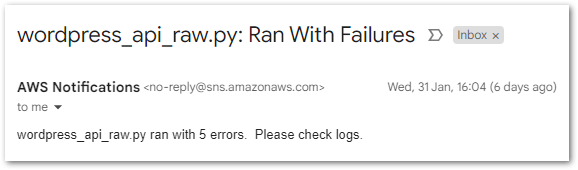
In this section, I run some test executions against my simplified Step Functions workflow and check the variables. I’ll test four requests – two valid and two invalid.
Valid Request: Ford
Firstly, what happens when a valid API request is made and everything works as expected?
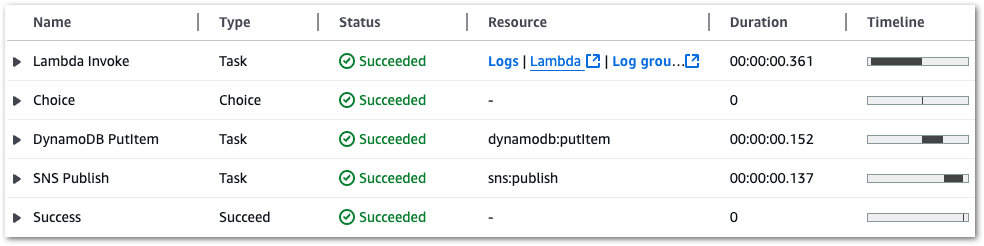
The Step Functions execution succeeds:
Each state completes successfully:
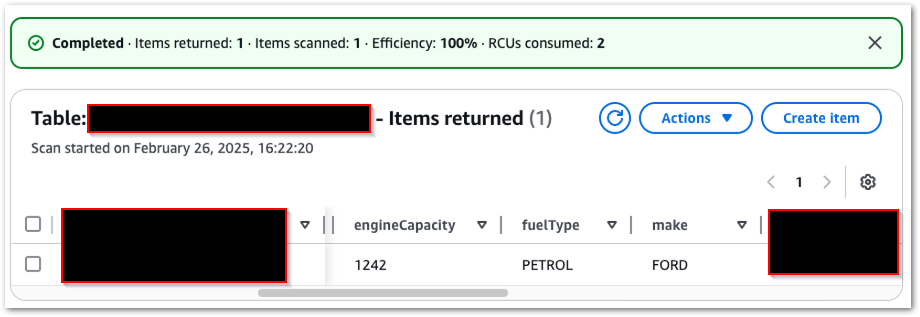
My DynamoDB table now contains one item:
I receive a confirmation email from SNS:
If I send the same request again, the existing DynamoDB item is overwritten because the primary key remains the same.
Valid Request: Audi
Next, what happens if I make a valid request for a different car? The steps repeat as above, and my DynamoDB table now has two items:
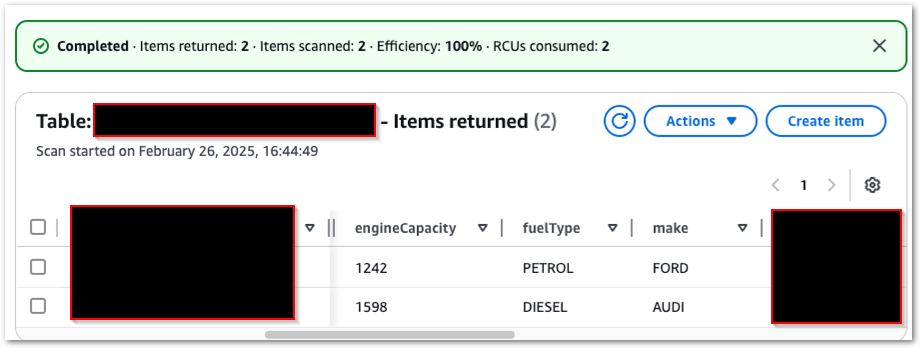
And I get a different email:
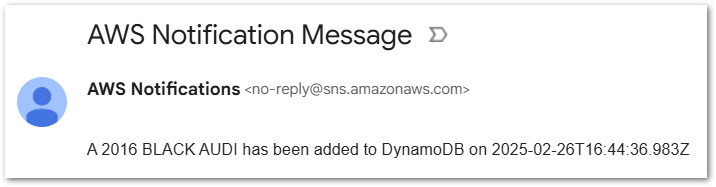
Invalid Request
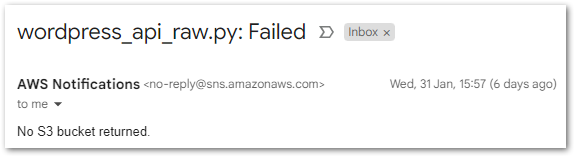
Next, what happens if the car in my request doesn’t exist? Well, it does fail, but in an unexpected way:
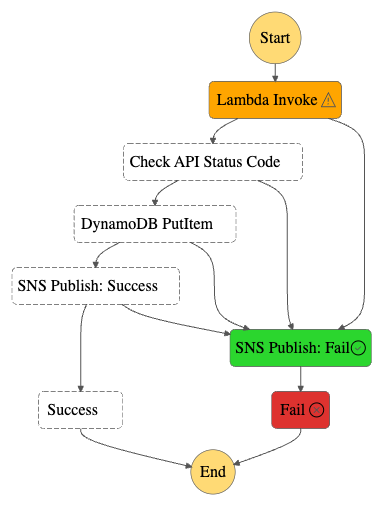
The API returns an error response:
"Payload": {
"statusCode": 500,
"body": "{\"error\": \"API request failed: 400 Client Error: Bad Request for url"}"
}I’d expected the response to be passed to the Choice state, which would then notice the 500 status code and start the Fail process. But this happened instead:
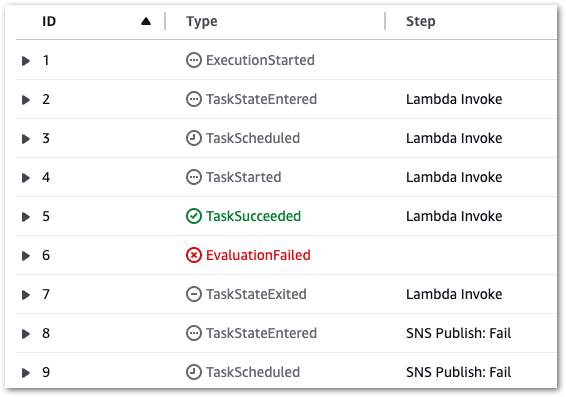
The failure occurs at the assignment of the Lambda action variable! It attempts to assign a yearOfManufacture value from the API response body to a variable, but since there is no response body the assignment fails:
{
"cause": "An error occurred while executing the state 'Lambda Invoke' (entered at the event id #2). The JSONata expression '$states.result.Payload.body.yearOfManufacture ' specified for the field 'Assign/yearOfManufacture ' returned nothing (undefined).",
"error": "States.QueryEvaluationError",
"location": "Assign/registrationNumber",
"state": "Lambda Invoke"
}I also get an email, but this one is less fancy as it just dumps the whole output:

So I still get my Fail outcome – just not in the expected way. Despite this, the Choice state remains valuable for preventing invalid data from entering DynamoDB.
No Request
Finally, what happens if no data is passed to the state machine at all?
Actually, this situation is very similar to the invalid request! There’s a different error message in the log:
"Payload": {
"statusCode": 400,
"body": "{\"error\": \"Registration number not provided\"}"
}But otherwise it’s the same events and outcome. The Lambda variable assignment fails, triggering an SNS email and an ExecutionFailed result.
Cost Analysis
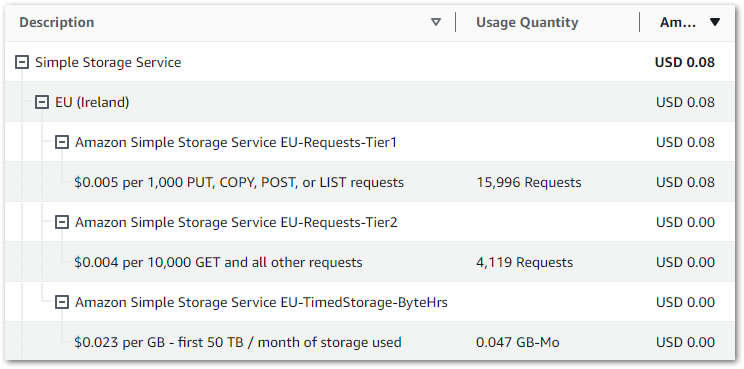
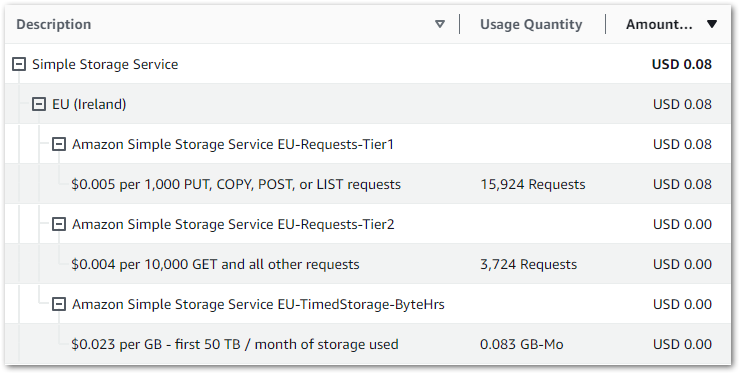
This section examines the costs of my simplified Step Functions variables workflow. This section is brief since all services used in this workflow fall within the AWS Free Tier! For transparency, I’ll include my billing metrics for the month. These are account-wide, and I’m still nowhere near paying AWS anything!
DynamoDB:
| $0.1415 per million read request units (EU (Ireland)) | 30.5 ReadRequestUnits |
| $0.705 per million write request units (EU (Ireland)) | 13 WriteRequestUnits |
Lambda:
| AWS Lambda – Compute Free Tier – 400,000 GB-Seconds – EU (Ireland) | 76.219 Second |
| AWS Lambda – Requests Free Tier – 1,000,000 Requests – EU (Ireland) | 110 Request |
SNS:
| First 1,000 Amazon SNS Email/Email-JSON Notifications per month are free | 19 Notifications |
| First 1,000,000 Amazon SNS API Requests per month are free | 289 Requests |
Step Functions:
| $0 for first 4,000 state transitions | 431 StateTransitions |
This experiment demonstrates how cost-effective Step Functions can be. As long as my usage remains within the Free Tier, I pay nothing! If my workflow grows, I’ll monitor costs and optimise accordingly.
Summary
In this post, I used AWS Step Functions variables and JSONata to create a simplified API data capture workflow with Lambda and DynamoDB.
With a background in SQL and Python, I’m no stranger to variables, and I love that they’re now a native part of Step Functions. AWS keeps enhancing Step Functions every few months, making it more powerful and versatile. The introduction of variables unlocks new possibilities for data manipulation, serverless applications and event-driven workflows, and I’m excited to explore them further in the coming months!
For a visual walkthrough of Step Functions variables and JSONata, check out this Serverless Office Hours episode with AWS Principal Developer Advocates Eric Johnson and Julian Wood:
If this post has been useful then the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~