In this post, I create my WordPress pipeline’s bronze data orchestration process using AWS Lambda layers and AWS Step Functions.
Table of Contents
- Introduction
- Architectural Decisions
- Architectural Updates
- Python
- Lambda
- Step Functions & EventBridge
- Costs
- Resources
- Summary
Introduction
In recent posts, I’ve written a Python script to extract WordPress API data and automated the script’s invocation with AWS services. This script creates five JSON objects in an S3 bucket at 07:00 each morning.
Now, I want to transform the data from semi-structured raw JSON into a more structured and query-friendly ‘bronze’ format to prepare it for downstream partitioning, cleansing and filtration.
Firstly, I’ll cover the additions and changes to my pipeline architecture. Next, I’ll examine both my new bronze Python function and the changes made to the existing raw function.
Finally, I’ll deploy the bronze script to AWS Lambda and create my WordPress pipeline orchestration process with AWS Step Functions. This process will ensure both Lambdas run in a set order each day.
Let’s start by examining my latest architectural decisions.
Architectural Decisions
In this section, I examine my architectural decisions for the bronze AWS Lambda function and the WordPress pipeline orchestration. Note that these decisions are in addition to my previous ones here and here.
AWS SDK For pandas
AWS SDK For pandas is an open-source Python initiative using the pandas library. It integrates with AWS services including Athena, Glue, Redshift, DynamoDB and S3, offering abstracted functions to execute various data processes.
AWS SDK For pandas used to be called awswrangler until AWS renamed it for clarity. It now exists as AWS SDK For pandas in documentation and awswrangler in code.
AWS Lambda Layers
A Lambda layer is an archive containing code like libraries, dependencies, or custom runtimes. Layers can be both created manually and provided by AWS and third parties. Each Lambda function can include up to five layers.
Layers can be shared between functions, reducing code duplication and package sizes. This reduces storage costs and lets the smaller packages deploy markedly faster. Layers also separate dependencies from function code, supporting decoupling and separation of concerns.
AWS Step Functions
AWS Step Functions is a serverless orchestration service that integrates with other AWS services to build application workflows as a series of event-driven steps. For example, chaining Athena queries and ML model training.
Central to the Step Functions service are the concepts of States and State Machines:
- States represent single steps or tasks in a workflow, and can be one of several types. The Step Functions Developer Guide has a full list of states.
- State Machines are workflows made up of states. They are defined using Amazon States Language (ASL) – a JSON-based structured language used to describe state machines declaratively and supported by the Amazon States Language Specification.
The AWS Step Functions Developer Guide’s welcome page has more details including workflow types, use cases and a variety of sample projects.
Apache Parquet
Onto the data architecture! Let’s start by choosing a structured file type for the bronze data:
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
Databricks: What is Parquet?
There’s a more detailed explanation in the Parquet documentation too. So why choose Parquet over something like CSV? Well:
- Size: Parquet supports highly efficient compression, so files take up less space and are cheaper to store than CSVs.
- Performance: Parquet files store metadata about the data they hold. Query engines can use this metadata to find only the data needed, whereas with CSVs the whole file must be read first. This reduces the amount of processed data and enhances query performance.
- Compatibility: Parquet is an open standard supported by various data processing frameworks including Apache Spark, Apache Hive and Presto. This means that data stored in Parquet format can be read and processed across many platforms and services.
Data Lakehouse
A Data Lakehouse is an emerging data architecture combining the centralized storage of raw data synonymous with Data Lakes with the transactional and analytical processing associated with Data Warehouses.
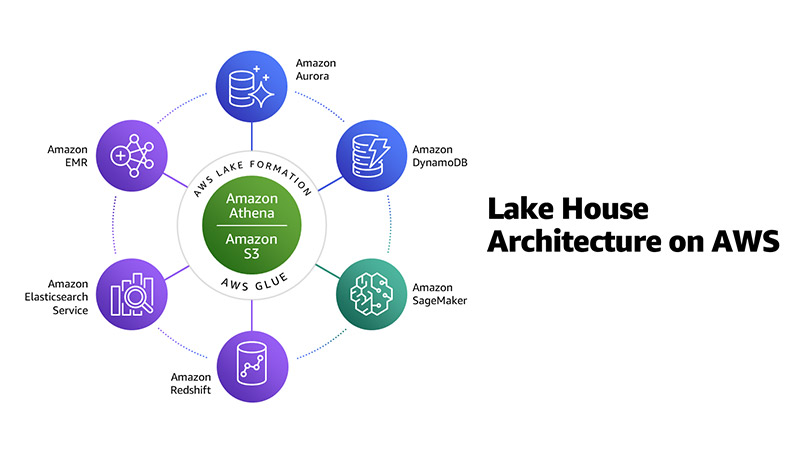
The result is a unified platform for efficient data management, analytics, and insights. Lakehouses have gained popularity as cloud services increasingly support them, with AWS, Azure and GCP all providing Lakehouse services.
This segues neatly into…
Medallion Architecture
A Medallion Architecture is a data design pattern for logically organizing data in a Lakehouse. It aims to improve data quality as it flows through various layers incrementally. Names for these layers vary, tending to be Bronze, Silver, and Gold.
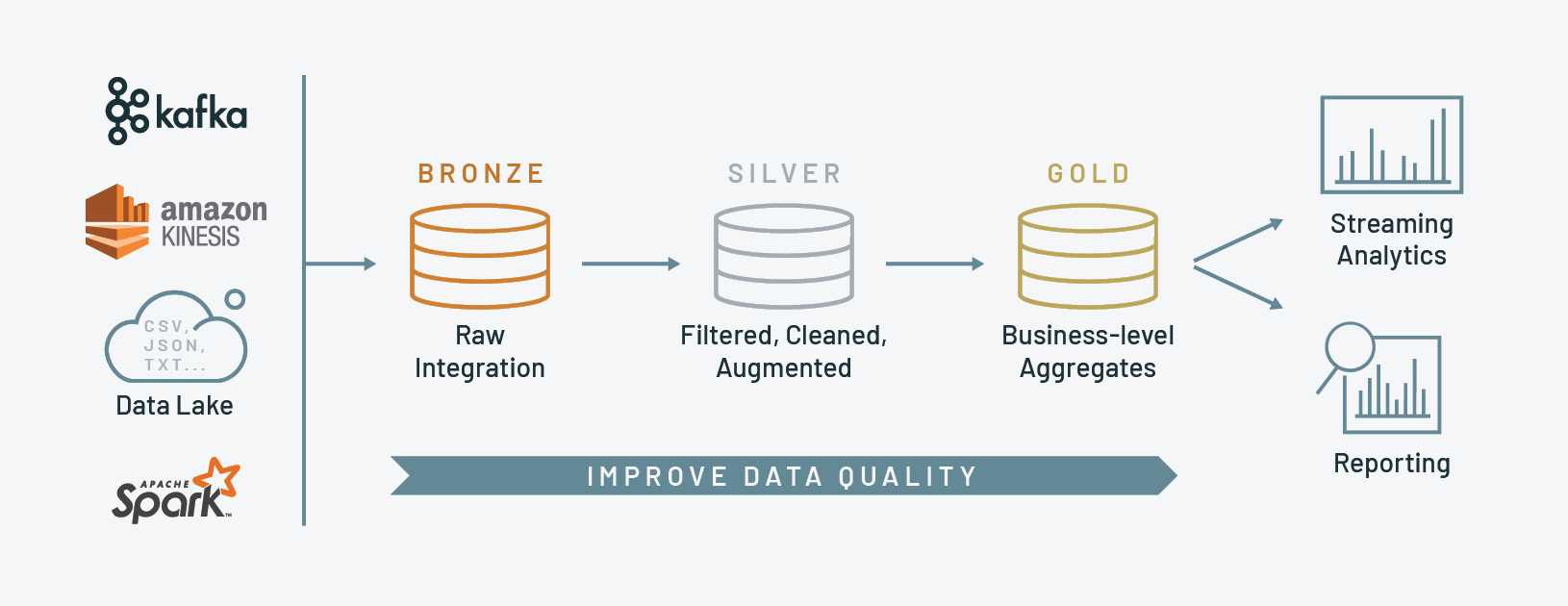
Implementations of the Medallion Architecture also vary. I like this Advancing Analytics video, which maps the Medallion Architecture to their approach. Despite the title it’s not a negative video, instead outlining how the three layers don’t necessarily fit every use case.
I’m using Raw and Bronze layers here because they best fit what I’m doing with my data.
Architectural Updates
In this section, I examine the changes made to my existing architecture.
Amazon S3
I’ve created a new data-lakehouse-bronze s3 bucket in the same region as the data-lakehouse-raw bucket to separate the two data layers.
Why use two buckets instead of one bucket with two prefixes? Well, after much research I’ve not found a right or wrong answer for this. There’s no difference in cost, performance or availability as long as all objects are stored in the same AWS region.
I chose two buckets because I find it easier to manage multiple buckets with flat structures and small bucket policies, as opposed to single buckets with deep structures and large bucket policies.
The truest answer is ‘it depends’, as other factors can come into play like:
- Data Sovereignty: S3 bucket prefixes exist in the same region as the parent bucket. Regulations like GDPR and CCPA may require using separate buckets in order to isolate data within designated locations.
- S3 Bucket Limits: AWS accounts have default limits of 100 buckets, rising to a maximum of 1000. If buckets are at a premium then prefixes are the way to go.
- S3 Feature Requirements: Buckets in different regions can have different feature sets. For example, Amazon S3 Express One Zone was limited to the US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Stockholm) regions at launch. Processes using this feature would require buckets in these regions.
AWS SNS
I previously had two standard SNS Topics:
wordpress-api-rawfor Lambda function alertsfailure-lambdafor Lambda Destination alerts.
Firstly, there’s now an additional failure-stepfunction topic for any state machine failures.
Secondly, I’ve replaced my wordpress-api-raw topic with a data-lakehouse-raw topic to simplify my alerting channels and allow resource reuse. I’ve also created a new data-lakehouse-bronze topic for bronze process alerts.
Why two data topics? Well, different teams and services care about different things. A bronze-level failure may only concern the Data Engineering team as no other teams consume the data. Conversely, a gold-level failure will concern the AI and MI teams as it impacts their models and reports. Having separate SNS topics for each layer type enables granular monitoring controls.
AWS Parameter Store
Finally, Parameter Store needs the new S3 bucket name and SNS ARNs. I’ve replaced the /sns/pipeline/wordpressapi/raw parameter with /sns/data/lakehouse/raw to preserve the name schema.
I’m now storing five parameters:
- 2x S3 Bucket names (Raw and Bronze)
- 2x SNS Topic ARNs (Raw and Bronze notifications)
- WordPress API Endpoints (unchanged)
Architectural Diagram
There are two diagrams this time! Firstly, here is the data_wordpressapi_bronze AWS Lambda function:

Where:
- AWS Lambda calls Parameter Store for S3 and SNS parameters. Parameter Store returns these to AWS Lambda.
- Lambda function gets raw WordPress JSON data from S3 Raw Bucket.
- Lambda function transforms the raw WordPress JSON data to bronze WordPress Parquet data and puts the new object in the S3 Bronze Bucket.
Meanwhile, Lambda is writing to a CloudWatch Log Group throughout its invocation. If there’s a failure, the Lambda function publishes a message to an SNS topic. SNS then delivers this message to the user’s subscribed email address.
Next, this is the AWS Step Functions WordPress bronze orchestration process:

Where:
- EventBridge Schedule invokes the State Machine.
- State Machine invokes the Raw Lambda function.
- State Machine invokes the Bronze Lambda function.
The State Machine also has its own logging and alerting channels.
Python
In this section, I work on my raw and bronze Python scripts for the WordPress pipeline orchestration process.
Raw Script Updates
I try to update my existing resources when I find something pertinent online. My latest find was this Indently video that covers, amongst other things, type annotations:
So how are type annotations different from type hints? Type annotations were released in 2006 and aimed to standardize function parameters and return value annotation. Type hints (released in 2014) then added updated definitions and conventions to enrich type annotations further.
The type hints PEP shows this difference between the two:
When used in a type hint, the expression
https://peps.python.org/pep-0484/#using-noneNoneis considered equivalent totype(None)
So in this function:
def send_email(name: str, message: str) -> None:name: stris an example of type annotation because the parameternameis of type string.-> Noneis an example of a type hint because althoughNoneisn’t a type, it confirms that the function has no output.
So what’s changed in my raw script?
Updated Import & Functions
Let’s open with a new import:
from botocore.client import BaseClientBaseClient serves as a foundational base class for AWS service clients within botocore – a low-level library providing the core functionality of boto3 (the AWS Python SDK) and the AWS CLI.
I’m using it here to add type annotations to my boto3 clients. For example, send_sns_message already had these annotations:
def send_sns_message(sns_client, topic_arn: str, subject:str, message: str):I’ve now annotated sns_client with BaseClient to indicate its boto3 relation. I’ve also added a -> None type hint to confirm the function has no output:
def send_sns_message(sns_client: BaseClient, topic_arn: str, subject:str, message: str) -> None:Elsewhere, I’ve added the BaseClient annotation to get_parameter_from_ssm‘s ssm_client parameter:
def get_parameter_from_ssm(ssm_client: BaseClient, parameter_name: str) -> str:And put_s3_object‘s s3_client parameter:
def put_s3_object(s3_client: BaseClient, bucket: str, prefix:str, name: str, json_data: str, suffix: str) -> bool:put_s3_object also has new prefix and suffix parameters. Before this, it was hard-coded to create JSON objects in a wordpress-api S3 prefix:
try:
logging.info(f"Attempting to put {name} data in {bucket} bucket...")
s3_client.put_object(
Body = json_data,
Bucket = bucket,
Key = f"wordpress-api/{name}.json"
)Not any more! The S3 prefix and object suffix can now be changed dynamically:
try:
logging.info(f"Attempting to put {name} data in {bucket} bucket's {prefix}/{name} prefix...")
s3_client.put_object(
Body = json_data,
Bucket = bucket,
Key = f"{prefix}/{name}/{name}.{suffix}"
)This improves put_s3_object‘s reusability as I can now pass any prefix and suffix to it during a function call. For example, this call creates a JSON object:
ok = put_s3_object(client_s3, s3_bucket, data_source, object_name, api_json_string, 'json')While this creates a CSV object:
ok = put_s3_object(client_s3, s3_bucket, data_source, object_name, api_json_string, 'csv')Likewise, this creates a TXT object:
ok = put_s3_object(client_s3, s3_bucket, data_source, object_name, api_json_string, 'txt')I can also set data_source (which I’ll cover shortly) to any S3 prefix, giving total control over where the object is stored.
Updated Variables
Next, some of my variables need to change. My SNS parameter name needs updating from:
# AWS Parameter Store Names
parametername_s3bucket = '/s3/lakehouse/name/raw'
parametername_snstopic = '/sns/pipeline/wordpressapi/raw'
parametername_wordpressapi = '/wordpress/amazonwebshark/api/mysqlendpoints'To:
# AWS Parameter Store Names
parametername_s3bucket = '/s3/lakehouse/name/raw'
parametername_snstopic = '/sns/data/lakehouse/raw'
parametername_wordpressapi = '/wordpress/amazonwebshark/api/mysqlendpoints'I also need to lay the groundwork for put_s3_object‘s new prefix parameter. I used to have a lambdaname variable that was used in the logs:
# Lambda name for messages
lambdaname = 'data_wordpressapi_raw'I’ve replaced this with two new variables. data_source records the data’s origin, which matches my S3 prefix naming schema. function_name then adds context to data_source to match my Lambda function naming schema:
# Lambda name for messages
data_source = 'wordpress_api'
function_name = f'data_{data_source}_raw'data_source is then passed to the put_s3_object function call when creating raw objects:
ok = put_s3_object(client_s3, s3_bucket, data_source, object_name, api_json_string)While function_name is used in the logs when referring to the Lambda function:
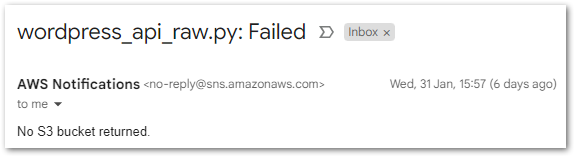
# Check an S3 bucket has been returned.
if not s3_bucket_raw:
message = f"{function_name}: No S3 Raw bucket returned."
subject = f"{function_name}: Failed"Updated Script Body
My variables all now have type annotations. They’ve gone from:
# AWS Parameter Store Names
parametername_s3bucket = '/s3/lakehouse/name/raw'
parametername_snstopic = '/sns/data/lakehouse/raw'
parametername_wordpressapi = '/wordpress/amazonwebshark/api/mysqlendpoints'
# Lambda name for messages
data_source = 'wordpress_api'
function_name = f'data_{data_source}_raw'
# Counters
api_call_timeout = 30
endpoint_count_all = 0
endpoint_count_failure = 0
endpoint_count_success = 0To:
# AWS Parameter Store Names
parametername_s3bucket: str = '/s3/lakehouse/name/raw'
parametername_snstopic: str = '/sns/data/lakehouse/raw'
parametername_wordpressapi: str = '/wordpress/amazonwebshark/api/mysqlendpoints'
# Lambda name for messages
data_source: str = 'wordpress_api'
function_name: str = f'data_{data_source}_raw'
# Counters
api_call_timeout: int = 30
endpoint_count_all: int = 0
endpoint_count_failure: int = 0
endpoint_count_success: int = 0This is helpful when the variables are passed in from settings files or external services and are not immediately apparent. So a good habit to get into!
Bronze Script
Now let’s talk about the new script, which transforms raw S3 JSON objects into bronze S3 Parquet objects. Both raw and bronze WordPress scripts will then feed into an AWS orchestration workflow.
Reused Raw Functions
The following functions are re-used from the Raw script with no changes:
Get Filename Function
Here, I want to get each S3 path’s object name. The object name has some important uses:
- Using it instead of the full S3 path makes the logs easier to read and cheaper to store.
- Using it during bronze S3 object creation ensures consistent naming.
A typical S3 path has the schema s3://, from which I want bucket/prefix/object.suffixobject.
This function is a remake of the raw script’s Get Filename function. This time, the source string is an S3 path instead of an API endpoint:
I define a get_objectname_from_s3_path function, which expects a path argument with a string type hint and returns a new string.
Firstly, my name_full variable uses the rsplit method to capture the substring I need, using forward slashes as separators. This converts s3:// to bucket/prefix/object.suffixobject.suffix.
Next, my name_full_last_period_index variable uses the rfind method to find the last occurrence of the period character in the name_full string.
Finally, my name_partial variable uses slicing to extract a substring from the beginning of the name_full string up to (but not including) the index specified by name_full_last_period_index. This converts object.suffix to object.
If the function cannot return a string, an exception is logged and a blank string is returned instead.
Get Data Function
Next, I want to read data from an S3 JSON object in my Raw bucket and store it in a pandas DataFrame.
Here, I define a get_data_from_s3_object function that returns a pandas DataFrame and expects three arguments:
boto3_session: the authenticated session to use with aBaseClienttype hint.s3_object: the S3 object path with a string type hint.name: the S3 object name with a string type hint (used for logging).
This function uses AWS SDK For pandas s3.read_json to read the data from the S3 object path using the existing boto3_session authentication.
If data is found then get_data_from_s3_object returns a populated DataFrame. Otherwise, an empty DataFrame is returned instead.
Put Data Function
Finally, I want to convert the DataFrame to Parquet and store it in my bronze S3 bucket.
I define a put_s3_parquet_object function that expects four arguments:
df: the pandas DataFrame containing the raw data.name: the S3 object name.s3_object_bronze: the S3 path for the new bronze objectsession: the authenticated boto3 session to use.
I give string type hints to the name and s3_object_bronze parameters. session gets the same BaseClient hint as before, and df is identified as a pandas DataFrame.
I open a try except block that uses s3.to_parquet with the existing boto3_session to upload the DataFrame data to S3 as a Parquet object. If this operation succeeds, the function returns True. If it fails, a botocore exception is logged and the function returns False.
Imports & Variables
The bronze script has two new imports to examine: awswrangler and pandas:
import logging
import boto3
import botocore
import awswrangler as wr
import pandas as pd
from botocore.client import BaseClientI’ve used both before. Here, pandas handles my in-memory data storage and awswrangler handles my S3 interactions.
There are also parameter changes. I’ve added Parameter Store names for both the bronze S3 bucket and the SNS topic. I’ve kept the raw S3 bucket parameter as awswrangler needs it for the get_data_from_s3_object function.
parametername_s3bucket_raw: str = '/s3/lakehouse/name/raw'
parametername_s3bucket_bronze: str = '/s3/lakehouse/name/bronze'
parametername_snstopic: str = '/sns/data/lakehouse/bronze'I’ve also swapped out _raw for _bronze in function_name, and renamed the counters from endpoint_count to object_count to reflect their new function:
# Lambda name for messages
data_source: str = 'wordpress_api'
function_name: str = f'data_{data_source}_bronze'
# Counters
object_count_all: int = 0
object_count_failure: int = 0
object_count_success: int = 0Script Body
Most of the bronze script is reused from the raw script. Tasks like logging config, name parsing and validation checks only needed the updated parameters! There are some changes though, as S3 is now my data source and I’m also doing additional tasks.
Firstly, I need to get the raw S3 objects. The AWS SDK For pandas S3 class has a list_objects function which is purpose-built for this:
s3_objects_raw = wr.s3.list_objects(
path = f's3://{s3_bucket_raw}/{data_source}',
suffix = 'json',
boto3_session = session)pathis the S3 location to list – in this case the raw S3 bucket’swordpress_apiprefix.suffixfilters the list by the specified suffix.boto3_sessionspecifies my existingboto3_sessionto prevent unnecessary re-authentication.
During the loop, my script checks if the pandas DataFrame returned from get_data_from_s3_object contains data. If it’s empty then the loop ends, otherwise the column and row counts are logged:
if df.empty:
logging.warning(f"{object_name} DataFrame is empty!")
endpoint_count_failure += 1
continue
logging.info(f'{object_name} DataFrame has {len(df.columns)} columns and {len(df)} rows.')Assuming all checks succeed, I want to put a new Parquet object into my bronze S3 bucket. AWS SDK For pandas has an s3.to_parquet function that does this using a pandas DataFrame and an S3 path.
I already have the DataFrame so let’s make the path. This is done by the s3_object_bronze parameter, which joins existing parameters with additional characters. This is then passed to put_s3_parquet_object:
s3_object_bronze = f's3://{s3_bucket_bronze}/{data_source}/{object_name}/{object_name}.parquet'
logging.info(f"Attempting {object_name} S3 Bronze upload...")
ok = put_s3_parquet_object(df, object_name, s3_object_bronze, session)That’s the bronze script done. Now to deploy it to AWS Lambda.
Lambda
In this section, I configure and deploy my Bronze Lambda function.
Hitting Size Limits
So, remember when I said that I expected my future Lambda deployments to improve? Well, this was the result of my retrying the virtual environment deployment process the Raw Lambda used:
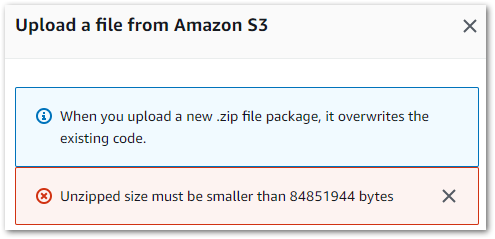
While my zipped raw function is 19.1 MB, my zipped bronze function is over five times bigger at 101.6 MB! My poorly optimised package wouldn’t cut it this time, so I prepared for some pruning. Until I discovered something…
Using A Layer
There’s a managed AWS SDK for pandas Lambda layer!
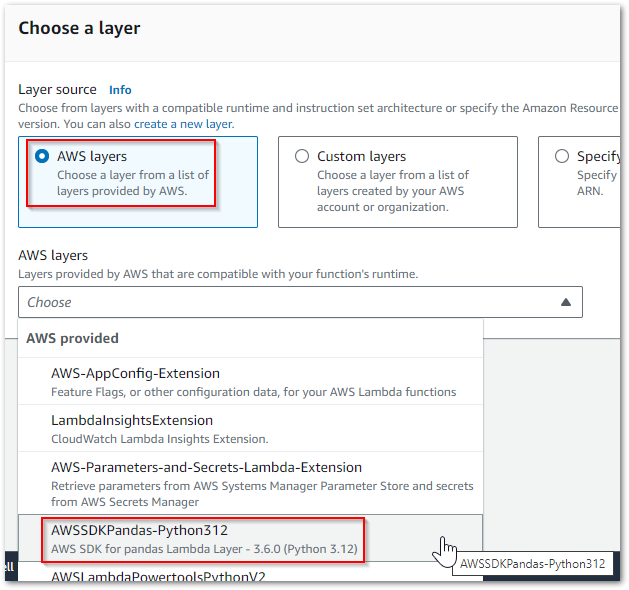
It can be selected in the Lambda console or programmatically called from this list of AWS SDK for pandas Managed Layer ARNs, which covers:
- All AWS commercial regions.
- All Python versions currently supported by Lambda (currently 3.8+)
- Both Lambda architectures.
Additionally, the Lambda Python 3.12 runtime includes boto3 and botocore. So by using this runtime and the managed layer, I’ve gone from a large deployment package to no deployment package! And because my function is now basically just code, I can view and edit that code in the Lambda console directly.
Lambda Config
My Bronze Lambda function borrows several config settings from the raw one, including:
- A Lambda Destination using the
failure-lambdaSNS topic. - Same Timeout and Memory values.
- Same logging setup.
Where it differs is the IAM setup. I needed additional permissions anyway because this function is reading from two S3 buckets now, but by the time I was done the policy was hard to read, maintain and troubleshoot:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"sns:Publish",
"s3:ListBucket",
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:s3:::data-lakehouse-raw/wordpress_api/*",
"arn:aws:s3:::data-lakehouse-bronze/wordpress_api/*",
"arn:aws:s3:::data-lakehouse-raw",
"arn:aws:s3:::data-lakehouse-bronze",
"arn:aws:logs:eu-west-1:REDACTED:*",
"arn:aws:sns:eu-west-1:REDACTED:data-lakehouse-raw",
"arn:aws:sns:eu-west-1:REDACTED:data-lakehouse-bronze"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents",
"ssm:GetParameter"
],
"Resource": [
"arn:aws:logs:eu-west-1:REDACTED:log-group:/aws/lambda/data_wordpressapi_bronze:*",
"arn:aws:ssm:eu-west-1:REDACTED:parameter/s3/lakehouse/name/raw",
"arn:aws:ssm:eu-west-1:REDACTED:parameter/s3/lakehouse/name/bronze",
"arn:aws:ssm:eu-west-1:REDACTED:parameter/sns/data/lakehouse/raw",
"arn:aws:ssm:eu-west-1:REDACTED:parameter/sns/data/lakehouse/bronze"
]
}
]
}So let’s refactor it! The below policy has the same actions, grouped by service and with appropriately named Sids:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "CloudWatchLogGroupActions",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:logs:eu-west-1:REDACTED:*"
]
},
{
"Sid": "CloudWatchLogStreamActions",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:eu-west-1:REDACTED:log-group:/aws/lambda/data_wordpressapi_bronze:*"
]
},
{
"Sid": "S3BucketActions",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::data-lakehouse-raw",
"arn:aws:s3:::data-lakehouse-bronze"
]
},
{
"Sid": "S3ObjectActions",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::data-lakehouse-raw/wordpress_api/*",
"arn:aws:s3:::data-lakehouse-bronze/wordpress_api/*"
]
},
{
"Sid": "SNSActions",
"Effect": "Allow",
"Action": [
"sns:Publish"
],
"Resource": [
"arn:aws:sns:eu-west-1:REDACTED:data-lakehouse-bronze"
]
},
{
"Sid": "ParameterStoreActions",
"Effect": "Allow",
"Action": [
"ssm:GetParameter"
],
"Resource": [
"arn:aws:ssm:eu-west-1:REDACTED:parameter/s3/lakehouse/name/raw",
"arn:aws:ssm:eu-west-1:REDACTED:parameter/s3/lakehouse/name/bronze",
"arn:aws:ssm:eu-west-1:REDACTED:parameter/sns/data/lakehouse/bronze"
]
}
]
}Much better! This policy is now far easier to read and update.
There’s also a clear distinction between the bucket-level s3:ListBucket operation and the object-level s3:PutObject and s3:GetObject operations now. Getting these wrong can have big consequences, so the clearer the better!
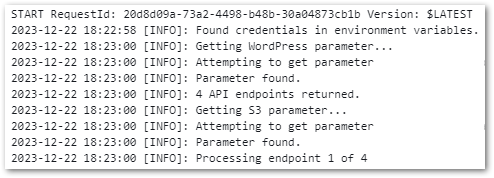
One deployment and test later, and I have some new S3 objects!
[INFO]: WordPress API Bronze process complete: 5 Successful | 0 Failed.
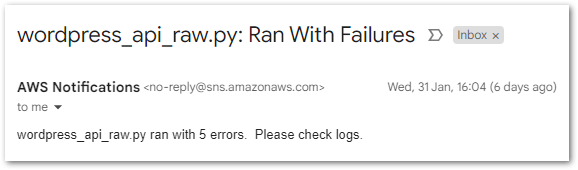
REPORT RequestId: 899d1658-f7de-4e74-8d64-b4f029fe2bec Duration: 7108.50 ms Billed Duration: 7109 ms Memory Size: 250 MB Max Memory Used: 250 MB Init Duration: 4747.38 msSo now I have two Lambda functions with some requirements around them:
- They need to run sequentially.
- The Raw Lambda must finish before the Bronze Lambda starts.
- If the Raw Lambda fails then the Bronze Lambda shouldn’t run at all.
Now that AWS Lambda is creating WordPress raw and bronze objects, it’s time to start thinking about orchestration!
Step Functions & EventBridge
In this section, I create both an AWS Step Functions State Machine and an Amazon EventBridge Schedule for my WordPress bronze orchestration process.
State Machine Requirements
Before writing any code, let’s outline the steps I need the state machine to perform:
data_wordpressapi_rawLambda function is invoked. If it succeeds then move to the next step. If it fails then send a notification and end the workflow reporting failure.data_wordpressapi_bronzeLambda function is invoked. If it succeeds then end the workflow reporting success. If it fails then send a notification and end the workflow reporting failure.
With the states defined, it’s time to create the state machine.
State Machine Creation
The following state machine was created using Step Functions Workflow Studio – a low-code visual designer released in 2021, with drag-and-drop functionality that auto-generates code in real-time:
Workflow Studio produced this section’s code and diagrams.
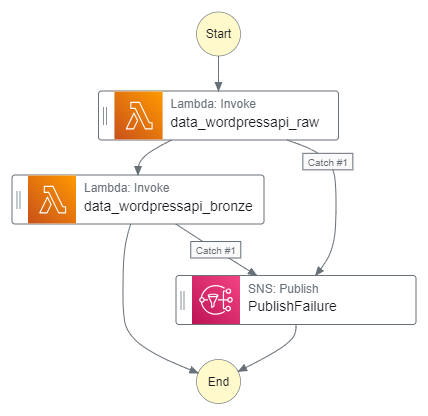
Firstly I create a data_wordpressapi_raw task state to invoke my Raw Lambda. This task uses the lambda:invoke action to invoke my data_wordpressapi_raw function. I set the next state as data_wordpressapi_bronze and add a Catch block that sends all errors to a PublishFailure state (which I’ll define later):
"data_wordpressapi_raw": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:eu-west-1:REDACTED:function:data_wordpressapi_raw:$LATEST"
},
"Next": "data_wordpressapi_bronze",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.Error",
"Next": "PublishFailure"
}
],
"TimeoutSeconds": 120
}Note the TimeoutSeconds parameter. All my task states will have 120-second timeouts. These stop the state machine from waiting indefinitely if the task becomes unresponsive, and are recommended best practice. Also note that state machines wait for Lambda invocations to finish by default, so no additional config is needed for this.
Next, I create a data_wordpressapi_bronze task state to invoke my Bronze Lambda. This task uses the lambda:invoke action to invoke my data_wordpressapi_bronze function. I then add a Catch block that sends all errors to a PublishFailure state.
Finally, "End": true designates this state as a terminal state which ends the execution if the task is successful:
"data_wordpressapi_bronze": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:eu-west-1:973122011240:function:data_wordpressapi_bronze:$LATEST"
},
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.Error",
"Next": "PublishFailure"
}
],
"TimeoutSeconds": 120,
"End": true
}Finally, I create a PublishFailure task state that publishes failure notifications. This task uses the sns:Publish action to publish a simple message to the failure-stepfunction SNS Topic ARN. "End": true marks this task as the other potential way the state machine execution can end:
"PublishFailure": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "arn:aws:sns:eu-west-1:REDACTED:failure-stepfunction",
"Message": "An error occurred in the state machine: { \"error\": \"$.Error\" }"
},
"End": true,
"TimeoutSeconds": 120
}While both Lambdas already have SNS alerting, the state machine itself may also fail so the added observability is justified. This Marcia Villalba video was very helpful here:
And that’s everything I need! At this point Wordflow Studio gives me two things – firstly the state machine’s code, which I’ve committed to GitHub. And secondly this handy downloadable diagram:
State Machine Config
It’s now time to think about security and monitoring.
When new state machines are created in the AWS Step Functions console, an IAM Role is created with policies based on the state machine’s resources. The nuances and templates are covered in the Step Functions Developer Guide, so let’s examine my WordPress_Raw_To_Bronze state machine’s auto-generated IAM Role consisting of two policies:
- Firstly, a Lambda IAM policy allowing the
lambda:InvokeFunctionaction on all Lambdas listed in the state machine. - Secondly, an X-Ray IAM policy allowing AWS Step Functions to call the AWS X-Ray daemon for X-Ray tracing:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"xray:PutTraceSegments",
"xray:PutTelemetryRecords",
"xray:GetSamplingRules",
"xray:GetSamplingTargets"
],
"Resource": [
"*"
]
}
]
}This supports the AWS X-Ray integration with AWS Step Functions. If X-Ray trancing is never enabled then this policy is unused.
Besides X-Ray tracing, there is also an option to log a state machine’s execution history to CloudWatch Logs. There are three log levels available plus a fourth default choice: OFF. Each state machine retains recent execution history and I’ve got no need to keep that history long-term, so I leave the log retention disabled. Remember – CloudWatch Logs is only free for the first 5GB!
State Machine Testing
There are various ways to test a state machine. There’s a testing and debugging section in the developer guide that goes into further details, the three main options being:
I’ll focus on console testing here.
Both individual states and the entire state machine can be tested in the console. Each state can be tested in isolation (using the TestState API under the hood) with customisable inputs and IAM roles. This is great for checking the state outputs are correct, and that the attached IAM role is sufficient.
The state machine itself can also be tested via on-demand execution. The Execution Details page shows the state machine’s statistics and events, and has great coverage in the developer guide.
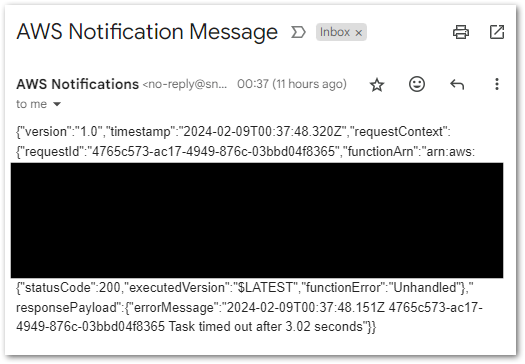
During testing, my WordPress_Raw_To_Bronze state machine returned this error:
States.Runtime in step: data_wordpressapi_bronze.
An error occurred while executing the state 'data_wordpressapi_bronze' (entered at the event id #7). Unable to apply Path transformation to null or empty input.This turned out to be a problem with the OutputPath parameter, which Wordflow Studio enables by default:
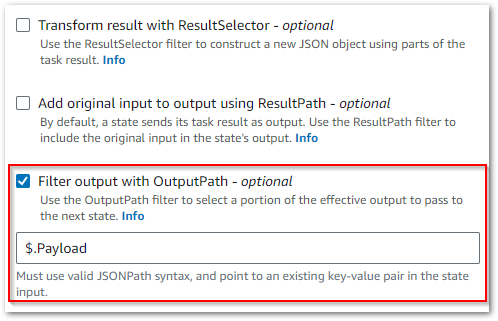
I’m not using this setting for anything, so I disabled it to solve this problem.
Eventbridge Schedule
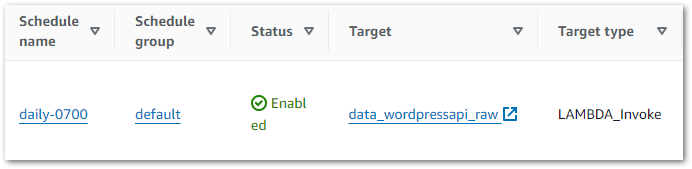
Finally, I want to automate the execution of my state machine. This calls for an EventBridge Schedule!
EventBridge makes this quite simple, using mostly the same process as last time. The Step Functions StartExecution operation is a templated target like Lambda’s Invoke operation, so it’s a case of selecting the WordPress_Raw_To_Bronze state machine from the list and updating the schedule’s IAM role accordingly.
And that’s it! EventBridge now executes the state machine at 07:00 each morning. The state machine then sequentially invokes both Lambda functions and catches any errors.
Costs
In this section, I’ll examine my recent AWS WordPress bronze orchestration process costs.
Let’s start with Step Functions. There are two kinds of Step Function workflow:
- Standard workflows are charged based on the number of state transitions. These are counted each time a workflow step is executed. The first 4000 transitions each month are free. After that, every 1000 transitions cost $0.025.
- Express workflows are priced by the number of executions, duration, and memory consumption. The specifics of these criteria, coupled with full details of all charges are on the Step Functions pricing page.
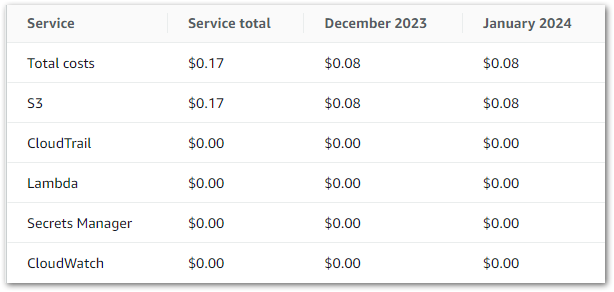
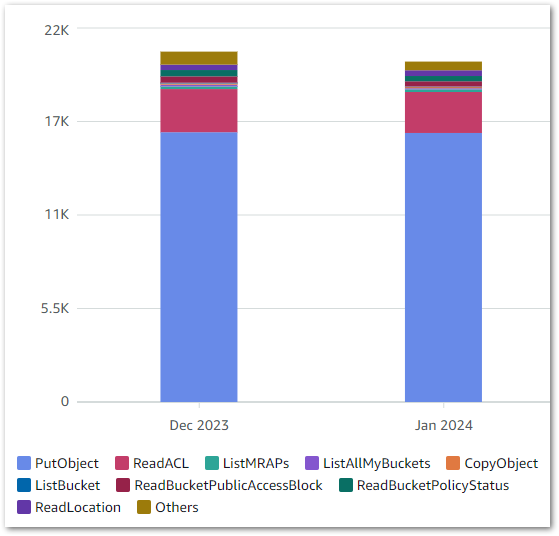
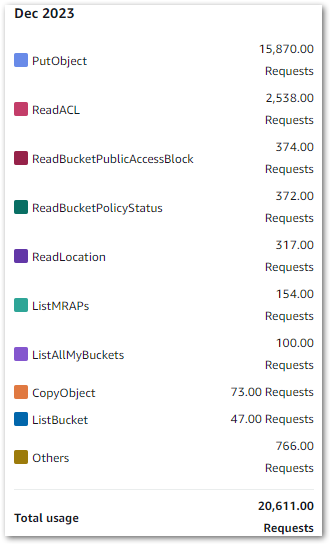
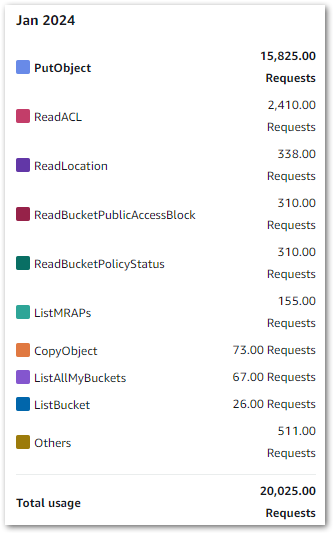
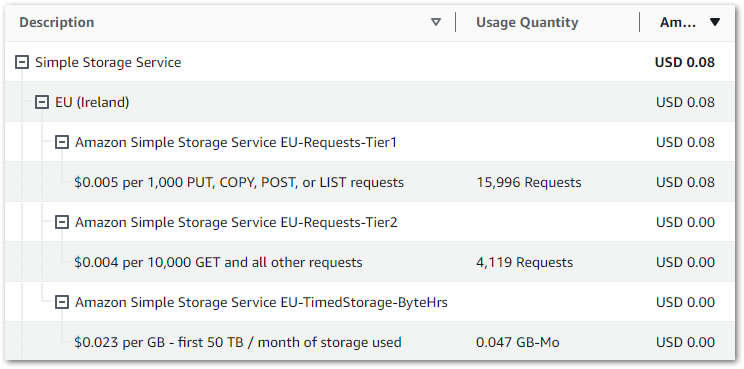
I’m using standard workflows, and as of 26 March I’ve used 118 state transitions. In other words, free! Elsewhere, my costs are broadly on par with previous months. These are my S3 costs from 2024-02-01 to 2024-03-26:
| S3 Actions | Month | Usage | Cost |
| PUT, COPY, POST, or LIST requests | 2024-02 | 64,196 | 0.32 |
| PUT, COPY, POST, or LIST requests | 2024-03 | 17,566 | 0.09 |
| GET and all other requests | 2024-02 | 101,462 | 0.04 |
| GET and all other requests | 2024-03 | 8,656 | 0.00 |
| GB month of storage used | 2024-02 | 0.109 | 0.00 |
| GB month of storage used | 2024-03 | 0.161 | 0.00 |
And this is my recent free tier usage from 2024-02-01 to 2024-03-26:
| Service | Month | Usage |
| EventBridge | 2024-02 | 31 Invocations |
| EventBridge | 2024-03 | 25 Invocations |
| Lambda | 2024-02 | 122.563 Second Compute |
| Lambda | 2024-02 | 84 Requests |
| Lambda | 2024-03 | 82.376 Second Compute |
| Lambda | 2024-03 | 58 Requests |
| Parameter Store | 2024-02 | 34 API Requests |
| Parameter Store | 2024-03 | 25 API Requests |
| SNS | 2024-02 | 8 Email-JSON Notifications |
| SNS | 2024-02 | 438 API Requests |
| SNS | 2024-03 | 3 Email-JSON Notifications |
| SNS | 2024-03 | 205 API Requests |
So my only costs are still for storage.
Resources
The following items have been checked into the amazonwebshark GitHub repo for the AWS WordPress bronze orchestration process, available via the button below:
- Updated
data_wordpressapi_rawPython script &requirements.txtfile. - New
data_wordpressapi_bronzePython script &requirements.txtfile. WordPress_Raw_To_Bronzestate machine JSON.

Summary
In this post, I created my WordPress pipeline’s bronze data orchestration process using AWS Lambda layers and AWS Step Functions.
I’ve wanted to try Step Functions out for a while, and all things considered they’re great! Workflow Studio is easy to use, and the templates and tutorials undoubtedly highlight the value that Step Functions can bring.
Additionally, the integration with both EventBridge Scheduler and other AWS services makes Step Functions a compelling orchestration service for both my ongoing WordPress bronze work and the future projects in my pipeline. This combined with some extra Lambda layers will reduce my future dev and test time.
If this post has been useful then the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~