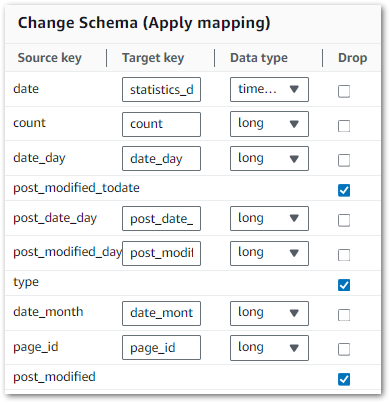
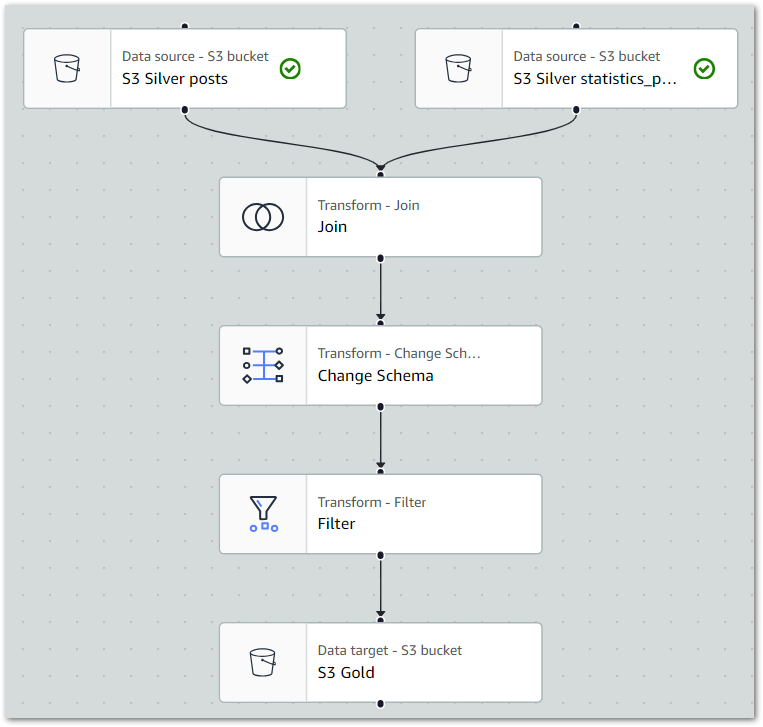
In this post, I use JSONata to add low-code S3 object key validation to an AWS Step Functions state machine.
Table of Contents
- Introduction
- JSONata & AWS
- Architecture
- Expression Creation
- Testing
- Summary
Introduction
In 2024, I worked a lot with AWS Step Functions. I built several for different tasks, wrote multiple blog posts about them and talked about them a fair bit. So when AWS introduced JSONata support for Step Functions last year, I was very interested. Although I had no prior JSONata experience, I heard positive feedback and made a mental note to explore its use cases.
Well, there’s no time like the present! And as I was starting to create the first Project Wolfie resources I realised some of my requirements were a perfect fit.
Firstly, I will examine what JSONata is, how it works and why it’s useful. Next, I will outline my architecture and create some low-code S3 key validation JSONata expressions. Finally, I’ll test these expressions and review their outputs.
JSONata & AWS
This section introduces JSONata and examines its syntax and benefits.
Introducing JSONata
JSONata is a lightweight query and transformation language for JSON, developed by Andrew Coleman in 2016. Specifically inspired by XPath and SQL, it enables sophisticated queries using a compact and intuitive notation.
JSONata provides built-in operators and functions for efficiently extracting and transforming data into any JSON structure. It also supports user-defined functions, allowing for advanced expressions that enhance the querying of dynamic JSON data.
For a visual introduction, check out this JSONata overview:
JSONata Syntax Essentials
JSONata has a simple and expressive syntax. Its path-based approach lets developers easily navigate nested structures. It combines functional programming with dot notation for navigation, brackets for filtering and pipeline operators for chaining.
JSONata operations include transformations like:
- Arithmetic (
$price * 1.2) - Conditional Logic (
$price > 100 ? 'expensive' : 'affordable'). - Filtering (
$orders[status = 'shipped']) - String Operations (
$firstName & ' ' & $lastName)
The JSONata site includes full documentation and a JSONata Exerciser for experimenting.
JSONata In AWS Step Functions
JSONata was introduced to AWS Step Functions in November 2024. Using JSONata in Step Functions requires setting the QueryLanguage field to JSONata in the state machine definition. This action replaces the traditional JSONPath fields with two JSONata fields:
Arguments: Used to customise data sent to state actions.Output: Used to transform results into custom state output.
Additionally, the Assign field sets variables that can be stored and reused across the workflow.
In AWS Step Functions, JSONata expressions are enclosed in {% %} delimiters but otherwise follow standard JSONata syntax. They access data using the $states reserved variable with the following structures:
- State input is accessed using
$states.input - Context information is accessed using
$states.context - Task results (if successful) are accessed using
$states.result - Error outputs (if existing) are accessed using
$states.errorOutput
Step Functions includes standard JSONata functions as well as AWS-specific additions like $partition, $range, $hash, $random, and $uuid. Some functions, such as $eval, are not supported.
Here are some JSONata examples from the AWS Step Functions Developer Guide:
{% $states.input.title %}
{% $current_price <= $states.input.desired_priced %}
{% $parse($states.input.json_string) %}Talking more about this subject is AWS Principle Developer Advocate Eric Johnson:
JSONata Benefits
So why is JSONata in AWS a big deal?
Low Maintenance: JSONata use removes the need for Lambda runtime updates, dependency management and security patching. JSONata expressions are self-contained and version-free, reducing debugging and testing effort.
Simpler Development Workflow: JSONata’s standardised syntax removes decisions about languages, runtimes and tooling. This improves consistency, simplifies collaboration and speeds up development.
Releases Capacity: JSONata use reduces reliance on AWS Lambda, freeing up Lambda concurrency slots for more complex tasks. This minimises throttling risks and can lower Lambda costs.
Faster Execution: JSONata runs inside AWS services, avoiding cold starts, IAM role checks and network latency. Most JSONata transformations are complete in milliseconds, making it ideal for high-throughput APIs and real-time systems.
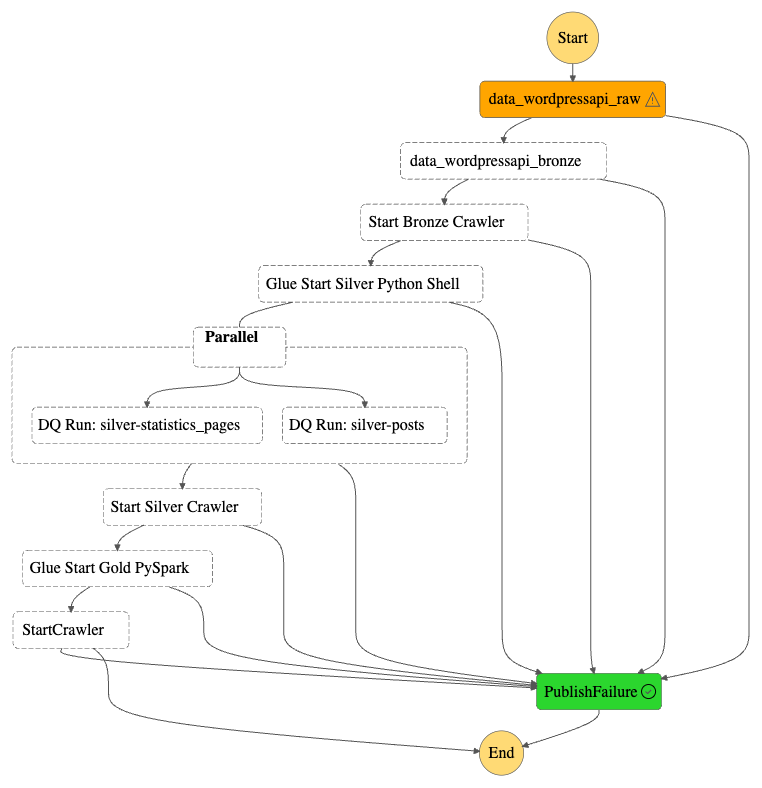
Architecture
This section explains the key features and events used in my low-code S3 validation architecture with JSONata.
Object Created Event
My process starts when an S3 object is created. For this post, I’m using Amazon EventBridge‘s sample S3 Object Created event:
{
"version": "0",
"id": "17793124-05d4-b198-2fde-7ededc63b103",
"detail-type": "Object Created",
"source": "aws.s3",
"account": "123456789012",
"time": "2021-11-12T00:00:00Z",
"region": "ca-central-1",
"resources": ["arn:aws:s3:::example-bucket"],
"detail": {
"version": "0",
"bucket": {
"name": "example-bucket"
},
"object": {
"key": "example-key",
"size": 5,
"etag": "b1946ac92492d2347c6235b4d2611184",
"version-id": "IYV3p45BT0ac8hjHg1houSdS1a.Mro8e",
"sequencer": "00617F08299329D189"
},
"request-id": "N4N7GDK58NMKJ12R",
"requester": "123456789012",
"source-ip-address": "1.2.3.4",
"reason": "PutObject"
}
}Here, the highlighted key field is vital as it identifies the uploaded object. This field will be used in the validation processes.
Choice State
In AWS Step Functions, Choice states introduce conditional logic to a state machine. They assess conditions and guide execution accordingly, allowing workflows to branch dynamically based on input data. When used with JSONata, a Choice state must contain the following fields:
Conditionfield – a JSONata expression that evaluates totrue/false.Nextfield – a value that must match a state name in the state machine.
For example, this Choice state checks if a variable foo equals 1:
{"Condition": "{% $foo = 1 %}", "Next": "NumericMatchState"}If $foo = 1, the condition is true and the workflow transitions to a NumericMatchState state.
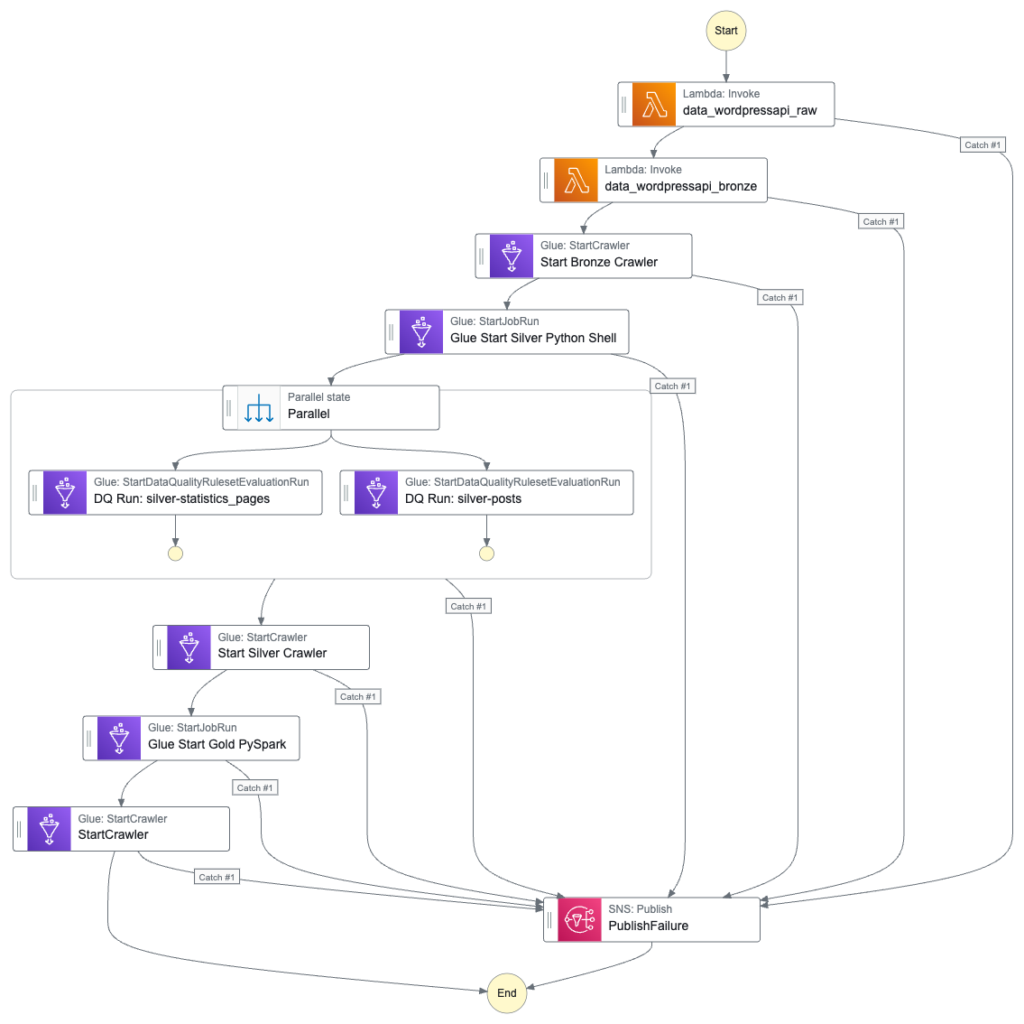
Architecture Diagram
Now let’s put this all together into an architecture diagram:
Here,
- A file is uploaded to an Amazon S3 Bucket.
- S3 creates an Object Created event.
- Amazon EventBridge matches the event record to an event rule.
- Eventbridge executes the AWS Step Functions state machine and passes the event to it as JSON input.
- The state machine transitions through the various choice states.
- The state machine transitions to the fail state if any choice state criteria are not met.
- The state machine transitions to the success state if all choice state criteria are met.
Expression Creation
In this section, I create JSONata expressions to perform low-code S3 validation. For clarity, I’ll use this sample S3 event including an object key which closely resembles my actual S3 path:
{
"version": "0",
...
"detail": {
"version": "0",
"bucket": {
"name": "data-lakehouse-raw"
},
"object": {
"key": "iTunes/iTunes-AllTunes-2025-02-01.txt",
"size": 5,
...
},
"request-id": "N4N7GDK58NMKJ12R",
"requester": "123456789012",
"source-ip-address": "1.2.3.4",
"reason": "PutObject"
}
}S3 Key TXT Suffix Check
This JSONata expression checks if the S3 object key ends with txt:
{% $lowercase($split($split($states.input.detail.object.key, '/')[-1], '.')[-1]) = 'txt' %}For better readability:
{%
$lowercase(
$split(
$split($states.input.detail.object.key, '/')[-1],
'.')[-1]
) = 'txt'
%}Let’s walk through this step by step:
1. Accessing The S3 Object Key
Extract the key from the event using $states.input:
$states.input.detail.object.key➡ Output: "iTunes/iTunes-AllTunes-2025-02-01.txt"
2. Splitting By / To Extract The Filename
Break the key into an array with %split using / as the delimiter:
$split($states.input.detail.object.key, '/')➡ Output: ["iTunes", "iTunes-AllTunes-2025-02-01.txt"]
Now, retrieve the array’s last element (the object name) using [-1]:
$split(...)[-1]➡ Output: "iTunes-AllTunes-2025-02-01.txt"
3. Splitting By . To Extract The File Suffix
Break the filename with $split again, using . as the delimiter:
$split($split(...)[-1], '.')➡ Output: ["iTunes-AllTunes-2025-02-01", "txt"]
Now, retrieve the last element (the suffix) using [-1]:
$split($split(...)[-1], '.')[-1]➡ Output: "txt"
4. Converting To Lowercase For Case-Insensitive Matching
Use $lowercase to convert the suffix to lowercase:
$lowercase($split(...)[-1], '.')[-1])➡ Output: "txt"
The $lowercase function ensures consistency, as files with TXT, Txt, or tXt extensions will still match correctly. Here, there is no change as txt is already lowercase.
5. Comparing Against 'txt'
Finally, compare the result to 'txt':
$lowercase($split(...)[-1], '.')[-1]) = 'txt'➡ Output: true ✅
This means that files ending in .txt pass validation, while others fail.
S3 Key iTunes String Check
This JSONata expression checks if the S3 object key contains iTunes.
{% $contains($split($states.input.detail.object.key, '/')[-1], 'iTunes') %}For better readability:
{%
$contains(
$split(
$states.input.detail.object.key, '/')[-1],
'iTunes'
)
%}I’m not using $lowercase this time, as iTunes is the correct spelling.
1. Extract The Filename
This is unchanged from the last expression:
$split($states.input.detail.object.key, '/')[-1]➡ Output: "iTunes-AllTunes-2025-02-01.txt"
2. Check If The String Contains 'iTunes'
The $contains function checks if the string contains the specified substring. It returns true if the substring exists; otherwise, it returns false.
$contains($split(...)[-1], 'iTunes')➡ Output: true ✅ if 'iTunes' appears anywhere in the filename.
So:
- ✅
"iTunes-AllTunes-2025-02-01.txt"→true - ❌
"itunes-AllTunes-2025-02-01.txt"→false(case-sensitive)
S3 Key Date Check
This JSONata expression checks if the S3 object key contains a date with format YYYY-MM-DD.
{% $exists($match($split($states.input.detail.object.key, '/')[-1], /\d{4}-\d{2}-\d{2}/)) %}For better readability:
$exists(
$match(
$split($states.input.detail.object.key, '/')[-1],
/\d{4}-\d{2}-\d{2}/
)
)1. Extract The Filename
This is unchanged from the first expression:
$split($states.input.detail.object.key, '/')[-1]➡ Output: "iTunes-AllTunes-2025-02-01.txt"
2. Apply The Regex Match
The $match function applies the substring to the provided regular expression (regex). If found, an array of objects is returned containing the following fields:
match– the substring that was matched by the regex.index– the offset (starting at zero) within the substring.groups– if the regex contains capturing groups (parentheses), this contains an array of strings representing each captured group.
In this JSONata expression:
$match(..., /\d{4}-\d{2}-\d{2}/)The regex looks for:
\d{4}→ Four digits (year)-→ Hyphen separator\d{2}→ Two digits (month)-→ Another hyphen\d{2}→ Two digits (day)
➡ Output:
{
"match": "2025-02-01",
"index": 16,
"groups": []
}3. Convert To Boolean With $exists
I can’t use the $match output yet as the Choice state needs a boolean output. Enter $exists. This function returns true for a successful match; otherwise, it returns false.
$exists($match(..., /\d{4}-\d{2}-\d{2}/))➡ Output: true ✅ if a date is found.
Here, $exists returns true as a date is present. However, note that JSONata lacks built-in functions to validate dates. For example:
"2025-02-01"→true(valid date)"2025-02-31"→true(invalid date but still matches format)
An AWS Lambda function would be needed for strict date validation.
Combining JSONata Expressions
Although I’ve created separate Choice states for each JSONata expression in this section, I will add that all the expressions can be combined into a single Choice state using and:
{% $lowercase($split($split($states.input.detail.object.key, '/')[-1], '.')[-1]) = 'txt' and $contains($split($states.input.detail.object.key, '/')[-1], 'iTunes') and $exists($match($split($states.input.detail.object.key, '/')[-1], /\\d{4}-\\d{2}-\\d{2}/)) %}For better readability:
{%
$lowercase(
$split(
$split(
$states.input.detail.object.key, '/')[-1], '.')[-1]) = 'txt'
and
$contains(
$split(
$states.input.detail.object.key, '/')[-1], 'iTunes')
and
$exists(
$match(
$split(
$states.input.detail.object.key, '/')[-1], /\\d{4}-\\d{2}-\\d{2}/))
%}When deciding whether to do this, consider these benefits:
- Simplified Structure: Reducing the number of states can make the state machine easier to understand and maintain visually. Instead of multiple branching paths, all logic is in one centralised
Choicestate.
- Cost Optimisation: AWS Step Functions Standard Workflows pricing is based on the number of state transitions. Combining multiple
Choicestates into one reduces transitions, potentially lowering costs for high-volume workflows.
- Minimises Transition Latency: Each state transition adds a slight delay. By managing all logic within a single Choice state, the workflow runs more efficiently due to the reduced transitions.
Against these tradeoffs:
- Added Complexity: A complex
Choicestate with many conditions can be difficult to read, debug, and modify. It may require deeply nested logic, which makes future updates challenging.
- Limited Observability: If multiple conditions are combined into one state, debugging failures becomes more difficult as it is unclear which condition caused an unexpected transition.
- Potential Scaling Difficulty: As the workflow evolves, adding more conditions to a single
Choicestate can become unmanageable. Ultimately, this situation may require breaking it up.
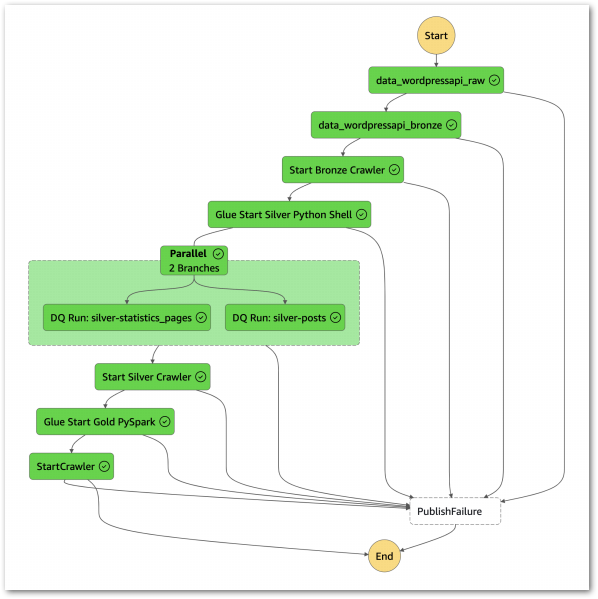
Final Workflows
Finally, let’s see what the workflows look like. Firstly, this workflow has separate Choice states for each JSONata expression:
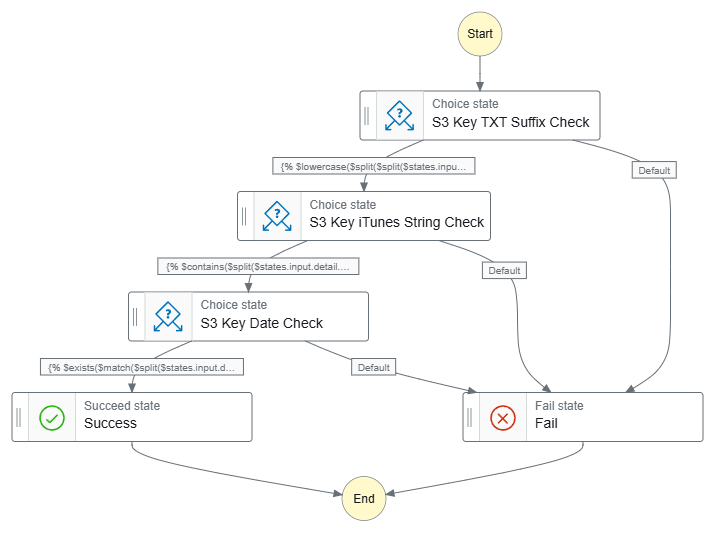
Data-Ingestion-iTunes ASL on GitHub.
Next, this workflow has one Choice state for all JSONata expressions:
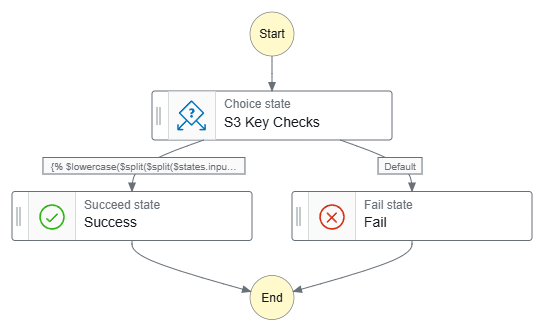
Data-Ingestion-iTunes-All ASL on GitHub.
Testing
To ensure my low-code JSONata expressions work as expected, I ran several tests against different S3 object keys. These tests validate:
- File Suffix (
.txt) - Key Content (
iTunes) - Date Format (
YYYY-MM-DD)
Suffix Validation Tests
| Test Case | S3 Key | Expected | Actual |
|---|---|---|---|
✅ Valid Suffix (.txt) | "iTunes/iTunes-2025-02-01.txt" | Proceed to iTunes Check | ✅ Success → Next: iTunes String Check |
❌ Invalid Suffix (.csv) | "iTunes/iTunes-2025-02-01.csv" | Fail (No further checks) | ❌ Failure → No further checks |
| ❌ Missing Suffix | "iTunes/iTunes-2025-02-01" | Fail (No further checks) | ❌ Failure → No further checks |
Key Content Validation Tests
| Test Case | S3 Key | Expected | Actual |
|---|---|---|---|
| ✅ Valid “iTunes” Key | "iTunes/iTunes-2025-02-01.txt" | Proceed to Date Check | ✅ Success → Next: Date Check |
❌ Incorrect Case (itunes instead of iTunes) | "iTunes/itunes-2025-02-01.txt" | Fail (No further checks) | ❌ Failure → No further checks |
| ❌ Missing Key String | "" | Fail (No further checks) | ❌ Failure → No further checks |
Date Format Validation Tests
| Test Case | S3 Key | Expected | Actual |
|---|---|---|---|
✅ Correct Date Format (YYYY-MM-DD) | "iTunes/iTunes-2025-02-01.txt" | Success (Validation complete) | ✅ Success → Validation complete! |
| ❌ Incorrect Date Format (Missing Day) | "iTunes/iTunes-2025-02.txt" | Fail (No further checks) | ❌ Failure → No further checks |
| ❌ Missing Date | "iTunes/iTunes.txt" | Fail (No further checks) | ❌ Failure → No further checks |
Edge Case: Impossible Date
| Test Case | S3 Key | Expected | Actual |
|---|---|---|---|
⚠️ Impossible Date (2025-02-31) | "iTunes/iTunes-2025-02-31.txt" | Fail (Ideally) | ❌ Unexpected Success (JSONata does not validate real-world dates) |
These tests confirm that JSONata expressions can effectively validate S3 object keys based on file suffixes, key contents and date formats. However, while JSONata can check formatting (YYYY-MM-DD) it does not validate real-world dates. If strict date validation is needed then an AWS Lambda function would be required.
Summary
In this post, I used JSONata to add low-code S3 object key validation to an AWS Step Functions state machine. This approach simplifies the validation process and reduces the reliance on more complex Lambda functions.
My first impressions of JSONata are very good! It’s already reduced both the number and size of Project Wolfie’s Lambda functions, and there’s still lots of JSONata to explore. In the meantime, these further videos by Eric Johnson explore more advanced JSONata Step Function applications:
If this post has been useful then the button below has links for contact, socials, projects and sessions:

Thanks for reading ~~^~~