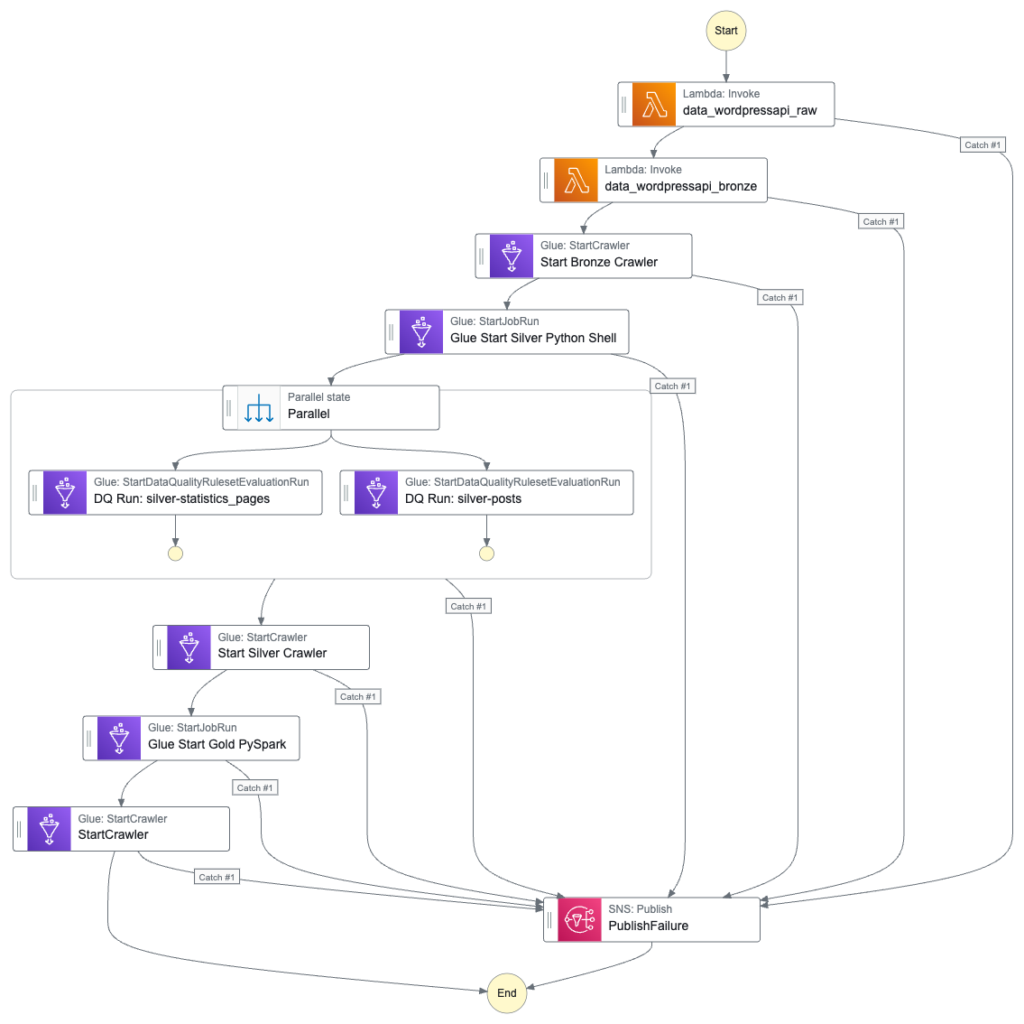
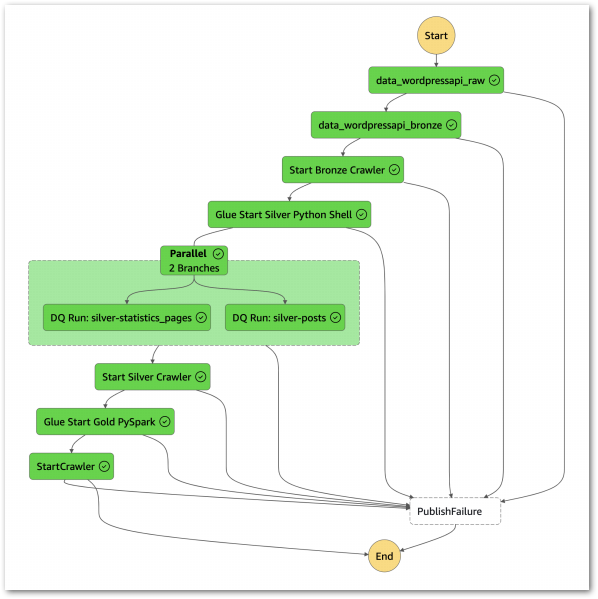
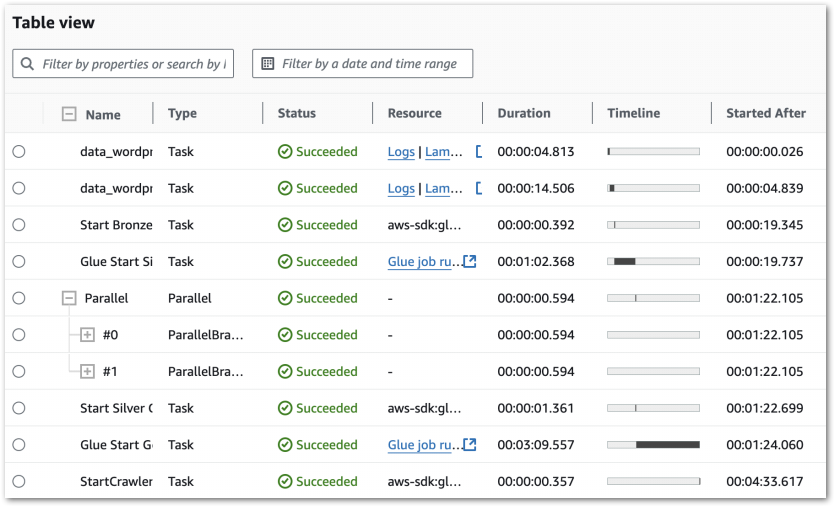
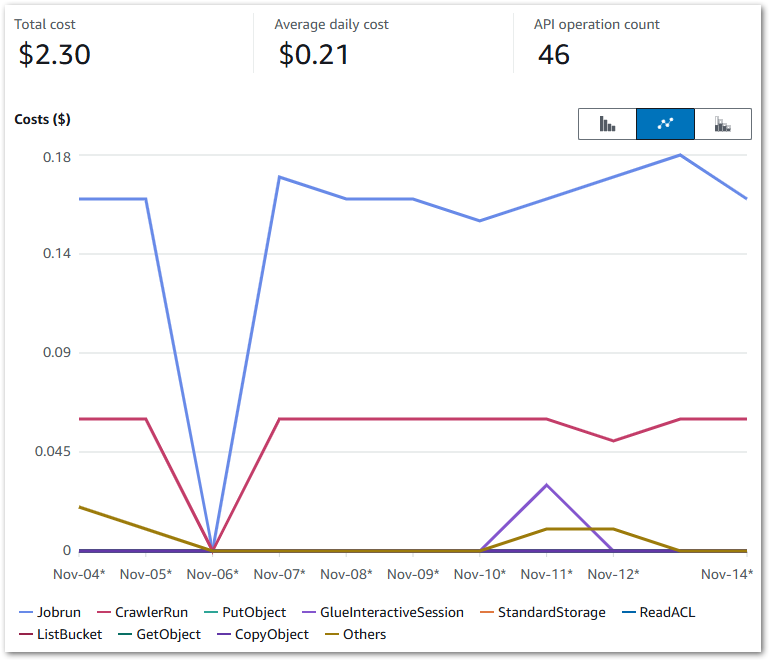
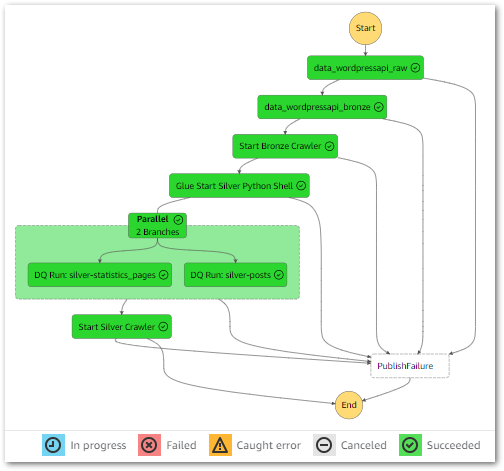
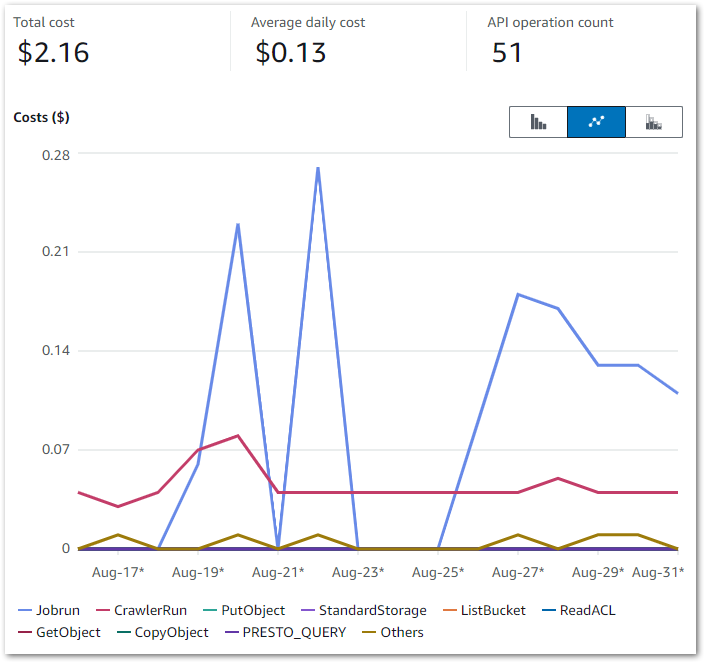
In this post, I use the free YearCompass booklet to reflect on 2024 and to plan some professional goals for 2025.
Table of Contents
Introduction
It’s time for the customary retrospective post! Previously, I’ve written these in December. From now on, I’ll post them on amazonwebshark’s birthday in January because:
- It gives me more time to consider my goals.
- If I’m going to write about a year, it makes more sense to write after the year is over.
- In previous years, I’ve felt personal pressure to produce both a December YearCompass post and a January birthday post. My YearCompass post can cover both of these instead.
Firstly, I’ll examine YearCompass itself. Next, I’ll discuss how 2024 went. Finally, I’ll examine my 2025 YearCompass goals.
About YearCompass
From the YearCompass site:
YearCompass is a free booklet that helps you reflect on the year and plan the next one. With a set of carefully selected questions and exercises, YearCompass helps you uncover your own patterns and design the ideal year for yourself.
YearCompass offers a free alternative to New Year’s Resolutions. Available as A4 and A5 PDFs in several languages, the booklet can be completed digitally or by hand.
YearCompass PDFs contain two sections: reflecting on the past year and planning for the next. Each section features prompts to help users assess priorities and prepare for the future.
There are no rigid guidelines for completing YearCompass. Although the book recommends taking breaks between sections, many people choose to complete it in one go. I often focus on specific sections rather than the entire document, as I usually have what I need by a certain point.
2024 Retrospective
In this section, I reflect on my 2024 goals and evaluate my progress with them.
Build Technology Projects
As a cloud enthusiast, I want to complete valuable project builds so that I can develop and validate my knowledge and skills, and have subject matter for future session abstracts.
Exiting 2023, I felt I had done much theory but little practice. I had completed online learning, attended events and recertified my AWS SysOps Administrator certification, yet I still felt lacking in hands-on experience.
Well no more! Throughout 2024, I worked on my WordPress AWS Data Pipeline series, which greatly enhanced my understanding of several AWS services and cloud architectures. Also, I explored the AWS CloudFormation IaC Generator and DuckDB-WASM in February and June respectively.
Separately, in July, I joined Steamhaus as an AWS Consultant, where I build, scale, and optimise cloud solutions for clients. This role involves unique projects spanning diverse organisations, requiring creative problem-solving and offering many opportunities to learn and grow. And 2025 is already shaping up to be an interesting year!
Additionally, I earned the AWS Certified Data Engineer – Associate certification in August, validating my skills in areas including ETL, orchestration, model design and quality assurance.

Learnings from this certification have already found their way into my blog posts, sessions and client projects.
And speaking of sessions…
Build My Personal Brand
As an IT professional I want to build my personal brand so that I improve my soft skills and define my public image.
And to think that, at the start of 2024, I had no idea how this was going to go…
Having done my first session at 2023’s New Stars Of Data online event, 2024 was the first year I stepped onto an actual stage! After presenting my Building And Automating Serverless Auto-Scaling Data Pipelines In AWS session at AWS Community Summit London in April, I went on to present it at several user groups, a paid event and even internationally!


This year, I also launched a YouTube channel, primarily intended to practise and enhance my speaking skills. Although the channel has been somewhat dormant, I’ve been kinda busy!
Recently, I began a series of shorts to boost my spontaneous speaking ability. It appears to be working for me, and there’s still plenty to film!
Finally, in September I met Cat Mawdsley and Dan Knowles at Northern Reach for the first time. Northern Reach focuses on providing technology and innovation-driven business engagement initiatives for partners in both the public and private sectors across Northern England.
I was born and raised in Lancashire, and quickly discovered their ambitious plans for the region. We got chatting, one thing led to another and, well, I’ll have some exciting news to share soon about something I’m part of!
Build A Second Brain
As just a normal man I want to build a second brain so that I can organise my resources and work more efficiently.
So this is the goal with the least progress, but only because the first two goals blew up beyond anything I could have envisaged! Having read Building A Second Brain in January, I started putting some of the ideas into practice.
Firstly, I’m a big fan of the CODE information consumption method:
- Capture
- Organise
- Distill
- Express
In some ways I was already doing this, but lacked a framework or set of steps to follow. I now use CODE in several areas of my life, and while it’s not yet fully embedded everywhere it is starting to make a difference.
However, I’m no fan of the PARA organisational system:
- Project
- Area
- Resource
- Archive
Tiago Forte and I define Project very differently, and I dislike using Archive to describe anything. Archive always feels like a nondescript collection of stuff, which is what a Second Brain should not be. Even Tiago defines Archive as:
Anything from the previous three categories that is no longer active, but you might want to save for future reference.
https://fortelabs.com/blog/para/
Nah. Not for me.
Ultimately, my Second Brain isn’t where I want it to be right now. But to be fair, a second brain is never really finished as it constantly grows and evolves like a human brain. In 2025, I’ll be examining some Second Brain-related AI and SaaS tools and might make some related content if I think it’ll be helpful.
2025 Goals
In this section, I use YearCompass to decide on my 2025 professional goals. For each goal, I’ll explain my reasoning and then write a user story.
Community Investment
I am deeply grateful for the tech communities that supported me throughout 2024. They offered me opportunities to learn, grow and connect with like-minded peers who share my passion for technology. I was invited to speak at several local and international events, and I strongly believe that my journey to Steamhaus began at AWS community events.

In 2025, I plan to build on these experiences by continuing to contribute through speaking engagements, writing, and social support, as well as giving operational user group support. In this way, I hope to strengthen and grow the communities that played such an integral role in my 2024 successes.
On a personal note, I look forward to continuing the growth journey that the communities have nurtured. This includes enhancing my confidence, refining interpersonal skills, strengthening relationships and expanding my experiences. Just like any solid investment – everyone benefits.
As an active tech community member, I want to support and grow these communities through content, involvement and participation so that both the communities and I thrive.
That said…
Gestalt Cycles
I did a lot in 2024, and looking back I didn’t allow much downtime. Feelings of ‘I should be doing something’ constantly ran into evenings, weekends, and annual leave, and I increasingly noticed disrupted sleep, diminished health and fitness and heightened anxiety as a result.
I’ve burned myself out before so I recognise the signs. And as keen as I am to continue on this unexpected, wild and incredible journey I’m currently on, I also don’t want to end up utterly cooked.
Turning this into a goal was hard as nothing really fit. The closest match I’ve found so far is Gestalt Cycles. This describes the natural rhythm of completing an experience, from identifying a need to achieving closure.
Each cycle involves several stages:

The idea focuses on completing each stage fully to maintain balance and well-being, avoiding lingering stress while creating space for rest and renewal. This aligns closely with what I need. My challenge hasn’t been starting or finishing tasks – it’s been allowing enough recovery time between them.
This aligns with Animas Coaching‘s Withdrawal stage definition:
Finally, after the satisfaction of the need or desire, individuals withdraw, returning to a state of relative equilibrium. This stage offers an opportunity for rest and reflection before the cycle recommences with a new sensation.
https://www.animascoaching.com/blog/gestalt-cycle-of-experience/
And with Shea Stevens‘ comments based on the works of Rosemarie Wulf et al:
…the goal is to find relief and meet needs in a way that they are assimilated, such that the organism is truly integrating what it takes in, and what is taken in is a good fit for the organism.
https://www.gestalttherapyblog.com/blog/gestalt-cycle
I have 2025 ambitions around fitness, home improvements and landscaping. To enable these, I’ll need to ease off the accelerator occasionally. So with all this in mind:
As an individual with multiple workstreams, I want to apply Gestalt cycles to recognize when a task is complete and take intentional breaks, so that I can improve my wellbeing and maintain consistent energy and focus.
Be The Change
Definitely the most LinkedIn-sounding of the three. But hear me out. This goal stems from Mahatma Gandhi’s quote:
Be the change you wish to see in the world.
Mahatma Gandhi…erm…
Expect that’s not what he said. But I digress.
“Be the change” is about taking personal responsibility to embody the values and actions you want to inspire in others. It emphasises proactivity and self-empowerment over simply waiting for change to happen.
Throughout my career, I’ve had ideas I wanted to share and a strong desire to contribute. However, I have constantly struggled with self-confidence, self-doubt and articulating my thoughts.
This changed in 2024. Through my professional role, speaking engagements and involvement in the AWS community, I gained the confidence and ability to express and implement my insights and ideas. This let me enhance my skills and uncover new opportunities, leading to beneficial outcomes for myself, my colleagues and clients and the wider tech community.

In 2025, I’m committed to embracing this newfound confidence to present and support ideas and changes that matter to me. By doing so, I hope to build stronger relationships, deliver impactful projects and advance initiatives that reflect my values and passions.
As a hard working dog dad, I want to confidently embrace and act on my ideas and opinions so that I can make meaningful contributions and changes to myself, my peers and clients and the wider tech community.
Summary
In this post, I used the free YearCompass booklet to reflect on 2024 and to plan some professional goals for 2025.
Reflecting on 2024 has highlighted key lessons and opportunities for growth, helping me shape an exciting vision for 2025. I’m eager to see where the new year leads and to share progress along the way! I’ll post updates here and via my social, project and session links, which are available via the button below:

Thanks for reading ~~^~~